検索システムの普遍的構造
私たちの日常生活において、
検索とは、ユーザが入力したデータ
キーワード検索からベクトル検索へ
従来の検索システムの多くは、
これに対し、近年注目を集めているのが
ベクトル検索のメカニズム
ベクトル検索を実現するためには、大きく分けて
- ①ドキュメントのベクトル化
-
まず、検索システムはドキュメントの入力を受け付ける。ベクトル検索システムは、ドキュメントそのものを保存するだけでなく、各ドキュメントを実数の列である
「ベクトル」 に変換する。これをベクトル化 (エンベディング) と呼ぶ
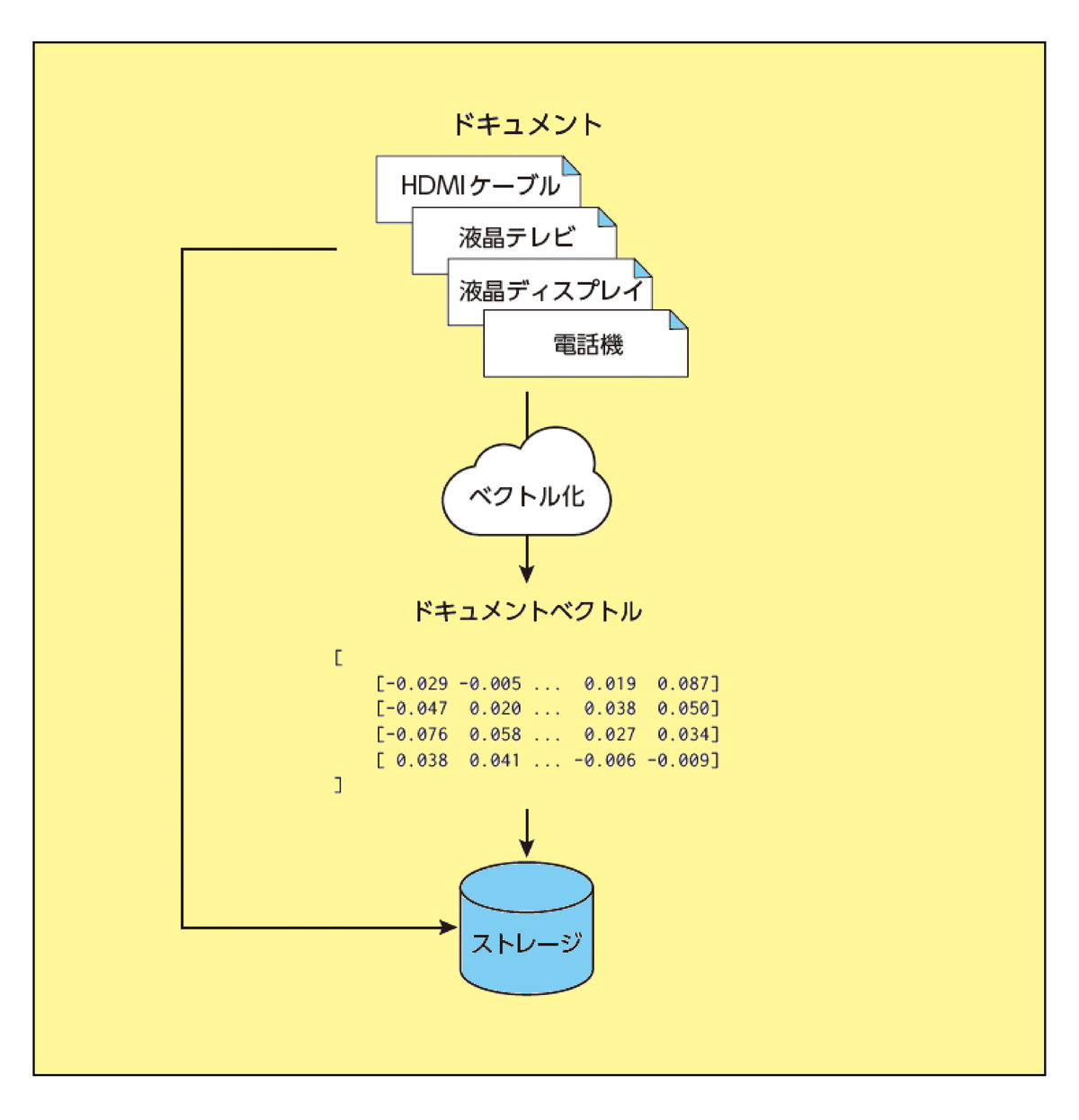
- ②クエリのベクトル化
- 次に、検索システムはクエリの入力を受け付ける。基本的にクエリの入力の時点で、それまでに入力されたドキュメントを対象として検索する。とくにベクトル検索システムでは、ユーザがクエリを入力した瞬間、システムはそのクエリ自体もドキュメント同様、ベクトル化する
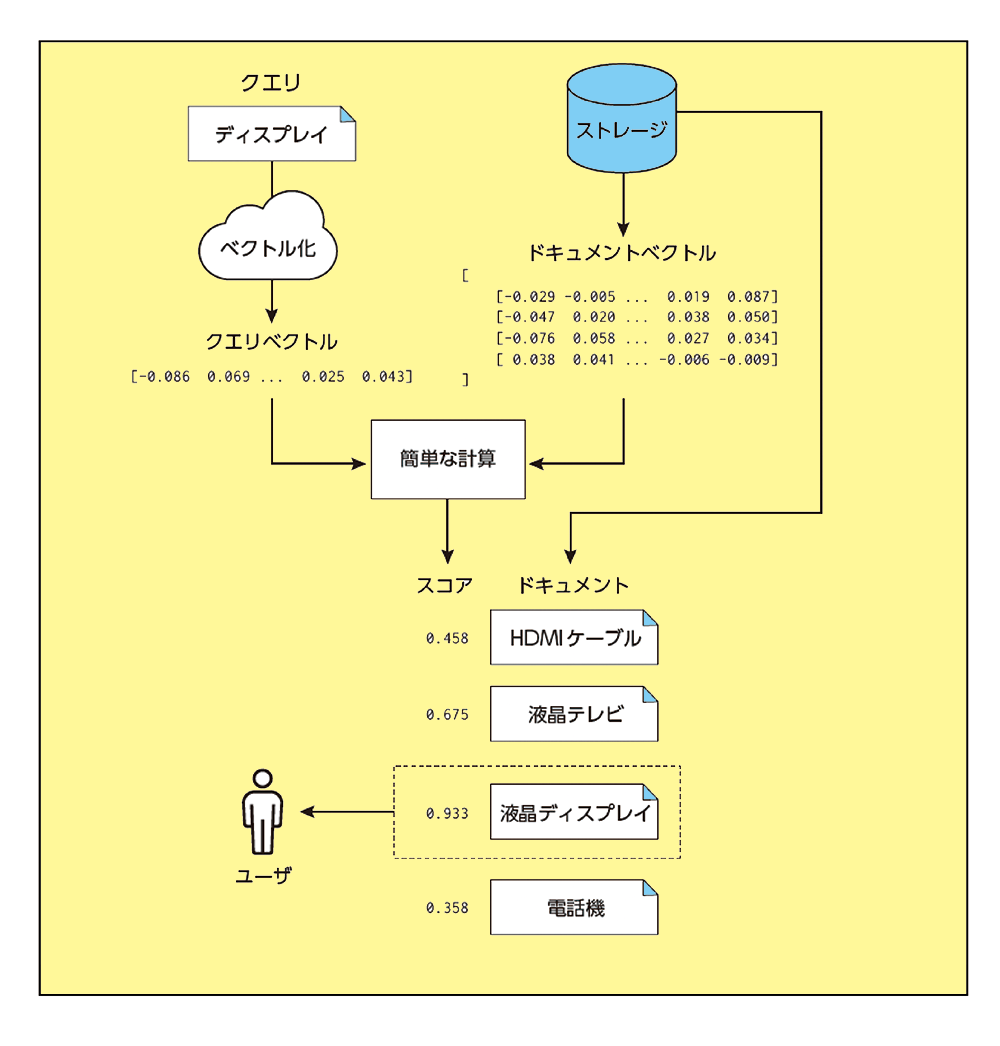
- ③スコアの計算
-
①で保存したドキュメントベクトルと、②で出したクエリベクトルとの間で、
