



寺田 学
先月号では、テキストのEmbedding生成と、ベクトルデータベース
さらに後半では、大規模なベクトルデータを扱う際に欠かせない近似最近傍探索HNSW インデックスを例に、近似最近傍探索の仕組みを解説します。
動作環境
本記事のコードは以下の環境で動作確認しています。
| 項目 | バージョン | 備考 |
|---|---|---|
| Python | 3. |
|
| transformers | 5. |
SigLIP 2の利用 |
| torch | 2. |
CUDA 12. |
| Pillow | 12. |
画像処理 |
| NumPy | 2. |
筆者はNVIDIA GPU
パッケージのインストール
uvを使う場合:
uv add transformers torch pillow numpy
pipを使う場合:
pip install transformers torch pillow numpy
画像とテキストを統合するマルチモーダル検索の構成
ここでは、テキストと画像を同一のベクトル空間に配置するマルチモーダルEmbeddingを使って、テキスト→画像検索と画像→画像検索の両方を実装する方法を紹介します。
マルチモーダルEmbeddingとは
先月号で紹介したEmbeddingはテキストのみを扱っていました。マルチモーダルEmbeddingは、テキストと画像
ベクトルが同一空間に配置されることで、
この仕組みの先駆けとなったのが、OpenAIが2021年に発表したCLIP
このTwo-Towerモデルの考え方を図1にまとめます。
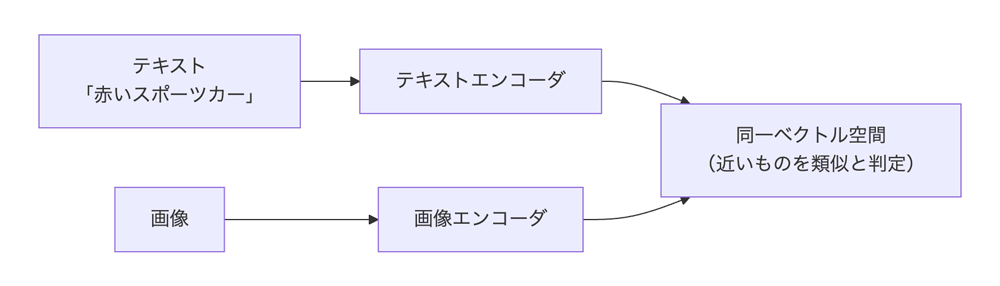
図1のように、テキストと画像はそれぞれ別のエンコーダでベクトル化されますが、出力が同じ空間に収まるため、テキストと画像を横断した類似度計算が可能になります。
従来の方法では、画像をテキストから検索するために、画像を説明するテキストを用意したり、メタデータを付ける必要がありました。マルチモーダルEmbeddingを使うと、画像そのものをベクトル化してテキストと同一空間に配置できるため、テキストクエリで直接画像を検索できるようになります。さらに、画像→画像検索も同じ空間で行えるため、類似画像の検索も可能になります。
SigLIP 2の紹介
SigLIP 2
Hugging Face上でgoogle/等のモデルIDで公開されており、transformersライブラリから利用できます。
先月号ではテキストのEmbedding生成にsentence-transformersを使いましたが、本記事ではtransformers+torchを直接使う構成にしています。sentence-transformersでもCLIP系のマルチモーダルモデルは扱えますが、transformersを直接呼び出すと、テキスト用get_)get_)
その自由度の代償として、SigLIP 2のget_ / get_はsentence-transformersのnormalize_のような正規化オプションを持ちません。そのため、コサイン類似度を内積で計算するには、取得後に自分でL2正規化
テキスト→画像検索パイプラインの実装
これから実装するパイプラインの全体像を図2に示します。考え方としては、検索対象の画像をあらかじめEmbedding化して画像ベクトル群を作り、検索時はクエリ
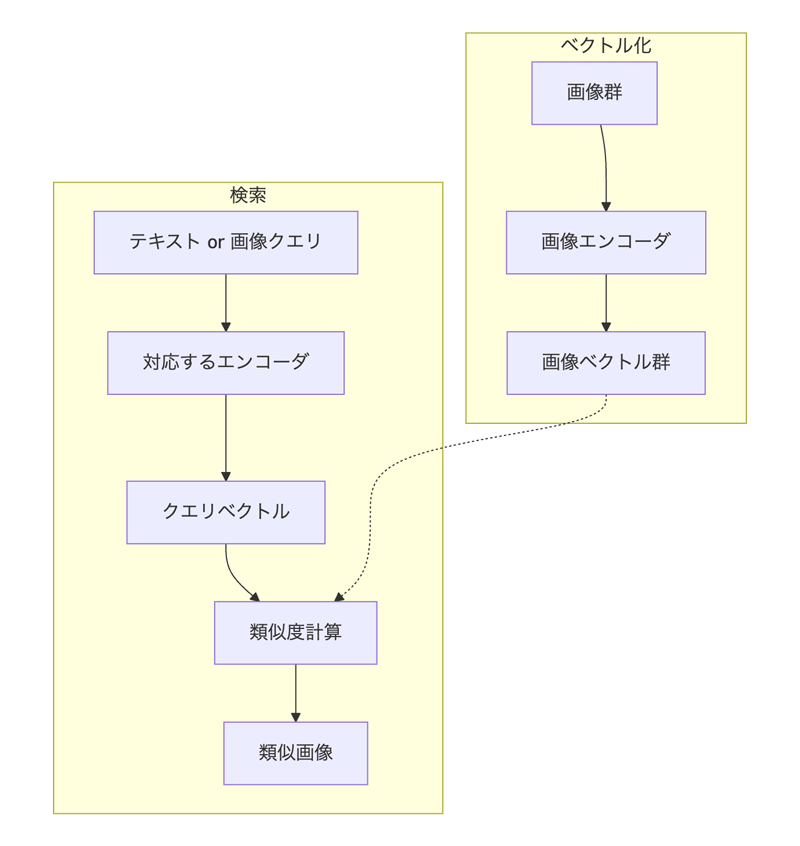
図2のように、検索対象は画像ベクトル群として保持し、クエリ側だけをテキスト用・
以下のディレクトリ構成を前提としています。
project/
├── images/ # 検索対象の画像ファイル(JPEG/PNG)
│ ├── photo001.jpg
│ ├── photo002.jpg
│ └── ...
└── search_pipeline.py
まず、画像群のベクトルを生成してメモリ上にベクトル群を保持し、テキストクエリで検索するパイプラインを実装します。
