大規模言語モデル
- GPUを増やしたのに速度が上がらない
- モデルが大きすぎてメモリに載らない
- 推論のレスポンスが遅くサービスとして成立しない
こうした切実な課題に直面すると、限られた情報や時間の中で、試行錯誤を重ねながら解決を図らざるを得ないのが現実です。しかし、その過程が体系化されていない場合、解決までに想定以上の時間がかかってしまうことも少なくありません。
本書
- “計測ツールの使い方はマニュアルに書いてあるが、解析結果の解釈まで踏み込んだ説明は他に類を見ない”
- “最新のAI高速化技術が、日本語で読める幸せ”
- “現在のAI高速化の各種手法についてほとんど網羅されていて、辞書的にも使える”
以下では、本書の内容を要約して説明します。
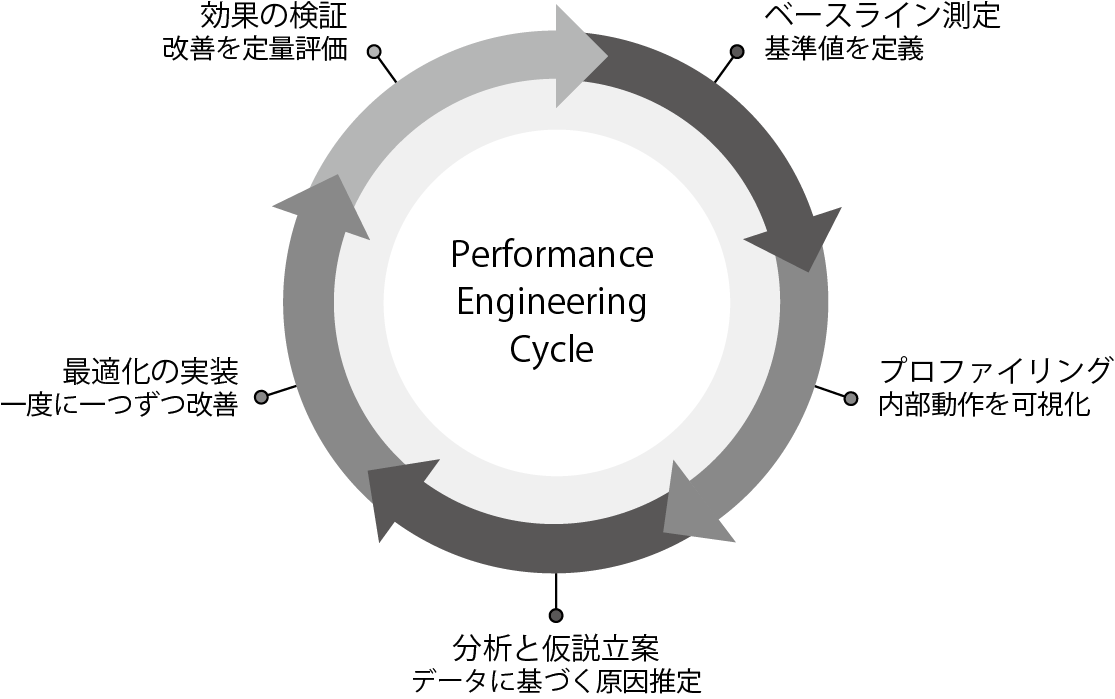
1.職人芸を「工学」へと昇華させる戦略的アプローチ
本書が定義するパフォーマンスエンジニアリングとは、単に
著者らのHPC
- ベースライン測定
- 正常な状態を定義し、基準値を測定する
- プロファイリング
- 計測ツールを使い、システムの内部動作を可視化する
- 分析と仮説立案
- 観測データから何が原因かという仮説を立てる
- 改善の実装
- 仮説に基づき、一度にひとつずつ変更を加える
- 効果の検証
- 改善を定量的に評価する
このプロセスを繰り返すことで、
2.推測するな、計測せよ——強力な計測ツール群とその結果の解釈
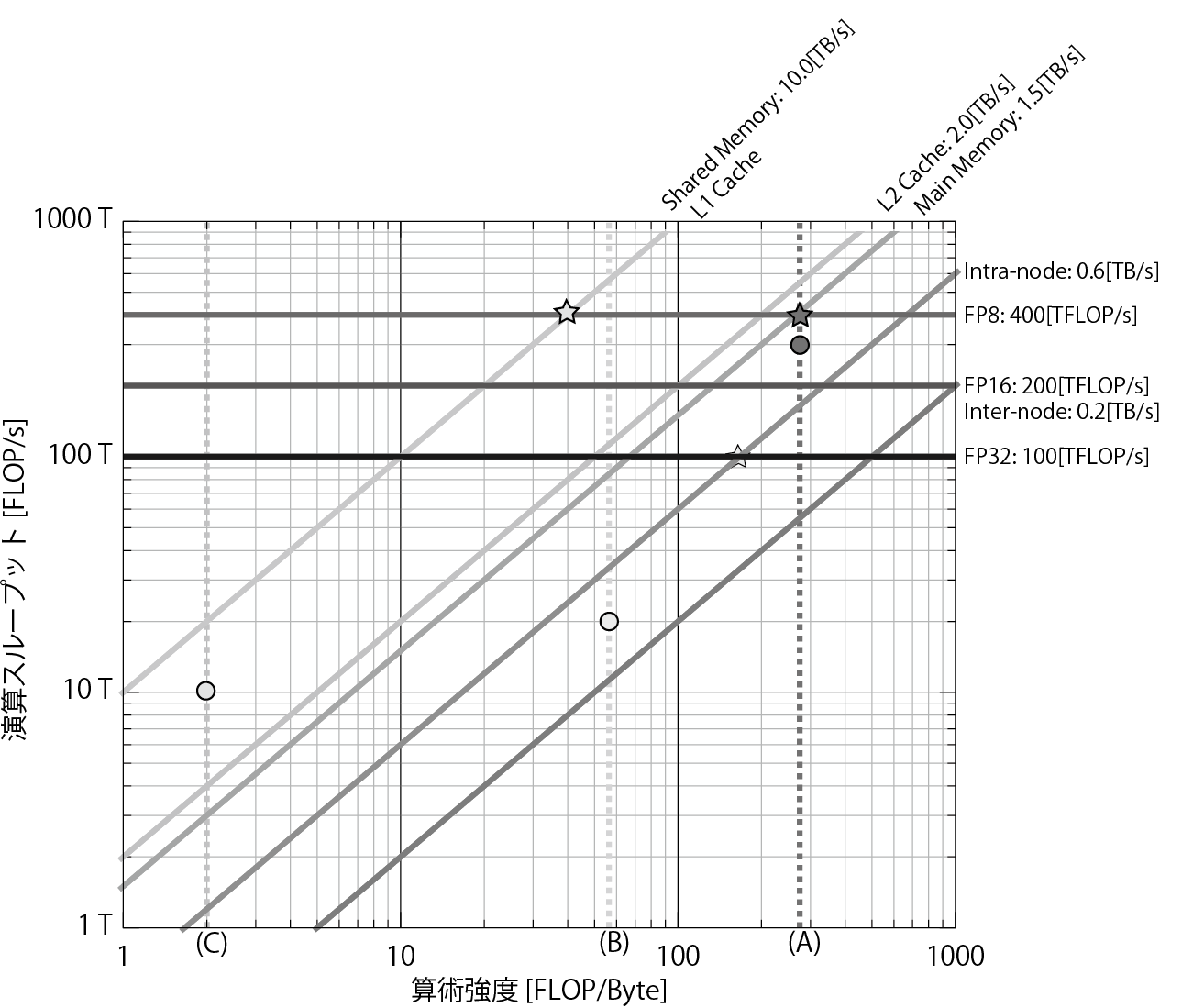
第2章では、パフォーマンス改善の第一原則である計測について、現場ですぐに使える具体的な手法を解説しています。
特に力を入れたのは、
また、システムの演算性能
3.多層的な視点から整理された改善手法のカタログ
第3章では、AI処理の改善手法がアプリケーション層に近い順に整理されています。これにより、読者は少ない手間の割に効果が大きい改善から優先的に着手できるようになります。
- フレームワークの選定
-
PyTorchのtorch.
compileによるJITコンパイルや、DeepSpeed、vLLMといった特化型エンジンの使い分け - モデル・
アルゴリズムの工夫 -
精度を維持しつつ計算量を削る
