



寺田 学
「EV」
本記事では、Pythonを使ってベクトル検索パイプラインを一から構築する方法を解説します。テキストのEmbedding生成から始まり、ベクトルデータベースへの保存・
はじめに ―ベクトル検索の概要とPythonのエコシステム
キーワード検索の限界
従来のキーワード検索
| 特徴 | キーワード検索 | ベクトル検索 |
|---|---|---|
| マッチング | キーワードの一致 | 意味の類似性 |
| 得意なこと | 固有名詞、型番、完全一致 | 概念検索、表記揺れ吸収、曖昧な検索 |
| 苦手なこと | 同義語 |
特定キーワードの厳密な検索 |
両者の違いを

図1のように、キーワード検索は文字列の一致に依存するのに対して、ベクトル検索はテキストを数値ベクトルに変換し、ベクトル空間上の近さで判断するため、表現の揺れを越えて関連する文書を拾えます。
最近のトレンドは、両者の長所を組み合わせたハイブリッド検索です。本記事では、ベクトル検索の基礎をしっかり固めることに集中し、ハイブリッド検索については
ベクトル検索とは何か
ベクトル検索は、テキストや画像などのデータを高次元の数値ベクトルに変換し、ベクトル空間上の距離
ベクトル検索システムを構築するには、大きく分けて以下の4つのステップが必要です。
- Embedding化
(ベクトル化) :検索対象のドキュメント(テキスト、画像など) を、意味内容を表す数値の配列 (ベクトル) に変換する。この処理を行うのがEmbeddingモデルと呼ばれる機械学習モデルです - ベクトルの永続化:生成されたベクトルデータを、後で検索可能な形式で保存する。一般的にはベクトルデータベース
(Vector DB) を利用する - クエリのEmbedding化:ユーザーが入力した検索クエリを、同じモデルを使ってベクトルに変換し、クエリベクトルを生成
- ベクトルの近傍検索:クエリベクトルと距離が近い
(意味が似ている) ドキュメントベクトルを上記2項の永続化されたベクトルデータから探し出す
この4ステップを、
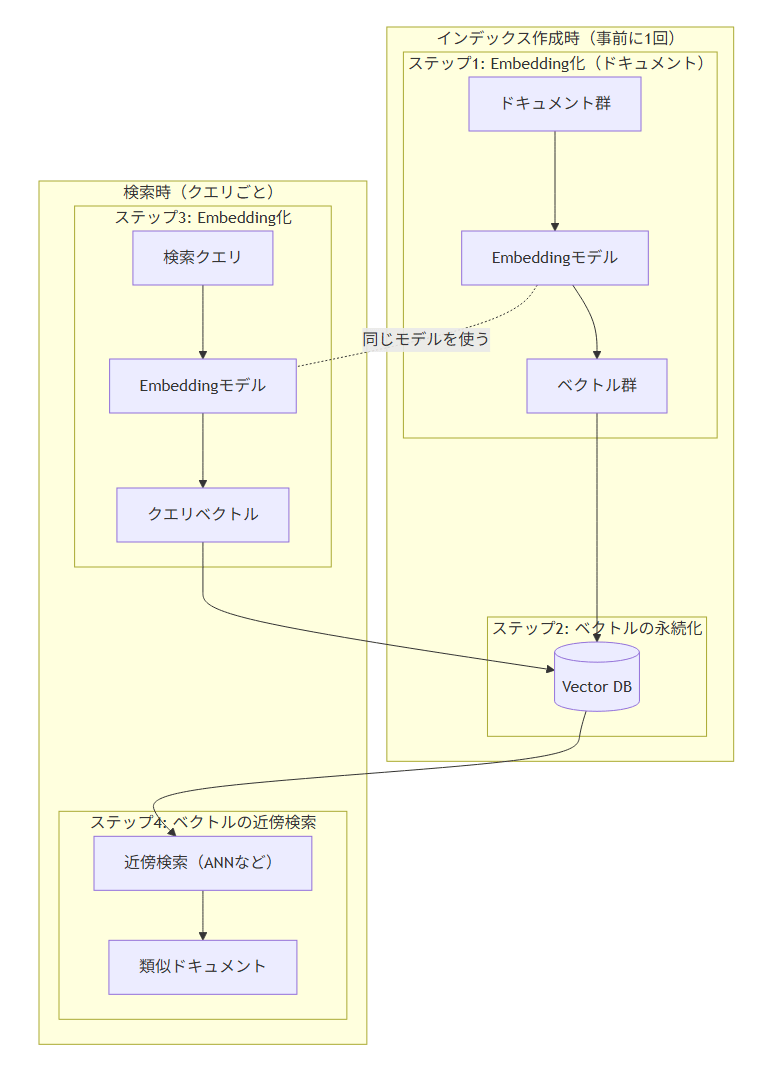
図2のポイントは、インデックス作成時と検索時で同じEmbeddingモデルを使うことと、Vector DBが近傍検索の効率化を担うことの2点です。後半のコード例もこの構造に沿って実装していきます。
実務での活用場面
ベクトル検索が実務で活用される代表的な場面を挙げます。
- RAG
(検索拡張生成) :LLMに渡すコンテキストとして、質問に意味的に近いドキュメントを検索する - 類似商品検索:ECサイトで
「この商品に似たもの」 を提示する - ドキュメント検索:社内ナレッジベースから関連する文書を探す
- 画像検索:テキストで画像を検索したり、画像で似た画像を探したりする
Pythonの役割
Embedding生成・
図2の4ステップを、本記事で実際に使う具体的なライブラリ・
| ステップ | 本記事で使う技術 | 他の選択肢 |
|---|---|---|
| 1. Embedding化 |
sentence-transformers+multilingual-e5 |
OpenAI Embeddings API, Ollama, FastEmbed |
| 2. ベクトルの永続化 | DuckDB+VSS拡張 | Qdrant, pgvector, LanceDB |
| 3. Embedding化 |
(1と同じモデルを使用) | — |
| 4. 近傍検索 | HNSW |
IVF, PQ など |
このように、本記事ではEmbeddingに sentence-transformersのmultilingual-e5、Vector DBにはDuckDBのVSS
動作環境
本記事のコードは以下の環境で動作確認しています。
| 項目 | バージョン | 備考 |
|---|---|---|
| Python | 3. |
|
| sentence-transformers | 5. |
テキストEmbedding生成 |
| duckdb | 1. |
ベクトルの保存・ |
| NumPy | 2. |
パッケージのインストール
uvを使う場合:
uv add sentence-transformers duckdb numpy