from pathlib import Path
import numpy as np
import torch
from PIL import Image
from transformers import AutoProcessor, AutoModel
# ① モデルとプロセッサのロード
MODEL_ID = "google/siglip2-base-patch16-224"
if torch.cuda.is_available():
device = "cuda"
elif torch.backends.mps.is_available():
device = "mps"
else:
device = "cpu"
print(f"使用デバイス: {device}")
processor = AutoProcessor.from_pretrained(MODEL_ID)
model = AutoModel.from_pretrained(MODEL_ID).to(device)
model.eval()
# ② 画像のベクトル生成(バッチ処理)
def encode_images(image_paths: list[Path], batch_size: int = 8) -> np.ndarray:
"""画像リストをバッチ処理でEmbeddingしベクトルに変換する"""
all_embeddings = []
for i in range(0, len(image_paths), batch_size):
batch_paths = image_paths[i : i + batch_size]
images = [Image.open(p).convert("RGB") for p in batch_paths]
inputs = processor(images=images, return_tensors="pt").to(device)
with torch.no_grad():
image_features = model.get_image_features(**inputs).pooler_output
# L2正規化(コサイン類似度計算のため)
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
all_embeddings.append(image_features.cpu().numpy())
print(
f" 処理済み: {min(i + batch_size, len(image_paths))}/{len(image_paths)} 枚"
)
return np.vstack(all_embeddings)
# ③ テキストのベクトル生成
def encode_text(text: str) -> np.ndarray:
"""テキストをEmbeddingしベクトルに変換する"""
inputs = processor(
text=[text],
padding="max_length",
max_length=64,
truncation=True,
return_tensors="pt",
).to(device)
with torch.no_grad():
text_features = model.get_text_features(**inputs).pooler_output
text_features = text_features / text_features.norm(dim=-1, keepdim=True)
return text_features.cpu().numpy()
# ④ ベクトル群の構築
image_dir = Path("images")
image_paths = sorted(list(image_dir.glob("*.jpg")) + list(image_dir.glob("*.png")))
print(f"Embedding対象: {len(image_paths)} 枚")
print("画像のベクトルを生成中...")
