コンテキストエンジニアリングと聞いて、何を想像するでしょうか。会話履歴の圧縮? プロンプトエンジニアリング? キャッシュ管理? 恐らくLLMに関わる人なら名前くらいは聞いたことがあるものの、発信元によってその説明には揺れがあると思います。その1つの原因は、そもそもコンテキストという言葉自体の理解が、市場でやや不十分であることが挙げられます。
コンテキストとは
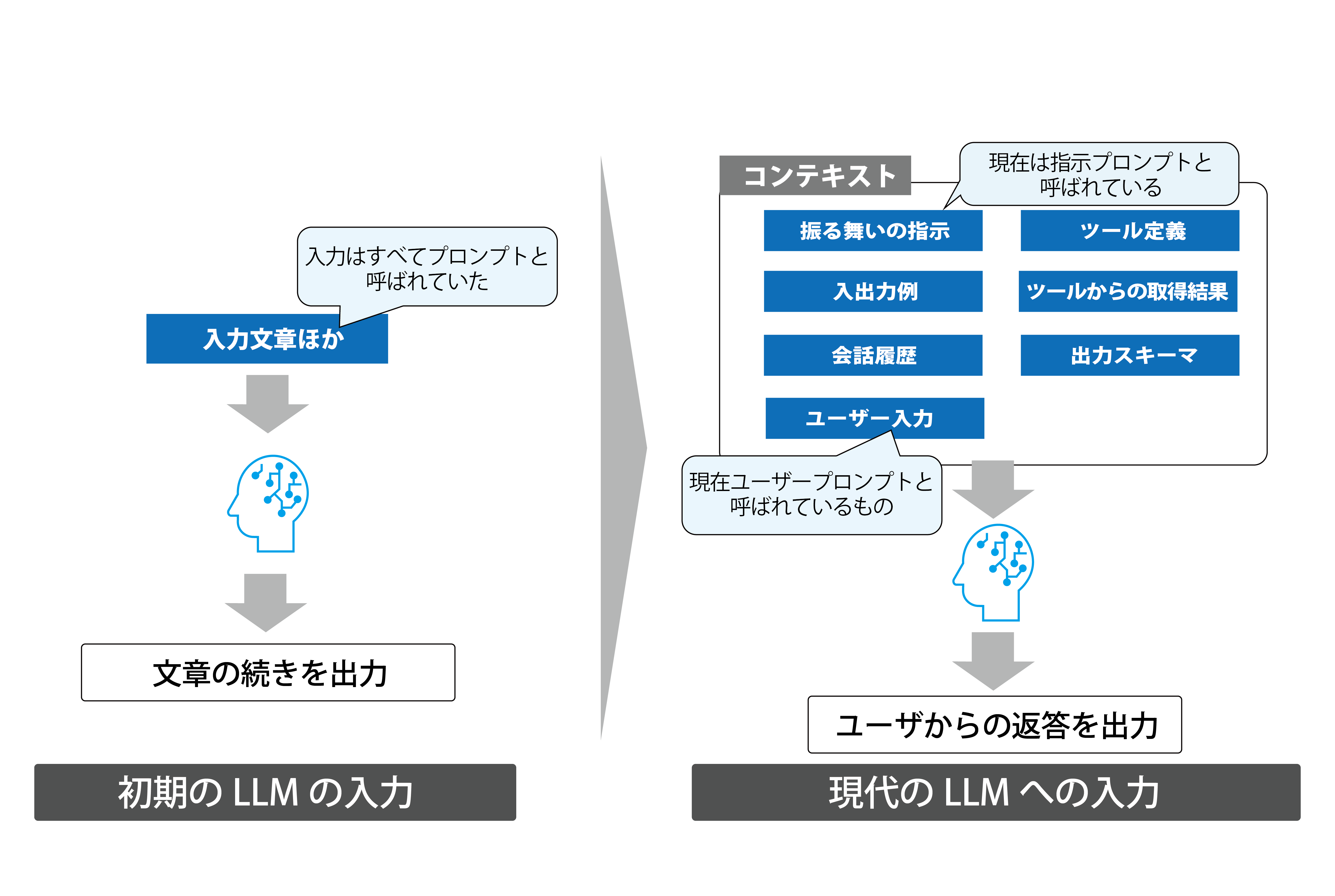
コンテキストは簡単に言えばLLMへの入力テキストです。単に入力テキストというとプロンプトのイメージが強いかもしれません。実際、ChatGPTのような対話型LLMの普及が始まった前後では、LLMへの入力は一様にプロンプトと呼ばれていたように思います。しかしながら、LLMの発展に伴い入力テキストは多様化。サービスの固有の振る舞いを規定する指示、LLMに使わせるツールの定義やその結果、システム連携のための出力スキーマ指定など、ユーザーから見えている入力欄の他にも、多様な情報が静的・
一方のプロンプトの呼称は、プロンプトエンジニアリングの爆発的な流行を背景に、単なる入力テキストではなく、とくに
結果的に、現代のLLMのように多様な入力情報を含むテキストはプロンプトとは区別され、現在では
コンテキストを取り巻く問題
LLMにとっては非常に重要なコンテキストですが、LLMに求められる役割とタスクの複雑性の増加に伴い、さまざまな問題が指摘され始めています。
- 精度劣化
コンテキストが大きくなることで、出力の品質悪化やタスクの手順、使うツールの誤りなど、LLMの本来の賢さや正確性がすぐに維持できなくなることは、恐らく誰しも経験があると思います。 - コンテキストウィンドウの制約