pipを使う場合:
pip install sentence-transformers duckdb numpy
テキストデータのベクトル化(Embedding)手法
Embeddingとは
Embedding
Embeddingモデルにはさまざまな種類があり、モデルごとに意味の捉え方が異なります。英語に強いもの、日本語を含む多言語に対応したもの、特定ドメインに特化したものなど、目的に応じた選択が必要です。また、出力するベクトルの次元数もモデルによって異なり、次元数が大きいほど意味の表現力は高くなりますが、その分ストレージや計算コストも増えます。Embeddingモデルの選択については後半の
もうひとつ注意すべきなのが入力テキストの長さ制限です。従来のBERTベースのモデルは、256〜512トークン程度を上限とするものが多く、それを超える文章は切り捨てられてしまいます。長い文書を扱う場合は、適切な長さに分割
たとえば、
以下のコードでは、同じテキストを2つのEmbeddingモデルでベクトル化し、出力されるベクトルの次元数を比較します。
from sentence_transformers import SentenceTransformer
text = "EVはバッテリーで駆動する乗用車です"
model_names = [
"intfloat/multilingual-e5-base" ,
"sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2" ,
]
for model_name in model_names:
model = SentenceTransformer(model_name)
embedding = model.encode(text, normalize_embeddings=True)
print(model_name)
print(f" ベクトルの形状: {embedding.shape} ")
print(f" 先頭5要素: {embedding[:5].round(4).tolist()}")
(略) intfloat/ multilingual-e5-base ベクトルの形状: (768,) 先頭5要素: [0. 02539999969303608, 0. 03759999945759773, 0. 012799999676644802, 0. 04989999905228615, 0. 03620000183582306] (略) sentence-transformers/ paraphrase-multilingual-MiniLM-L12-v2 ベクトルの形状: (384,) 先頭5要素: [0. 032499998807907104, 0. 10040000081062317, -0. 0210999995470047, 0. 012000000104308128, 0. 07150000333786011]
このあと、ベクトル同士の近さの測り方や、Embeddingを使った検索の実装を順に見ていきます。ここでは、モデルによってベクトルの次元数が異なる点に注目してください。
ベクトルの「近さ」を測る指標
ベクトル検索では、2つのベクトルがどれだけ
| 指標 | 測るもの | 値の範囲 | 特徴 |
|---|---|---|---|
| コサイン類似度 | ベクトルの向き |
-1〜1 | AI分野で最もよく使われる |
| ユークリッド距離 |
ベクトル間の直線距離 | 0〜∞ | 直感的だが、高次元では差が出にくい |
| 内積 |
ベクトルの向きと大きさ | -∞〜∞ | 正規化済みベクトルではコサイン類似度と同じ結果 |
コサイン類似度はベクトルの
ユークリッド距離
内積sentence-transformersのようにnormalize_で正規化を明示できます。正規化済みベクトル同士では、内積がコサイン類似度と完全に一致するため、大規模データでの検索では内積を使ったほうが計算効率が良くなります。
NumPyを使った計算例を示します。
from typing import Any
import numpy as np
# コサイン類似度
def cosine_similarity(a: np.ndarray, b: np.ndarray) -> float:
return np.dot(a, b) / (np.linalg.norm(a) * np.linalg.norm(b))
# L2距離(ユークリッド距離)
def l2_distance(a: np.ndarray, b: np.ndarray) -> np.floating[Any]:
return np.linalg.norm(a - b)
# 内積(正規化済みベクトル向け)
def dot_similarity(a: np.ndarray, b: np.ndarray) -> float:
return np.dot(a, b)
Embedding化の方法
Embedding化の方法は大きく分けて3つあります。
- PythonからローカルでEmbeddingモデルを動かす方法
(例: sentence-transformers) - 外部APIを使ってEmbeddingを生成する方法
(例:OpenAI Embeddings API) - OllamaのEmbedding機能を使う方法
(ローカルで完結するが、Ollamaサーバーの起動が必要)
3つのアプローチの特徴を以下の表にまとめます。
| 項目 | ローカルモデル |
外部API |
Ollama |
|---|---|---|---|
| コスト | 無料 |
従量課金 | 無料 |
| プライバシー | ◎(データが外部に出ない) | △(データがクラウドに送信される) | ◎(データが外部に出ない) |
| セットアップ | pip installのみ | APIキーが必要 | Ollamaサーバーの起動が必要 |
| 扱いやすさ | ◎(Pythonのみで完結) | ◎(APIなので言語を問わず扱いやすい) | ○ |
| オフライン対応 | ◎ | ✕ | ◎ |
| 精度 | モデルによる | 高品質 | モデルによる |
| 日本語対応 | モデルによる | ◎ | モデルによる |
プロトタイピングや個人プロジェクトではsentence-transformersのローカルモデルから始めるのが手軽です。
ここでは、PythonからローカルでEmbeddingモデルを動かす方法を中心に解説します。外部APIやOllamaは後述するコラムで紹介します。
sentence-transformersによるローカル実行
sentence-transformersは、テキストのEmbedding生成に特化したPythonライブラリです。Hugging Face上の多数のモデルを利用でき、ローカル環境で完結するため、プライバシーやコストの面でも安心して使えます。
以下のコード例では、日本語を含む多言語に対応したEmbeddingモデルintfloat/を使って簡単な検索シナリオを実装します。あらかじめ4つの文をドキュメントとしてベクトル化しておき、あとから入力した短い文
from sentence_transformers import SentenceTransformer
# ① モデルのロード(初回はHugging Faceからダウンロードされる)
model = SentenceTransformer("intfloat/multilingual-e5-base")
# ② 検索対象のドキュメント
documents = [
"電気自動車は環境にやさしい移動手段です",
"バッテリー駆動の新しい乗用車が増えています",
"今日は良い天気です",
"洗濯機は衣類を洗うための家電です",
]
# ③ ドキュメントをベクトル化
# multilingual-e5 系のモデルでは検索対象に "passage: " プレフィックスを付ける
doc_embeddings = model.encode(
[f"passage: {doc}" for doc in documents],
normalize_embeddings=True,
)
print(f"ベクトルの形状: {doc_embeddings.shape}")
# → ベクトルの形状: (4, 768)
# ④ 短いクエリで検索する(検索側には "query: " プレフィックス)
query = "EV"
