



年末年始の行事や雑用が重なって前回から少し間が空いてしまいましたが、今回も
前回紹介したように、
このAPIからは番組のタイトルや放送日時、出演者、簡単な番組情報等は得られるものの、あくまで聴き逃し配信のプレイヤー用なので、放送された曲目リストや演奏者、作曲者といった細かい情報を得ることはできません。
一方、各番組のホームページを見ると、より詳しい楽曲リストも提供されています。
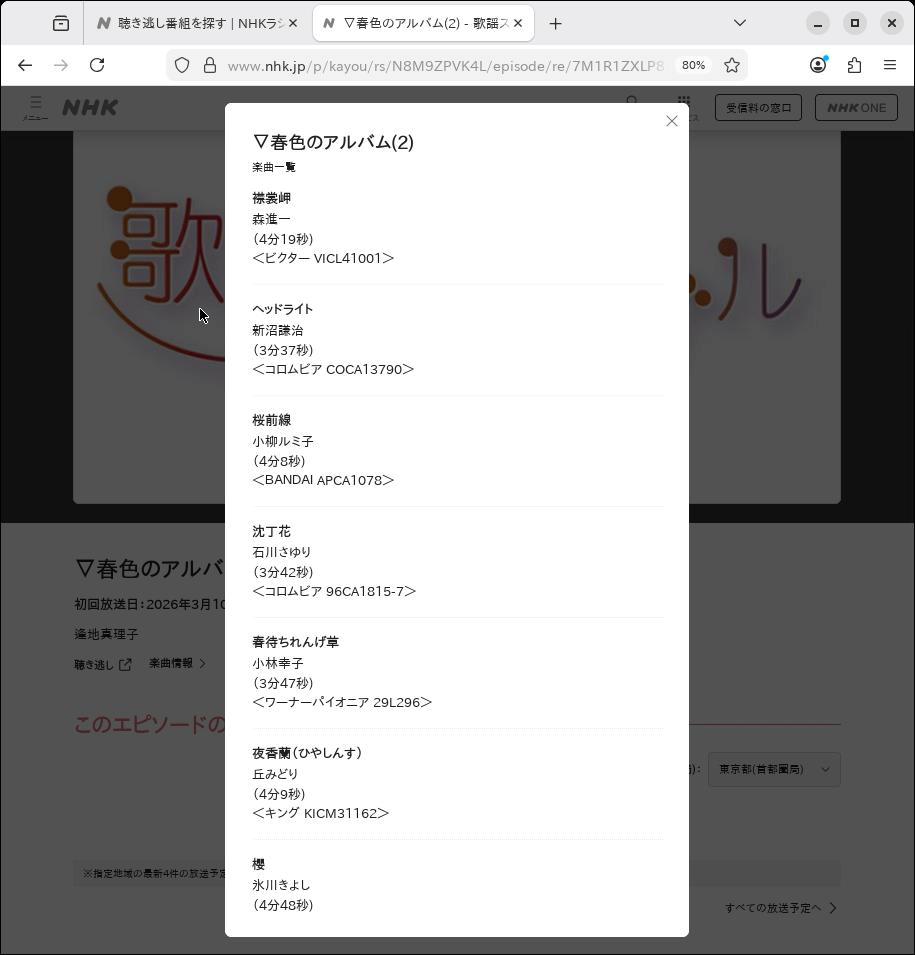
そうなると、両者を結びつけて楽曲情報も記録したくなるのが
楽曲情報の確認
実のところ、
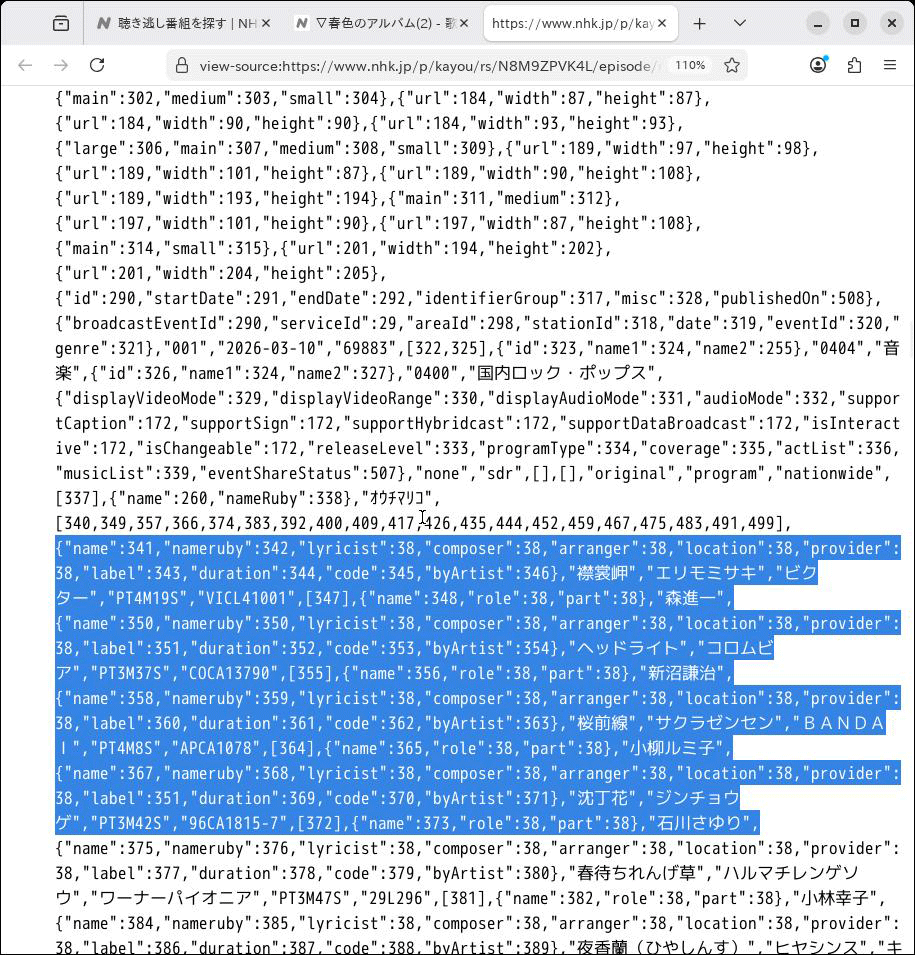
細かな仕組みまでは追求していませんが、ホームページではこの部分に埋め込まれたJSONデータを用いて楽曲情報等を表示しているようです。そこでこのJSONデータを調べてみることにしました。
まずはHTMLファイルをダウンロードして眺めてみると、どうやら id="NUXT_DATA" というラベルが付いたscriptタグの中にJSONデータが埋め込まれているようです。
<script type="application/json" data-nuxt-data="nuxt-app" data-ssr="true" id="__NUXT_DATA__"> .... </script></body></html>
この部分を切り出して独立したファイルとしてセーブし、少し見やすくするために、,[や{が続く部分に改行を入れてみました。
[["ShallowReactive",1],
{"data":2,"state":4,"once":6,"_errors":7,"serverRendered":9,"path":10,"pinia":11},
先の方まで見ていくと、楽曲リストらしきデータがあります。しかしながら、よく見る
[345,354,362,371,379,388,397,405,414,422,431,440,449,457,464,472,480,488,496,504],
{"name":346,"nameruby":347,"lyricist":38,"composer":38,"arranger":38,"location":38,"provider":38,"label":348,"duration":349,"code":350,"byArtist":351},"襟裳岬","エリモミサキ","ビクター","PT4M19S","VICL41001",