「簡単な計算」 を行い、結果にもとづいてドキュメントごとにスコア (クエリとの関連度) を決める。あとは、スコアの高いドキュメントを優先的にユーザに返す
高次元ベクトルとLLM(大規模言語モデル)
実際のベクトル検索システムでは384次元や768次元など、高次元のベクトルが用いられます。クエリやドキュメントには多面的な性質があるので、高次元のベクトルに変換して扱うことで、性質をとらえやすくなります。
クエリやドキュメントはなんらかの言語で書かれています。その言語を理解することで、意味を考えることができます。したがって、言語で書かれたものを自動的に読解したり、記述したりするための技術である言語モデルがクエリやドキュメントをベクトル化する方法として広く使われています。LLMとの関係も深いです。
検索の未来
ベクトル検索は従来の重要技術キーワード検索を補完する技術であり、検索サービスはもちろん、Eコマースなど各種サービスの検索機能にも採用されつつある注目度の高い技術です。ベクトル検索のメリットは、クエリやドキュメントの
『ベクトル検索実践入門』
本書の著者
真鍋知博
LINEヤフー株式会社。
京都大学大学院情報学研究科社会情報学専攻情報図書館学分野に配属。情報抽出と情報検索を自身のテーマとする。博士
検索エンジンの高速化・
著書に