「枝刈り (Pruning)」や、データの表現幅を縮小する 「量子化 (FP8/ INT8)」など - 分散並列の極意
-
大規模モデルに不可欠な分散並列の5つの手法
(データ・ テンソル・ パイプライン・ コンテキスト・ エキスパート並列) の詳細と、それらをどのように組み合わせて (ハイブリッド並列) 最高性能を引き出すかの理論的解説 - メモリ効率化
-
GPUメモリの冗長性を排除するZeRO
(Zero Redundancy Optimizer) ステージ1〜3の仕組みや、KVキャッシュ管理を劇的に効率化する PagedAttentionの活用 - 通信の隠蔽
-
データの先読み
(プリフェッチ)、DMA (Direct Memory Access)、非同期通信などの技術を用いてデータ通信にかかる時間を演算の裏に隠蔽し、GPUの演算効率を上げるパフォーマンス改善手法の説明
それ以外にも、高速ライブラリの活用、ハードウェアに合わせた調整についても説明します。
4.実践への架け橋:Llama3とBEVFusion
本書は単なる理論書に留まりません。第4章以降では、以下のような具体的な対象をステップバイステップで高速化する事例を挙げて解説しました。
- Llama3
(LLM) - 代表的な大規模言語モデルを対象に、推論、事後学習、そして数千億パラメータ規模を見据えた事前学習におけるパフォーマンスエンジニアリング。
- BEVFusion
(自動運転AI) -
異なるセンサー
(カメラ、LIDAR) の情報を統合し、高精度な3D物体検出を実現するAIモデルの学習の高速化。また、リアルタイム性が要求されるエッジデバイス (NVIDIA Orinなど) 上での推論高速化。
前半
生成AIの進化スピードは極めて速く、特定のバージョンや設定値はすぐに陳腐化するかもしれません。しかし、本書が提示する
2024年に行われた調査では、GPUのピーク使用率が85%を超えている企業はわずか7%であり、多くの高価な演算リソースが遊休状態にあるという事実が指摘されました[1]。これは、パフォーマンスエンジニアリングを習得した技術者には、組織の競争力を劇的に高めるチャンスが広がっていることを意味します。
ぜひ本書で解説された手法を実践し、あなたの向き合うAIシステムの性能を100%引き出すエンジニアリングを体得してください。
本書の著者
浅原明広
ハワイ・