query_embedding = model.encode(f"query: {query}", normalize_embeddings=True)
# ⑤ 全ドキュメントとの類似度を一括計算(正規化済みなので内積=コサイン類似度)
similarities = doc_embeddings @ query_embedding
ranked = sorted(zip(similarities, documents), reverse=True)
print(f"\n検索クエリ: 「{query}」")
print("-" * 50)
for sim, doc in ranked:
print(f"類似度 {sim:.4f}: {doc}")
実行結果は以下のようになります
ベクトルの形状: (4, 768) 検索クエリ: 「EV」 -------------------------------------------------- 類似度 0.8149: 電気自動車は環境にやさしい移動手段です 類似度 0.7931: バッテリー駆動の新しい乗用車が増えています 類似度 0.7715: 洗濯機は衣類を洗うための家電です 類似度 0.7397: 今日は良い天気です
「EV」
各ステップのポイントを説明します。
-
SentenceTransformerにモデル名を渡すだけでロードできます。初回実行時はモデルがダウンロードされます( multilingual-e5-baseは約1.1GB) - 検索対象のドキュメントを用意します
-
model.にリストを渡すとまとめてベクトル化されます。encode() normalize_を指定すると単位長に正規化され、以降は内積がそのままコサイン類似度になります。戻り値はembeddings=True (ドキュメント数, 次元数)のNumPy配列です - 検索クエリも同じモデルでベクトル化します
- 行列積
@で全ドキュメントとの類似度を一括計算し、降順に並べて表示します
コード中の"passage: " / "query: "はmultilingual-e5系のモデルで推奨されるプレフィックスです。モデルごとに付け方が異なるので、詳しくは後述のコラム
デバイス(GPU / CPU / MPS)の指定
SentenceTransformer は、計算に使うデバイスを device 引数で指定できます。指定しなければGPUの有無などから自動で選ばれますが、環境に合わせて明示しておくと挙動が安定します。
# NVIDIA GPU(CUDA)
model = SentenceTransformer("intfloat/multilingual-e5-base", device="cuda")
# Apple Silicon(M1〜M4 など)のMPS
model = SentenceTransformer("intfloat/multilingual-e5-base", device="mps")
# CPU
model = SentenceTransformer("intfloat/multilingual-e5-base", device="cpu")
筆者はNVIDIA GPU環境でdevice="cuda"を使っています。大量のドキュメントを一括でEmbeddingする用途ではGPUの有無が処理時間の大きな差につながります。数百〜数千件程度のデータであれば、device="cpu"でも実用的な速度で動作します。Apple Silicon搭載Macではdevice="mps"を指定するとPyTorchのMetal Performance Shadersバックエンドが使え、CPUよりも高速に動作します。
なお、GPUを使えない環境で大量のテキストを扱う場合は、ONNX RuntimeベースのFastEmbedという選択肢もあります。PyTorchより軽量に扱えるケースがあり、サーバーサイドやCI環境での運用に向いています。
長文をチャンクに分けてEmbeddingする
Embeddingモデルには入力長の上限があります。multilingual-e5-baseの場合は512トークン
そこで実務では、長文を一定の長さのチャンク

図3のように、chunk_分だけ切り出したら、次のチャンクはoverlap分戻った位置から始める、という動きを繰り返していきます。以下は、この考え方をそのまま実装したシンプルな例です。