[352],
{"name":353,"role":38,"part":38},"森進一",
{"name":355,"nameruby":355,"lyricist":38,"composer":38,"arranger":38,"location":38,"provider":38,"label":356,"duration":357,"code":358,"byArtist":359},"ヘッドライト","コロムビア","PT3M37S","COCA13790",
[360],
{"name":361,"role":38,"part":38},"新沼謙治",
JSONのリストや辞書型の記法はPythonと同じなので、[...]をリスト、{...}を辞書型のデータと考えると、192行目の[345,354,362,…]の部分が曲のリスト、たぶん[345]に該当するのが次の193行目の辞書型データで"name:346"が"襟裳岬"、"nameruby:347"が"エリモミサキ"、"label:348"が"ビクター"、"duration:349"が"PT4M19S"に対応する、という関係になっているようです。
そう考えて見ていくと、どうやらこのデータ構造は、配列にデータを保持し、添字を使ってそのデータにアクセスする仕組みになっていて、データの最小単位は
$ python
Python 3.11.14 (main, Jan 10 2026, 23:29:44) [GCC 15.2.0] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import json
>>> with open('test_01.json','r') as f:
... json_dt = json.load(f)
...
>>> for i in range(0,len(json_dt)) :
... print(f"{i}:{json_dt[i]}")
...
0:['ShallowReactive', 1]
1:{'data': 2, 'state': 4, 'once': 6, '_errors': 7, 'serverRendered
...