LLMには入力できるコンテキスト量に限界があります。昨今増えてきたコードリポジトリの解釈やAgenticな検索によって、しだいにこれが限界量に達してしまい、LLMが動作できなくなることがあります。 - コストや速度などの非機能面への影響
LLMのAPIは入出力のテキスト量に応じて課金が発生します。不必要に膨らんだコンテキストが思わぬコスト増につながったり、また計算量がいたずらに増加したりすることで、ユーザーの待機時間が延びてしまうなどの問題につながります。
コンテキストエンジニアリングの正体
上記の問題をふまえ、LLMアプリケーションの開発や、LLMのハンドリングをするうえで、コンテキストを有効に扱うさまざまな技術が生まれてきています。
LLMが最も質の高い回答を返すために、限られた入力領域において、何を与え・
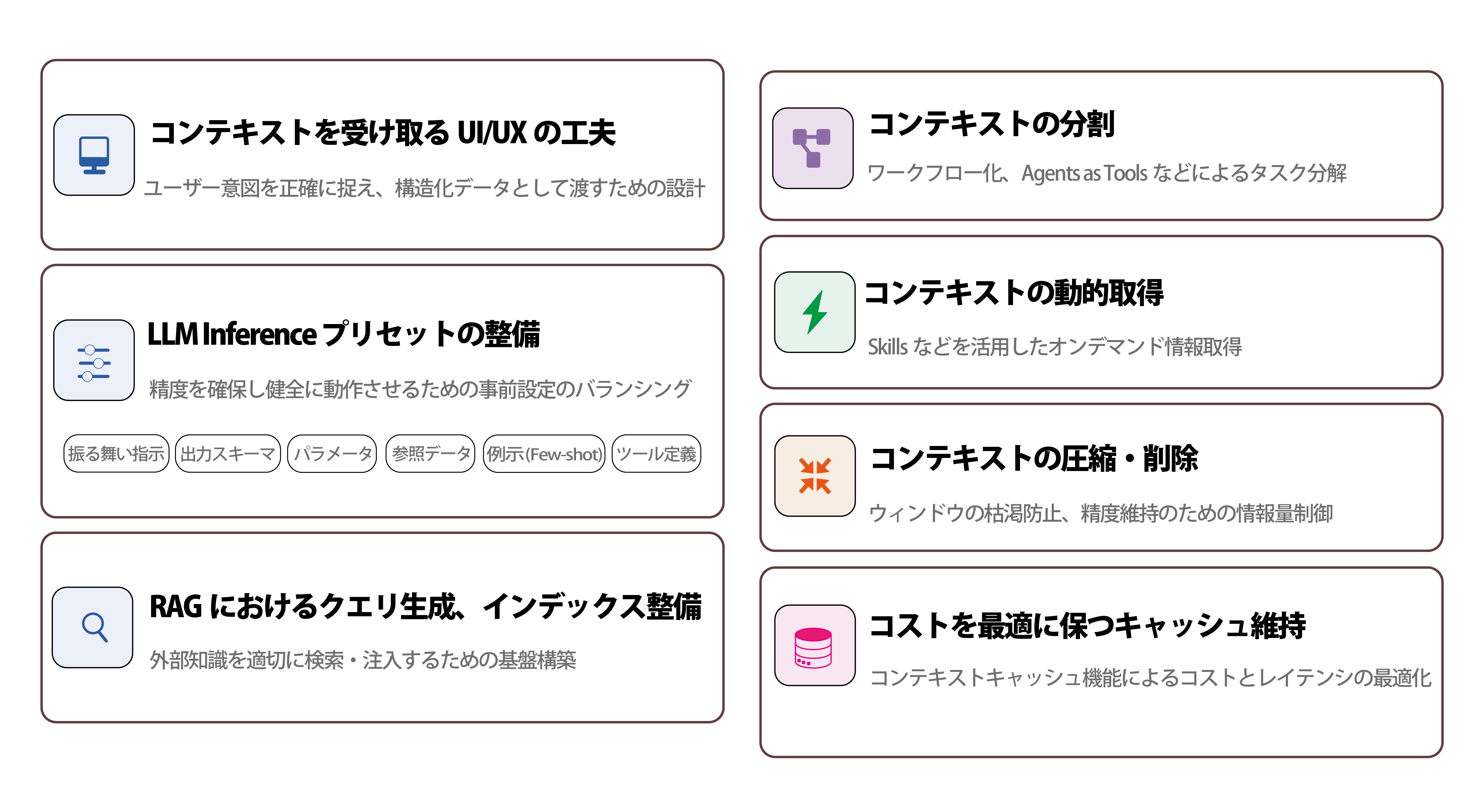
コンテキストエンジニアリングはLLMサービスの品質や業務自動化の精度にダイレクトに影響します。同じモデルを使っていても、良い結果を出力できるサービスとできないサービスが分かれるのはこのためです。基本的にはコンテキストに関わる技術全般が含まれるため、プロンプトエンジニアリング、RAG、会話履歴の圧縮技術、ツール定義の肥大化対策など非常に広い範囲の技術が存在します
LMやAPIの仕組みから、本質的にコンテキストを理解する
コンテキストエンジニアリングにはSkillsのような比較的新しい技術も含まれますが、基本的にはLLMアプリケーションの開発の現場で熟練者が使い古してきた暗黙知を新たにカテゴライズしたものと言えるでしょう。本書