from sentence_transformers import SentenceTransformer
def chunk_text(text: str, chunk_size: int = 200, overlap: int = 30) -> list[str]:
"""長文を指定された文字数のチャンクに分割する(オーバーラップあり)。"""
chunks = []
step = chunk_size - overlap
for start in range(0, len(text), step):
chunk = text[start:start + chunk_size]
if chunk:
chunks.append(chunk)
if start + chunk_size >= len(text):
break
return chunks
long_text = (
"Pythonはシンプルな文法と豊富なライブラリが特徴の汎用プログラミング言語です。"
"Webアプリケーション開発、データ分析、機械学習、スクリプティングなど、"
"幅広い用途で使われています。"
"近年は、生成AIやベクトル検索の分野でも事実上の標準言語として定着しました。"
"Hugging Face Transformersやsentence-transformersといったライブラリを使えば、"
"少ないコードでEmbeddingの生成や類似度検索を実装できます。"
"ベクトル検索はRAG(検索拡張生成)の基盤技術として、"
"社内ドキュメント検索やチャットボットの文脈提供などに応用されています。"
)
# ① 長文をチャンクに分割
chunks = chunk_text(long_text)
print(f"チャンク数: {len(chunks)}")
for i, chunk in enumerate(chunks):
print(f" [{i}] ({len(chunk)}文字) {chunk[:30]}...")
# ② 各チャンクをpassageとしてEmbedding化
model = SentenceTransformer("intfloat/multilingual-e5-base")
chunk_embeddings = model.encode(
[f"passage: {chunk}" for chunk in chunks],
normalize_embeddings=True,
)
# ③ クエリを同じモデルでEmbedding化(こちらは "query: " プレフィックス)
query = "RAGで使われる技術は何ですか"
query_embedding = model.encode(f"query: {query}", normalize_embeddings=True)
# ④ 各チャンクとの類似度を計算し、上位を表示
similarities = chunk_embeddings @ query_embedding # 正規化済みなので行列積=コサイン類似度
ranked = sorted(enumerate(similarities), key=lambda x: x[1], reverse=True)
print(f"\nクエリ: 「{query}」")
print("-" * 50)
for rank, (idx, sim) in enumerate(ranked[:3], 1):
print(f"{rank}位 類似度 {sim:.4f}: {chunks[idx]}")
実行結果の一部を抜粋すると、以下のようになります。
チャンク数: 2 [0] (200文字) Pythonはシンプルな文法と豊富なライブラリが特徴の汎用プ... [1] (115文字) ormersといったライブラリを使えば、少ないコードでEmb... (略) クエリ: 「RAGで使われる技術は何ですか」 -------------------------------------------------- 1位 類似度 0.8328: ormersといったライブラリを使えば、少ないコードで... 2位 類似度 0.7798: Pythonはシンプルな文法と豊富なライブラリが特徴の...