344:[345, 354, 362, 371, 379, 388, 397, 405, 414, 422, 431, 440, 449, 457, 464, 472, 480, 488, 496, 504]
345:{'name': 346, 'nameruby': 347, 'lyricist': 38, 'composer': 38, 'arranger': 38, 'location': 38, 'provider': 38, 'label': 348, 'duration': 349, 'code': 350, 'byArtist': 351}
346:襟裳岬
347:エリモミサキ
348:ビクター
349:PT4M19S
350:VICL41001
351:[352]
352:{'name': 353, 'role': 38, 'part': 38}
353:森進一
354:{'name': 355, 'nameruby': 355, 'lyricist': 38, 'composer': 38, 'arranger': 38, 'location': 38, 'provider': 38, 'label': 356, 'duration': 357, 'code': 358, 'byArtist': 359}
355:ヘッドライト
356:コロムビア
357:PT3M37S
358:COCA13790
359:[360]
360:{'name': 361, 'role': 38, 'part': 38}
361:新沼謙治
こうしてみれば、344番目の箱
演者名
>>> for x in json_dt[344]:
... title = json_dt[json_dt[x]['name']]
... for artist in json_dt[json_dt[x]['byArtist']] :
... print(f"{title}/{json_dt[json_dt[artist]['name']]}")
...
襟裳岬/森進一
ヘッドライト/新沼謙治
桜前線/小柳ルミ子
沈丁花/石川さゆり
春待ちれんげ草/小林幸子
...
なお、後付けで調べたところ、ここで紹介しているような配列と添字を使って繰り返しが多いJSONデータを圧縮する方法は、Nuxt/
番組情報との結び付き
楽曲リストは取れそうなので、他にも面白そうな情報は無いかとJSONファイルを眺めていると、埋め込まれている楽曲リストは1つではないことに気づきました。
{'name': 265, 'nameRuby': 343}
[726, 734, 743, 751, 759, 767, 775, 783, 791, 798, 806, 814, ...
{'name': 727, 'nameruby': 728, 'lyricist': 38, 'composer': 38, 'arranger': 38,
'location': 38, 'provider': 38, 'label': 356, 'duration': 729, 'code': 730, 'byArtist': 731}
早春賦
ソウシュンフ
PT3M2S
COCP31489-90
[732]
{'name': 733, 'role': 38, 'part': 38}
ダ・カーポ
...
[1268, 1276, 1282, 1288, 1294, 1300, 1305, 1310, 1316, ...
{'name': 1269, 'nameruby': 1270, 'lyricist': 38, 'composer': 38, 'arranger': 38,
'location': 38, 'provider': 38, 'label': 877, 'duration': 1271, 'code': 1272, 'byArtist': 1273}
としごろ
トシゴロ
PT2M36S
SRCL4431-2
[1274]
{'name': 1275, 'role': 38, 'part': 38}
山口百恵
...
当初は1つのエピソード
333:{'displayVideoMode': 334, 'displayVideoRange': 335, 'displayAudioMode': 336,
'audioMode': 337, 'supportCaption': 177, 'supportSign': 177, 'supportHybridcast': 177,
'supportDataBroadcast': 177, 'isInteractive': 177, 'isChangeable': 177,
'releaseLevel': 338, 'programType': 339, 'coverage': 340, 'actList': 341,
'musicList': 344, 'eventShareStatus': 512}
もう一段遡って、この333を参照しているところを調べると、321で'misc'として参照しています。
321:{'id': 295, 'startDate': 296, 'endDate': 297, 'identifierGroup': 322,
'misc': 333, 'publishedOn': 513}
ここの'id': 295あたりがそれらしいな、と調べてみると、ビンゴ!、チャンネルr3-130-2026031069883)
295:r3-130-2026031069883 296:2026-03-10T12:30:00+09:00 297:2026-03-10T14:00:03+09:00
実は、この'r3-130-2026031069883'という番組IDは、前回紹介したストリーミング用データのURLを取るAPI
"aa_contents_id": "[radio]vod;名曲スケッチ 「波を越えて」「ドナウ川のさざ波」;
r2,130;2025121666476;2025-12-16T09:45:00+09:00_2025-12-16T09:55:00+09:00",
この'aa_
聴き逃し配信のURLから楽曲情報を取ってみる
さて、それでは前回のスクリプトを元に、楽曲情報を取る機能を追加してみましょう。
#!/usr/bin/python
#-*- coding: utf-8 -*-
import sys, requests, json, re
def get_music_list(bangumi_url, contents_id):