image_embeddings = encode_images(image_paths)
print(f"ベクトル群の構築完了: shape={image_embeddings.shape}")
# ⑤ テキストクエリによる検索
def search_by_text(query: str, top_k: int = 5) -> list[tuple[Path, float]]:
"""テキストクエリで類似画像を検索する"""
query_embedding = encode_text(query)
# コサイン類似度の計算(正規化済みベクトルの内積)
similarities = (image_embeddings @ query_embedding.T).squeeze()
# 上位k件のベクトルを取得
top_indices = np.argsort(similarities)[::-1][:top_k]
return [(image_paths[i], float(similarities[i])) for i in top_indices]
# ⑥ 検索の実行
queries = ["鳥", "講演", "海外のイベントで大舞台に立ってスピーチしている", "朝日が昇る空"]
for query in queries:
print(f"\nクエリ: 「{query}」")
print("検索結果:")
results = search_by_text(query, top_k=2)
for path, score in results:
print(f" スコア {score:.4f}: {path.name}")
検索対象として用意した画像は以下の12枚です。検索対象の画像

実行結果は以下のようになります。
使用デバイス: cuda Loading weights: 100%|██| 408/408 [00:00<00:00, 11024.35it/s] Embedding対象: 12 枚 画像のベクトルを生成中... 処理済み: 8/12 枚 処理済み: 12/12 枚 ベクトル群の構築完了: shape=(12, 768) クエリ: 「鳥」 検索結果: スコア 0.0957: waterside-park-flock.jpg スコア 0.0826: waterside-park-ducks.jpg クエリ: 「講演」 検索結果: スコア 0.1046: europython-talk-02.jpg スコア 0.0941: europython-talk-01.jpg クエリ: 「海外のイベントで大舞台に立ってスピーチしている」 検索結果: スコア 0.1006: europython-talk-01.jpg スコア 0.0975: europython-keynote-02.jpg クエリ: 「朝日が昇る空」 検索結果: スコア 0.0704: skytree-04-27.jpg スコア 0.0650: sluice-gate-02.jpg
スコアの絶対値が0.
画像群に存在しないクエリ
各ステップのポイントを説明します。
-
AutoProcessorとAutoModelを使ってモデルをロードします。デバイスは前述のコラムの方針で自動判定しています。google/は標準サイズのSigLIP 2で、出力ベクトルは768次元です。モデル名末尾のsiglip2-base-patch16-224 224はモデル内部の処理解像度(224×224) を示しますが、 AutoProcessorが任意サイズの画像をこの解像度に自動でリサイズ・正規化してくれるため、入力画像のサイズを事前に揃える必要はありません。用途に応じて siglip2-large-patch16-256などより大きなモデルも選択できます(なお、SigLIP 2にはアスペクト比を保ったまま可変解像度で扱えるNaFlex版 siglip2-base-patch16-naflexもあります) - 画像をバッチ処理でベクトルに変換します。1枚ずつ処理するよりGPUへのデータ転送やモデル呼び出しのオーバーヘッドが減るため効率的です
- テキストも同様にベクトルに変換します。SigLIP 2では
padding="max_とlength" max_を指定し、学習時の前処理に合わせて固定長にパディングします。これがないと検索精度が低下することがあります。テキストと画像が同一空間に配置されているため、同じ計算で類似度を測れますlength=64 - この例では、検索対象の画像すべてのベクトルをスクリプト実行時に計算し、メモリ上のベクトル群として保持します
- クエリのベクトルとベクトル群の内積を計算し、スコアが高い順に並べ替えます
- 複数のクエリで検索を実行します。4つのクエリは、画像の内容を表す単語
(「鳥」 「講演」)から、より具体的な説明文 (「海外のイベントで大舞台に立ってスピーチしている」)まで幅広く用意しています
画像→画像検索パイプラインの実装
クエリが画像の場合も、同じベクトル群image_)
前節のテキスト→画像検索のコードに、以下の差分を加えるだけで実装できます。
# 以下は前節「テキスト→画像検索」と同じであるため省略
# - import文 / MODEL_ID / device 判定
# - processor / model のロード
# - encode_images() 関数
# ① クエリ画像のベクトルを生成(テキスト用の encode_text() 関数の代わりに使う)
def encode_query_image(image_path: Path) -> np.ndarray:
"""クエリ画像をEmbeddingに変換する"""
image = Image.open(image_path).convert("RGB")
inputs = processor(images=[image], return_tensors="pt").to(device)
with torch.no_grad():
image_features = model.get_image_features(**inputs).pooler_output
image_features = image_features / image_features.norm(dim=-1, keepdim=True)
return image_features.cpu().numpy()
image_dir = Path("images")
image_paths = sorted(list(image_dir.glob("*.jpg")) + list(image_dir.glob("*.png")))
print(f"Embedding対象: {len(image_paths)} 枚")
print("画像のベクトルを生成中...")