単にコンテキストエンジニアリングの各技術を、手法ベースでカタログ的に紹介することもできましたが、恐らくそれは一時的なコンテキストに対する問題の対策にはなっても、この流れの速いLLMの技術領域においてはすぐに陳腐化してしまうでしょう。
書籍を通じて読者が、仮に今後新たな技術や機能が登場したとしても、その源流がどこにあり、何を目的にしたものであるのかが理解できるようになること。また、SNSで騒がれるような——たまに少し怪しげな——手法に惑わされず、目の前の開発において意味があるかないかを自ら判断できるエンジニアが1人でも増えることが、本書を執筆したときの願いです。恐らくこれらのことが理解できれば、LLMアプリケーションを開発するときだけでなく、ユーザーとしてLLMを駆使するときのハンドリングも根拠を持ったものとなるはずです。
LLMを扱ううえでの最も重要でベーシックな存在であるコンテキスト。あらためてその扱いを定義し、今後長く続くLLM技術とともに生きるための地力を身に付けておきませんか。
本書の著者
蒲生弘郷
外資系IT企業所属のクラウドソリューションアーキテクト、エバンジェリスト。上智大学大学院 応用データサイエンス学位プログラム 非常勤講師。大手システムインテグレーターにてキャリアをスタート。社会インフラ関連領域のデータサイエンティストとしての活動、ブロックチェーンを活用した異業種間データ流通サービスの立ち上げなどを経て現職へ。ChatGPTの登場した2022年以来、Azure OpenAI Serviceなどを使ったLLMアプリケーションの構築支援・ 𝕏: @hiro_