tidyverseが登場して以降、「整然とした」という意味を持つ「tidy」という言葉がRユーザ界隈で使われるようになりました。tidyverseはtidyなデータを作るためのさまざまなツールの集まり、およびtidyverseパッケージそのものを指します。筆者の共著でもある『改訂2版 RユーザのためのRStudio[実践]入門』では、tidyverseの目指すところを宣言した「tidy tools manifesto」が紹介されており、以下の4つの原則が紹介されています。
- 再利用しやすいデータ構造を使う(Reuse existing data structures)
- 複雑なことを1つの関数で行うよりも、単純な関数を%>%演算子で組み合わせる(Compose simple functions with the pipe)
- 関数型プログラミングを活用する(Embrace functional programming)
- 人間にやさしいデザインにする(Design for humans)
このようなtidyverseの原則にしたがって機械学習モデリングができないかを考える中でtidymodels(群)が開発されました。2022年に1.0.0バージョンがリリースされた新しいパッケージです。
機械学習モデリングのプロセス
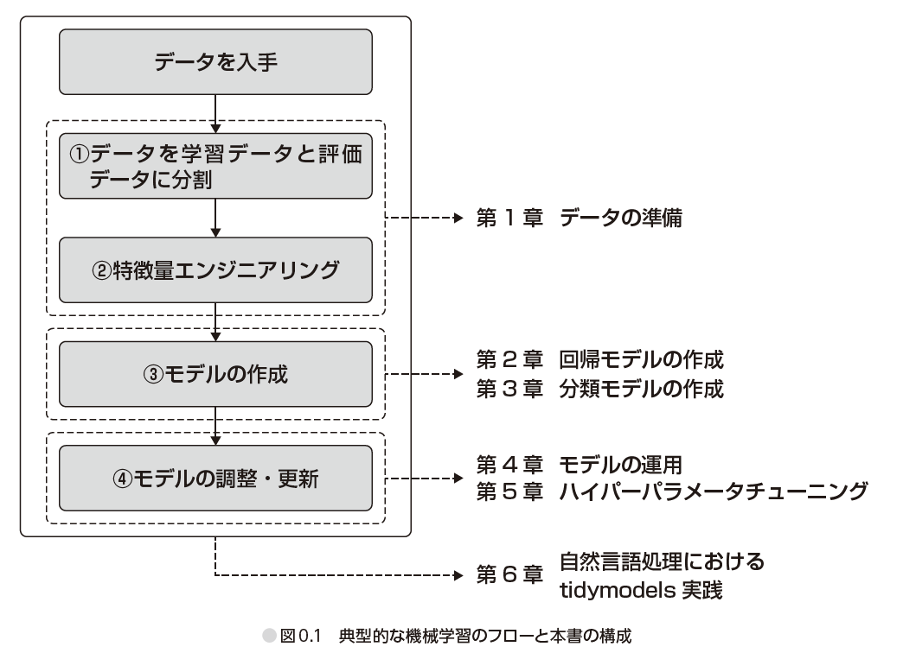
ではtidymodelsで具体的に何ができるのでしょうか。図1は一般的な機械学習モデリングのプロセスを示したもので「Rユーザのためのtidymodels[実践]入門」から転載しています。tidymodelsはこのプロセスをそれぞれ効率化するパッケージを用意しています。
図1 典型的な機械学習のフローと本書の構成
- ①データ分割
- ○ データを学習データと評価データに分割
- ○ 学習データをさらに分析セットと検証セットに分割する(交差検証法を用いる場合)
- ②特徴量エンジニアリング
- ○ 機械学習モデルの性能向上を目的にデータを整形する
- ○ 機械学習モデルに入力する形式にデータを変換する
- ③モデル作成
- ○ アルゴリズムを選択する
- ○ モデルを作成し、学習データを適用する
- ○ 学習済みのモデルに検証データを適用し、予測精度を算出する
- ④モデルの調整・更新
- ○ モデル作成のプロセスを繰り返し、予測精度の良いハイパーパラメータを決定する
- ○ 最終的なモデル作成
データの分割はモデルの性能を高くするうえで必要なプロセスです。tidymodelsではrsampleパッケージを用いて豊富な「①データ分割」手法を提供し、またrecipesパッケージを用いて「②特徴量エンジニアリング」を行います。これらの手順は「レシピ」を作成することで、さまざまな処理をオブジェクト化しておくことができます。
続いて「③モデル作成」です。Rにはさまざまな機械学習を行うパッケージが用意されており、それぞれの実行方法に違いがあり、すべてを把握することは困難です。そこで統一的な記述を可能にしたのがtidymodelsのparsnipパッケージです。同じように、yardstickパッケージを用いてモデルの良し悪しを評価します。
モデルは一度作って終わりではなく、モデルの性能を高めるために「④モデルの調整・更新」を繰り返し、予測精度を高くするハイパーパラメータを決めます。このプロセスにはtuneパッケージを用いてさまざまなハイパーパラメータを求める手法を提供します。
モデリングではさまざまなオブジェクトやコードが作られるため、これらを個別に管理するのは困難を極めます。モデルやコードを管理するためにworkflowsパッケージ、workflowsetsパッケージが用意されています。
本稿ではかんたんに機械学習モデリングのプロセスを説明してしまいましたが、各プロセスは試行錯誤の連続です。より直感的に操作でき、データ操作や可視化が得意なtidyverseと協調するようなモデリングを可能にするのがtidymodelsです。tidymodelsの詳しい利用方法については『Rユーザのためのtidymodels[実践]入門』を参照してください。