image_embeddings = encode_images(image_paths)
print(f"ベクトル群の構築完了: shape={image_embeddings.shape}")
# ② クエリ画像でベクトル群を検索する
def search_by_image(query_path: Path, top_k: int = 5) -> list[tuple[Path, float]]:
"""クエリ画像で類似画像を検索する"""
query_embedding = encode_query_image(query_path)
similarities = (image_embeddings @ query_embedding.T).squeeze()
top_indices = np.argsort(similarities)[::-1][: top_k + 1]
# クエリ画像自身を除外する
return [
(image_paths[i], float(similarities[i]))
for i in top_indices
if image_paths[i] != query_path
][:top_k]
# ③ 画像→画像検索の実行
query_image_path = Path("images/europython-keynote-01.jpg")
print(f"\nクエリ画像: {query_image_path.name}")
print("類似画像:")
results = search_by_image(query_image_path, top_k=2)
for path, score in results:
print(f" スコア {score:.4f}: {path.name}")
実行結果は以下のようになります。
Embedding対象: 12 枚 画像のベクトルを生成中... 処理済み: 8/12 枚 処理済み: 12/12 枚 ベクトル群の構築完了: shape=(12, 768) クエリ画像: europython-keynote-01.jpg 類似画像: スコア 0.8428: europython-talk-01.jpg スコア 0.7557: europython-panel.jpg
各ステップのポイントを説明します。
- テキスト用の
encode_関数の代わりに、text() processor(images=[image], ...)でクエリ画像をベクトルに変換します。encode_関数の単一画像版とも言えますimages() - 類似度計算とランキングはテキスト→画像検索と同じです。クエリ画像自身が結果に混ざるとノイズになるため、フィルタで除外しています
- 同じ
image_ベクトル群に対して、クエリだけを画像に差し替えて検索していますembeddings
マルチモーダル検索の実装上のポイント
- モダリティギャップに注意:SigLIP 2やCLIPのようなTwo-Towerモデル
(テキストと画像でエンコーダが分かれているモデル) では、テキストと画像のベクトル分布が同一空間内で分離する傾向があります。本記事でも、テキスト→画像検索ではスコアが0. 1前後 、画像→画像検索では0.7〜0. と、検索方式によって値域が大きく異なります。これは8 「モダリティギャップ」 と呼ばれる現象で、スコアの絶対値だけでは検索精度の低下とは判断できません。検索結果はスコアの絶対値ではなく、同じ検索方式内での相対的な順位で評価してください - 人物検索には不向き:SigLIP 2やCLIPは画像全体の
「雰囲気」 をベクトル化するため、 「同一人物を探したい」 用途には向きません。筆者の実験でも、特定の人物の写真で類似画像検索すると別人がヒットすることがありました。人物検索が主目的なら、InsightFaceに含まれるArcFaceのような顔認識モデルを別途組み合わせるのが実務的です
近似最近傍探索(ANN)の仕組みとベクトルの軽量化