各ステップのポイントです。
-
chunk_では、指定した文字数ごとに切り出しつつ、チャンクの境界で意味がぶつ切りになるのを避けるためにオーバーラップtext() (重なり) を設けています。 chunk_とsize overlapは、対象文書の性質や利用するモデルの入力上限に合わせて調整してください - チャンクは検索対象のドキュメント扱いなので、
multilingual-e5の流儀に従い"passage: "プレフィックスを付けます - 検索クエリ側には
"query: "プレフィックスを付けます。同じモデルで両者をベクトル化することで、同一空間上で比較できます - 正規化済みベクトルでは行列積
( @)だけで全チャンクとのコサイン類似度をまとめて計算できます
この例では固定文字数で素朴に分割していますが、実務では段落や句点単位で区切る、文書の構造
Embeddingモデル選択のポイント
テキスト用Embeddingモデルは大きくBERTベースとLLMベースに分かれます。まずは筆者の視点で代表的なモデルを以下にまとめます。そのあとで、各モデルの性能を客観的に比較するための指標として、本セクション後半の
| モデル | ベース | 次元数 | 入力上限 | 日本語 | 特徴 |
|---|---|---|---|---|---|
| sentence-transformers/ |
BERT | 384 | 256トークン | △ | 軽量・ |
| intfloat/ |
BERT | 768 | 512トークン | ◎ | 多言語対応、バランスが良い |
| intfloat/ |
BERT | 1024 | 512トークン | ◎ | 多言語高精度、筆者のメイン |
| BAAI/ |
BERT | 1024 | 8192トークン | ◎ | 多言語・ |
| cl-nagoya/ |
ModernBERT | 768 | 8192トークン | ◎◎ | 日本語特化、長文対応、JMTEB高水準 |
| jinaai/ |
BERT+LoRA | 1024 | 8192トークン | ◎ | 多言語・ |
| nomic-ai/ |
BERT | 768 | 8192トークン | × | 英語専用、長文対応、ログ分析などに便利 |
| nomic-ai/ |
LLM(MoE) | 768 | 512トークン | ◎ | 多言語対応、Matryoshka対応 |
| google/ |
LLM | 768 | 2048トークン | ◎ | 小型・ |
| Qwen/ |
LLM | 1024 | 32768トークン | ◎ | 長文対応、高精度 |
モデルは
BERT系BAAI/やjinaai/、cl-nagoya/のように、8192トークン級の長文に対応したものもあります。
LLMベースは入力長の制限が大幅に緩和されており、表現力も高い傾向があります。ただしモデルサイズの幅が広く、大きめのモデルで実用的な速度を出すにはGPU環境がほぼ前提になります。一方で、google/のような小型モデルであれば、CPU環境でも用途次第で実用的に扱えます。
表中に出てくるMatryoshka対応は、1つのモデルから得たベクトルの先頭から指定した次元数分だけ切り出しても意味を保つ ように学習されたモデルを指します。たとえば、768次元で学習されたモデルでも、先頭256次元だけを使って検索できるため、保存容量や計算コストを大きく減らせます。精度と効率のトレードオフを後からコード側で調整できるのが利点です。名前は入れ子構造のマトリョーシカ人形に由来します。
モデル選定の参考になるベンチマーク(MTEB)
上述の表は筆者の視点でよく使われるモデルを整理したものですが、Embeddingモデルの世界は進歩が速く、新しいモデルも次々と登場します。客観的な比較指標として便利なのが、MTEBTotal Parameters)・Embedding Dimensions)・Max Tokens)
ベクトル検索用途では、画面左メニューのRetrievalか
ただしリーダーボードはあくまで参考程度に使うのが適切です。MTEBは結果の提出ベースで更新されるため、すべてのモデルや派生バリアントが載っているわけではありません。本記事の表に挙げたモデルの中にも、ベンチマークによっては掲載されていないものがあります。また、スコアは公開データセットに対する平均的な性能であり、実際のドキュメントやクエリでの精度と一致するとは限りません。用途によっては、上位ではないモデルでも十分な性能が出ることが多いので、気になった候補を数モデルに絞ったら、自分の用途に沿った評価データを数十〜数百件用意して比較してから採用するのが確実です。
ベクトルデータベースの種類と選択基準
Embeddingによってテキストが数値ベクトルに変換できるようになったら、次は大量のベクトルを効率よく保存・
なぜ通常のDBでは不十分か
生成したEmbeddingベクトルを保存するだけなら、通常のRDBMSやファイルでも問題ありません。しかし、
たとえば10万件のベクトルがあり、各ベクトルが768次元
ベクトルデータベース
代表的なベクトルデータベース
ベクトルデータベースには、専用のVector DB、既存RDBMSの拡張、ローカル/組み込み向けのものなどさまざまな選択肢があります。筆者はローカルでの実験やデータ分析にはDuckDB、本番運用にはQdrantを使い分けています。