'''
各番組のホームページから、contents id を使って楽曲情報を拾う。
各ホームページには、後半に"__NUXT_DATA__"としてJSONデータが入っているので、
その部分を切り出してJSON化する
'''
res2 = requests.get(bangumi_url)
m = re.search(r'<script[^>]*__NUXT_DATA__[^>]*>(.*?)</script>', res2.text, re.S)
json_dt = json.loads(m.group(1))
find = False
for x in json_dt:
# contents_id を手掛りに
if isinstance(x, str) and contents_id in x:
find = True
# その直下にある musicList を拾う
if find == True and isinstance(x,dict) and 'musicList' in x.keys():
music_list = x['musicList']
break
if find == True: # contents_id が見つかっていれば、
for x in json_dt[music_list]: # musicList から、曲名、演者を拾う
title = json_dt[json_dt[x]['name']]
print(f"{title}/", end="")
for artist in json_dt[json_dt[x]['byArtist']] : # 'byArtist'はリストへのポインタ
print(f"{json_dt[json_dt[artist]['name']]}", end=" ")
print("")
def main():
'''
引数として、聴き逃し配信のページにある p=LG96ZW5KZ4_01 を指定。
対象が複数ある場合は、2番目の引数で番号を指定。0が最新(デフォルト)
'''
kikinogashi_id = sys.argv[1]
if len(sys.argv) == 3:
serial = int(sys.argv[2])
else:
serial = 0
if 'p=' in kikinogashi_id:
kikinogashi_id = kikinogashi_id.replace('p=','')
(pr, ser) = kikinogashi_id.split('_')
api_url = f"https://www.nhk.or.jp/radio-api/app/v1/web/ondemand/series?site_id={pr}&corner_site_id={ser}"
res = requests.get(api_url) # api_url を叩いて HLS用URL等を入手
bangumi_url = res.json()['series_url']
episode_info = res.json()['episodes']
title = episode_info[serial]['program_title']
ch_area = episode_info[serial]['aa_contents_id'].split(';')[2].replace(',','-')
event_id = episode_info[serial]['aa_contents_id'].split(';')[3]
# contents id は、"ch-エリア-日付+event_id" で構成
contents_id = ch_area + '-' + event_id
hls_url = episode_info[serial]['stream_url']
print(f"title:{title}\nhls_url:{hls_url}\nid:{contents_id}")
get_music_list(bangumi_url, contents_id)
if __name__ == "__main__":
main()
このスクリプトは、引数として聴き逃し配信のページを指定するp=LG96ZW5KZ4_等を渡すと、番組情報APIからHLSのURLを含む情報を入手し、その中にあるcontents_
たとえば
$ python ./dl_test2.py p=N8M9ZPVK4L_01 3 title:歌謡スクランブル ライト 木漏れ日のメロディー hls_url:https://vod-stream.nhk.jp/radioondemand/r/N8M9ZPVK4L/s/stream_N8M9ZPVK4L_7c42e94d6918f6fe008579fec3e47440/index.m3u8 id:r3-130-2026030772739 風をあつめて/はっぴいえんど 想い出がいっぱい/H2O やさしさに包まれたなら/荒井由実(松任谷由実) 赤いスイートピー/松田聖子 夢をあきらめないで/岡村孝子 RIDE ON TIME/山下達郎 夢で逢えたら/吉田美奈子
「古楽の楽しみ」
$ python ./dl_test2.py p=NWYPY4N3WW_01 title:古楽の楽しみ 疾風怒濤期の音楽 hls_url:https://vod-stream.nhk.jp/radioondemand/r/NWYPY4N3WW/s/stream_NWYPY4N3WW_5121749dc8bf0afc79524b63011b8d07/index.m3u8 id:r3-130-2026030668813 バレエ組曲「ドン・フアン」から第30曲、終曲/ル・コンセール・デ・ナシオン ジョルディ・サヴァール 交響曲 ニ短調/コンチェルト・ケルン 「交響曲 第49番 ヘ短調」から第2楽章/フライブルク・バロックオーケストラ ゴットフリート・フォン・デア・ゴルツ チェンバロ協奏曲 ヘ短調/シャレフ・アド・エル イル・ガルデリーノ
英数字が全角で記録されているあたりは少し気になるものの、とりあえずこの程度でも楽曲ファイルのメタタグに書き込む情報には間に合うでしょう。
前にも触れたように、NHKラジオは2026年度に現在の3波体制からAM/
一方、関連技術の進歩に伴ない、
2026年度の改編は放送波の削減が目的で放送機器回りはかなり変更されるだろうものの、インターネット周り、特に最近更新されたNuxt/