ここからは、大規模なベクトルデータを扱う際の課題と解決策について紹介します。前節のコード例は少量の画像で動作を理解するための最小構成でしたが、実務では数万件から数百万件のベクトルを扱うことも珍しくありません。そうした大規模データに対して、厳密な最近傍探索
kNNの限界
本記事のテキスト→画像検索のSigLIPコード例では、NumPyでクエリベクトルと全画像ベクトルとの類似度計算を行っています。これはkNN
データ件数が少ない場合は問題ありませんが、10万件・
ANNとは
近似最近傍探索
代表的なANNアルゴリズムを2つ紹介します。
HNSW
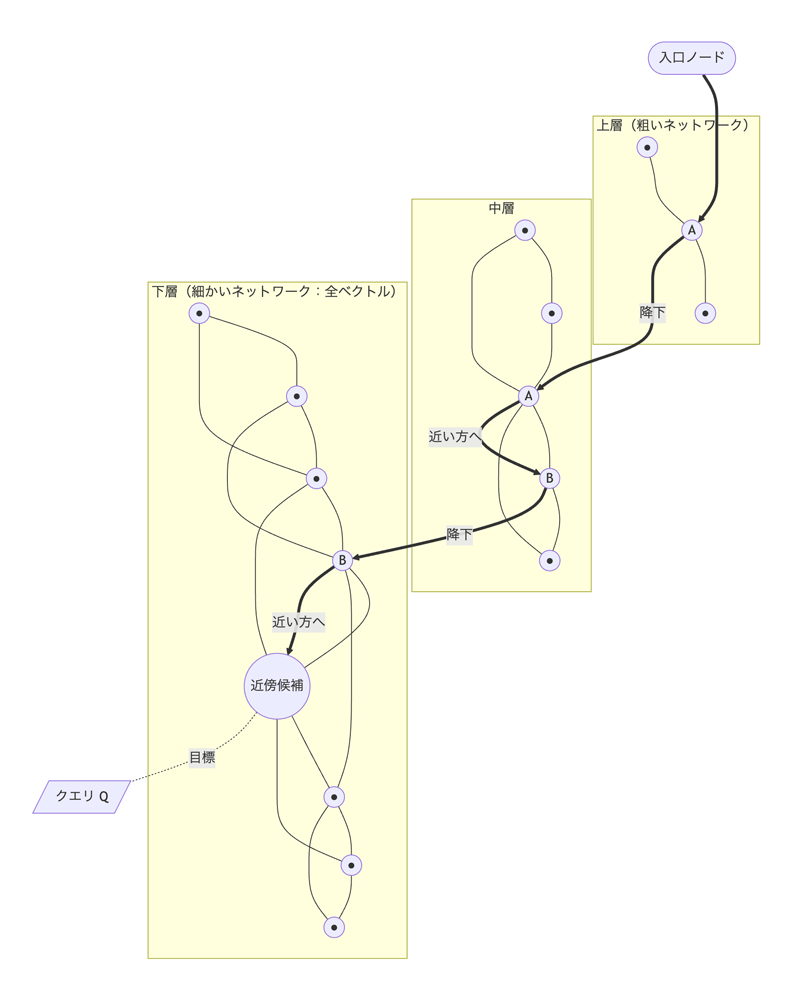
図3のように、HNSWはベクトル同士を近いもの同士でエッジでつないだグラフを階層的に持ちます。上層の粗いネットワークで大まかに近い場所まで進み、下層に降りてより細かく探します。実際には同じデータ点が複数の層に現れ、上位層で到達したノードを下位層の探索の出発点として使えます。全件比較を避けながら、クエリ近傍のノードに到達できるのが特徴です。
HNSWのこの階層構造とグラフ構造は、それぞれ次の2つのアイデアを組み合わせたものです。HNSWの名称
- スキップリスト
(階層構造 = Hierarchical) :交通機関の「飛行機→新幹線→各停」 の乗り換えのように、最初は粗いネットワーク (上層) で大まかに目的地の近くまでジャンプし、徐々に細かいネットワーク (下層) に降りていく仕組み - スモールワールド
(Navigable Small World) :「友達の友達を数人たどるだけで世界中の誰にでも繋がる」 というネットワークの性質。これにより、少ないステップ数で目的のベクトルに辿り着ける
この組み合わせにより、全件比較よりも大幅に少ない比較回数で近傍候補に到達できます。実際の検索精度と速度は、データの分布や検索対象の規模によって変わります。
HNSWのより詳しい仕組みや関連手法については、以下を参照してください。
『ベクトル検索実践入門』 (技術評論社:2026) - グラフを用いた近似最近傍探索の理論と応用
(YANSチュートリアル資料:2023) 筆者お勧めの資料で、HNSWのアルゴリズムの詳細や、他のグラフベースのANN手法との比較も解説しています
実際は複数階層のグラフを使ってさらに高速化しています。本記事では概念を優先して単層で示していますが、この階層化により、上位層でざっくり当たりをつけて下位層で細かく探すことが可能になり、数百万件のデータからでも数十ステップで近傍を見つけることができます。
IVF
先月号のDuckDBのコード例ですでにANNを使っています。CREATE INDEX ... USING HNSWでHNSWインデックスを作成し、array_をORDER BY ... LIMITと組み合わせることで、HNSWインデックスを利用した近似検索になります。QdrantやChromaなどのVector DBも内部でHNSWを採用しており、利用者が意識せずともANNの恩恵を受けられる設計になっています。
ただし、ANNインデックスの構築時にはCPU負荷とメモリ消費が大きくなる点に注意が必要です。HNSWの場合、各ベクトルを近傍候補と接続するグラフを構築するため、データ件数が増えるほど構築時間とメモリ使用量が増大します。検索は高速ですが、インデックスの構築や更新にはそれなりのリソースが必要になることを見込んでおきましょう。
筆者自身も、業務プロジェクトの中でデータの規模やベクトルの特性に合わせて、ANNインデックスの選定・M、ef_、ef_ などのパラメータを各Vector DBのドキュメントに従って調整することで、精度と速度のバランスを取ることができます。後述の
ベクトルの軽量化アプローチ
大規模なベクトルデータを扱う場合、ストレージとメモリの効率化も重要です。代表的なアプローチは以下の3つです。
- 次元削減:PCA
(主成分分析) などで次元数を圧縮する (例:768次元 → 256次元でメモリ約1/ 3) - 量子化