| DB | 分類 | 用途 | セットアップ | SQLで操作 | フィルタリング | Pythonクライアント |
|---|---|---|---|---|---|---|
| DuckDB | ローカル/組み込み | ローカル実験・ |
pip installのみ |
◎ | ◎(SQL) | ◎(duckdb) |
| Qdrant | 専用Vector DB | 中〜大規模・ |
Docker推奨 | ✕ | ◎ | ◎ |
| Chroma | 専用Vector DB | プロトタイピング | pip installのみ | ✕ | ○ | ◎ |
| pgvector | RDBMSの拡張 | 既存PostgreSQL環境への追加 | PostgreSQL必要 | ◎ | ◎(SQL) | ○(psycopg2等) |
| sqlite-vec | RDBMSの拡張 | 軽量・ |
pip installのみ | ◎ | ○ | ○ |
| LanceDB | ローカル/組み込み | MLパイプライン・ |
pip installのみ |
△(SQLライクフィルタ) | ◎ | ◎ |
DuckDBはファイルベースの列指向データベースで、VSS
QdrantはRust製の高性能なVector DBで、本番運用を想定して設計されています。メタデータフィルタリング
Chromaは軽量でセットアップが容易なVector DBで、プロトタイピングに向いています。
pgvectorはPostgreSQLの拡張機能で、既存のPostgreSQL環境にそのまま追加できます。SQLでベクトル検索を記述でき、既存資産を活かせるのが強みです。
sqlite-vec はSQLiteにベクトル検索機能を追加する拡張で、軽量な組み込み用途に適しています。sqlite-vss の後継として開発が進められており、導入しやすさの面でも扱いやすい選択肢です。
LanceDBは、Lanceという列指向フォーマットをベースにした組み込み型のVector DBです。pip installで導入でき、ファイルベースで動く手軽さはDuckDBやsqlite-vecに近いですが、ML/
DuckDBを使った基本的なベクトル保存・検索
DuckDBのVSS拡張を使ったベクトルの保存と検索の基本的な流れを示します。ここではファイルベースのDuckDBを使い、ベクトルデータとHNSWインデックスの両方をファイルに永続化する設定にしています。
import duckdb
from sentence_transformers import SentenceTransformer
# ① DuckDBの初期化とVSS拡張のロード
con = duckdb.connect("vectors.duckdb")
con.execute("INSTALL vss; LOAD vss;")
# HNSWインデックスをファイルに永続化するための実験的設定
con.execute("SET hnsw_enable_experimental_persistence = true")
# ② テーブルの作成(multilingual-e5-base は768次元)
# スクリプトを複数回実行しても重複しないよう、最初にテーブルを作り直す
con.execute("DROP TABLE IF EXISTS documents")
con.execute("""
CREATE TABLE documents (
id INTEGER,
content TEXT,
embedding FLOAT[768]
)
""")
# ③ 保存するドキュメントの準備
documents = [
"Pythonは汎用プログラミング言語です",
"機械学習にはPythonがよく使われます",
"Rustはシステムプログラミング言語です",
"ベクトル検索はAIアプリケーションの基盤技術です",
"データベースはデータを永続化するシステムです",
]
# ④ Embeddingの生成(上記text_encoding.pyと同じ)
model = SentenceTransformer("intfloat/multilingual-e5-base")
embeddings = model.encode(
[f"passage: {doc}" for doc in documents],
normalize_embeddings=True,
)
# ⑤ ドキュメントとEmbeddingをテーブルに追加
for i, (doc, emb) in enumerate(zip(documents, embeddings)):
con.execute(
"INSERT INTO documents VALUES (?, ?, ?)",
[i, doc, emb.tolist()],
)
print(f"登録件数: {con.execute('SELECT COUNT(*) FROM documents').fetchone()[0]}")
# ⑥ HNSWインデックスの作成
con.execute("""
CREATE INDEX IF NOT EXISTS idx_documents_embedding