(Quantization) :数値精度を下げる(例:float32 → int8でメモリ約1/ 4)。さらに、ベクトルを部分ベクトルに分割して圧縮するProduct Quantization (PQ) のような手法もある - Matryoshka対応モデル:先頭側の次元だけを切り出しても精度を保ちやすいモデル
(先月号でも紹介した google/等)。後から次元数を調整できるのが利点embeddinggemma-300m
いずれの手法も精度とトレードオフがあるため、後述の評価指標で実測しながら採用判断するのが確実です。
実務での判断ポイント
精度とパフォーマンスのトレードオフを考える際の目安をまとめます。
データ規模による選択
- データ件数が1000件以下:
.npy等の配列ファイルで十分なことが多い - データ件数が1万件以下:メモリ上のkNN
(全件スキャン) で検証し、応答速度に問題が出るかを確認する - データ件数が1万件超〜100万件:HNSWなどのANNインデックスを導入する
- データ件数が100万件以上:IVFやProduct Quantizationを組み合わせた大規模向けの構成を検討する
メタデータフィルタリングとの組み合わせ
ベクトル検索は
どちらの方式も一長一短です。ANNインデックスを使う場合は、アルゴリズムや実装によっては事前フィルタリングが難しいこともあります。たとえばフィルタリングを考慮しないHNSWインデックスで検索対象を先に大きく減らすと、グラフの接続関係を十分に辿れず、検索精度が低下する可能性があります。そうした場合は、ベクトル検索の後にメタデータで絞り込む事後フィルタリングの方が現実的です。
QdrantなどのモダンなVector DBはメタデータフィルタリングに対応しており、フィルタリング条件を考慮したインデックスやクエリプランナによって、
評価指標で実測する
ANNの良し悪しを判断するには、体感だけでなく 評価指標で確認することも重要です。
ANNはRecall@k)
代表的なものを2つ紹介します。ここで言う
- 再現率
( Recall@k):正解集合のうち、検索結果の上位k件に含まれていた割合。関連文書を複数拾いたいRAGなどに向く - 平均逆順位
( MRR:Mean Reciprocal Rank):正解ラベルがある検索タスクで、最初の正解が何位に現れたかの逆数の平均。FAQ検索のように「最初の1件が当たっていればよい」 場面に向く
まとめ
本記事では、ベクトル検索の応用として、テキストと画像を横断するマルチモーダル検索の実装例と、近似最近傍探索
- マルチモーダル検索:SigLIP 2を使ってテキストと画像を同一ベクトル空間に配置し、テキスト→画像・
画像→画像の検索パイプラインを実装しました。検索方式によってスコアの値域が大きく異なる 「モダリティギャップ」 など、Two-Towerモデル特有の挙動も確認しました - ANN・
軽量化 :kNNの限界からHNSWによる近似最近傍探索の仕組み、量子化・次元削減・ Matryoshkaなどの軽量化アプローチ、 Recall@kなどの評価指標を含む実務上の判断ポイントまで概要を説明しました
筆者自身、PyCon JPの2万枚を超えるイベント写真を使った画像検索の実験を行い、
次のステップ
本記事で扱ったマルチモーダル検索パイプラインは、以下の方向に発展させることができます。
- マルチモーダルRAG:テキスト・
画像の検索結果をLLMのコンテキストとして渡し、画像内容を含めた質問応答を実現する - 顔認識との組み合わせ:SigLIP 2で全体の雰囲気を、
ArcFace(InsightFace) で同一人物の判定を行うハイブリッド構成 - メタデータフィルタとの組み合わせ:Qdrant等のVector DBで、撮影日時・
場所・ タグなどでベクトル検索を絞り込む - 大規模運用でのANNチューニング:HNSWの
M、ef_、construction ef_などのパラメータ調整によるsearch Recall@kと検索速度の最適化 - ドメイン特化ファインチューニング:特定の業界・
用途のデータでSigLIP 2を追加学習し、検索精度を向上させる