ON documents USING HNSW (embedding) WITH (metric = 'cosine')
""")
# ⑦ クエリによる類似検索(検索側は "query: " プレフィックス)
query = "AIと機械学習の関係"
query_embedding = model.encode(
f"query: {query}", normalize_embeddings=True
).tolist()
results = con.execute("""
SELECT content, array_cosine_distance(embedding, ?::FLOAT[768]) AS distance
FROM documents
ORDER BY distance ASC
LIMIT 3
""", [query_embedding]).fetchall()
print(f"\nクエリ: 「{query}」")
print("検索結果:")
for content, distance in results:
similarity = 1 - distance
print(f" 類似度 {similarity:.4f}: {content}")
con.close()
実行結果は以下のようになります
登録件数: 5 クエリ: 「AIと機械学習の関係」 検索結果: 類似度 0.8482: 機械学習にはPythonがよく使われます 類似度 0.8311: ベクトル検索はAIアプリケーションの基盤技術です 類似度 0.8030: Rustはシステムプログラミング言語です
クエリ機械学習を直接含む文が最上位AIを含むベクトル検索関連の文がその次、という順にランキングできました。キーワード完全一致ではなく意味的な関連性で並んでいることがわかります。
各ステップのポイントを解説します。
- この例では
duckdb.でファイルベースのデータベースを作成します。HNSWインデックスをファイルに永続化したいため、この構成にしています。インメモリで試すだけなら、引数なしのconnect("vectors. duckdb") duckdb.でも利用できますconnect() - 補足:
hnsw_は、HNSWインデックスをファイルに永続化するための実験的な設定です。DuckDB公式ドキュメントでも実験的機能とされているため、クラッシュ時の復旧手順や制約は事前に確認してくださいenable_ experimental_ persistence
- 補足:
- 通常のSQLでテーブルを作成します。ベクトルは
FLOAT[次元数]型で定義します(ここでは multilingual-e5-baseの出力に合わせて768次元)。同じスクリプトを繰り返し実行しても重複挿入されないよう、冒頭でDROP TABLE IF EXISTSしてから作り直しています - 〜⑤ ドキュメントとそのEmbeddingをSQLのINSERT文で登録します。
multilingual-e5系のモデルに合わせて"passage: "プレフィックスを付けnormalize_で単位長に正規化していますembeddings=True - HNSWインデックスを作成します。大規模データでの検索高速化に有効です
-
array_関数でコサイン距離を計算し、距離の近い順に取得します。クエリ側にはcosine_ distance() "query: "プレフィックスを付けてベクトル化します。metric = 'cosine'のHNSWインデックスもこの形で利用されます。表示時には1 - distanceで類似度に戻しています。SQLで書けるため、WHERE句での絞り込みも自在に組み合わせられます
まとめ
本記事では、Pythonを使ったベクトル検索パイプラインの構築を、以下の流れで解説しました。
- Embedding:テキストを数値ベクトルに変換する仕組みと、
sentence-transformersを使った実装方法を紹介しました。長文を扱うためのチャンキングや、ベクトルの「近さ」 を測る指標 (コサイン類似度、L2距離、内積) についても整理しました - Vector DB:DuckDB
(VSS拡張) を使ったローカルでのベクトル保存・ 検索を実装しました。Qdrant・ pgvector・ Chroma・ sqlite-vecなど、用途に応じた選択肢も比較しました
ベクトル検索はまだまだ進化の途中ですが、道具を選んで組み合わせることで、個人の開発環境でも十分に強力な検索システムを作ることができるようになっています。Embeddingモデルの進化、量子化手法の発展、マルチモーダル対応の拡充など、この分野は変化が非常に速いです。
次のステップ
本記事で扱ったベクトル検索パイプラインは、さらに以下の方向に発展させることができます。
- RAGパイプラインへの発展:ベクトル検索とLLMを組み合わせ、質問応答システムを構築する
- ハイブリッド検索:キーワード検索とベクトル検索を組み合わせ、両者の長所を活かした検索システムを構築する
- 本番環境でのVector DB運用:Qdrantのクラウドサービスや、pgvectorを使った既存PostgreSQL環境への統合
- Embeddingモデルのファインチューニング:特定ドメインのデータでモデルを調整し、検索精度をさらに向上させる