テキストを入力するだけで、自分が想像する世界を表現できる。まるで“現代の魔法”とでもいうべき「画像生成AI」の技術が、いま世界中に驚きを与えています。
図1 筆者が複数の「画像生成AI」で生成した画像のまとめ。プロンプトの書き方やモデルの違いで生成される画像はだいぶ異なる

2021年から2022年にかけて、「Text-to-Image」と呼ばれる、テキストから画像を生成する「画像生成AI」モデルが、多くの団体や企業から発表されました。今年5月以降、こうしたモデルの多くが、誰でも試せるデモ版やウェブサービスとなって提供され始めました。
公開されたサービスを実際に使ったユーザーが、生成画像の質の高さや可能性を目の当たりにしたことで、現在もSNSを中心に多くの画像が生成され、そのAI技術が拡散されています。
「画像生成AI」の代表的なモデル
公開された「画像生成AI」の各モデルは、大まかな仕組みは変わらないものの、どれもが“個性”とも言うべき特徴を持っています。ここでは、実際に話題となった4つのモデルを紹介します。
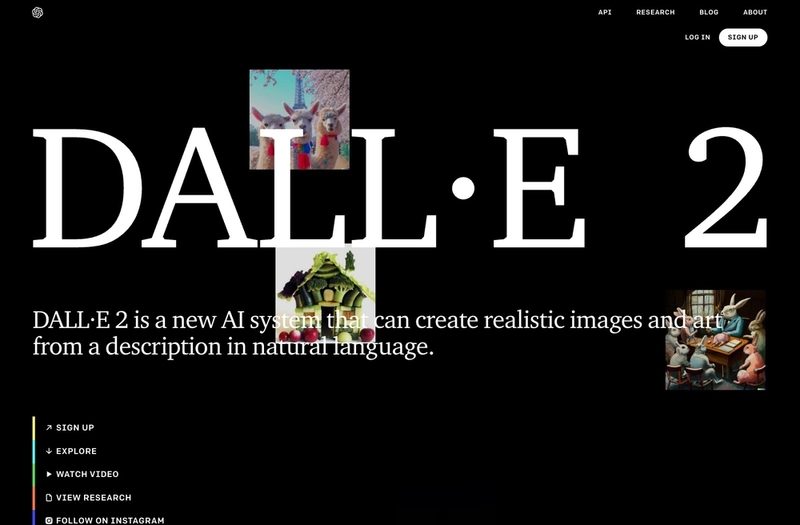
DALL·E2
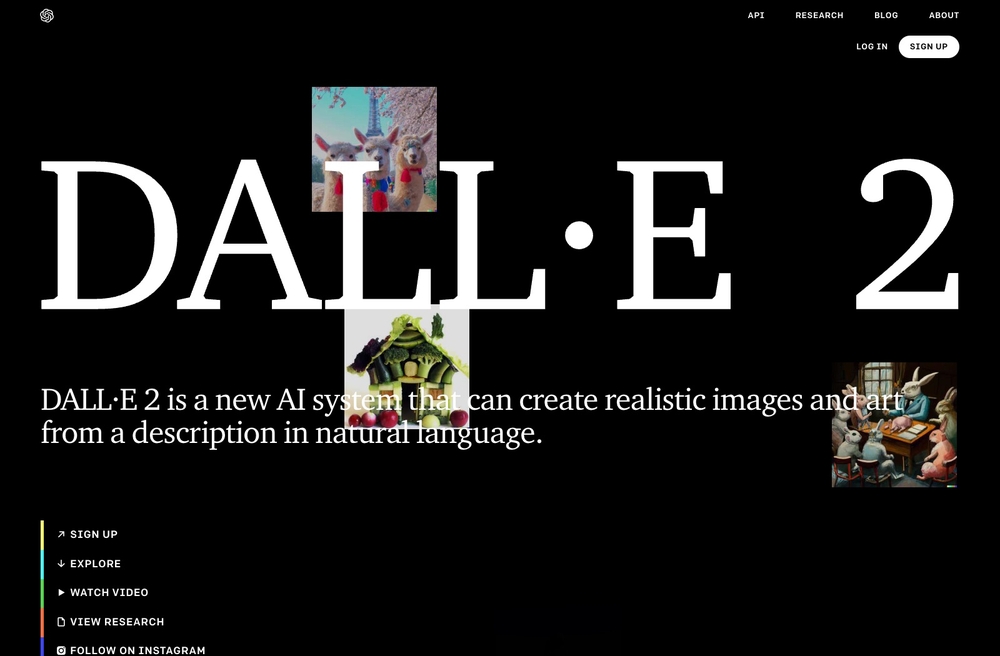
「DALL·E2」は、テスラのCEOイーロン・マスクらが出資して設立された人工知能を研究する非営利団体、OpenAIによって開発されたモデルです。2021年に発表された「DALL·E」の発展型で、テキストを記述するとAIが画像を生成します。今年4月に招待制となり、7月20日にベータ版が公開されました。
図2 「自然言語による記述からリアルな画像やアートを作成することができる」という説明文が流れる、非営利団体OpenAIが開発した「DALL·E2」のウェブサイト
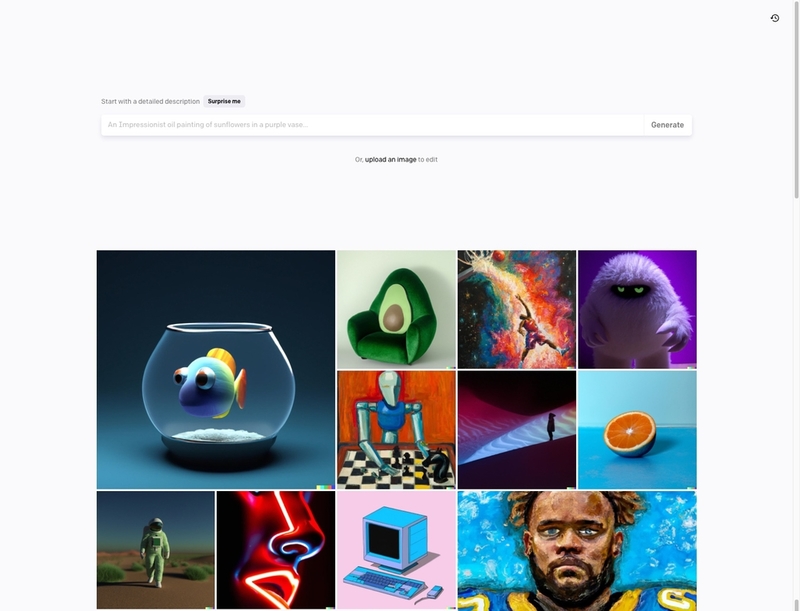
アカウントを作成すれば、「DALL·E2」はすぐ利用できます。利用開始時には、画像生成に必要なクレジットが与えられます。クレジットは画像の生成、機能の利用で消費されますが、毎月無料で一定量が付与されます。使い切った場合でも、クレジットを追加購入できます。
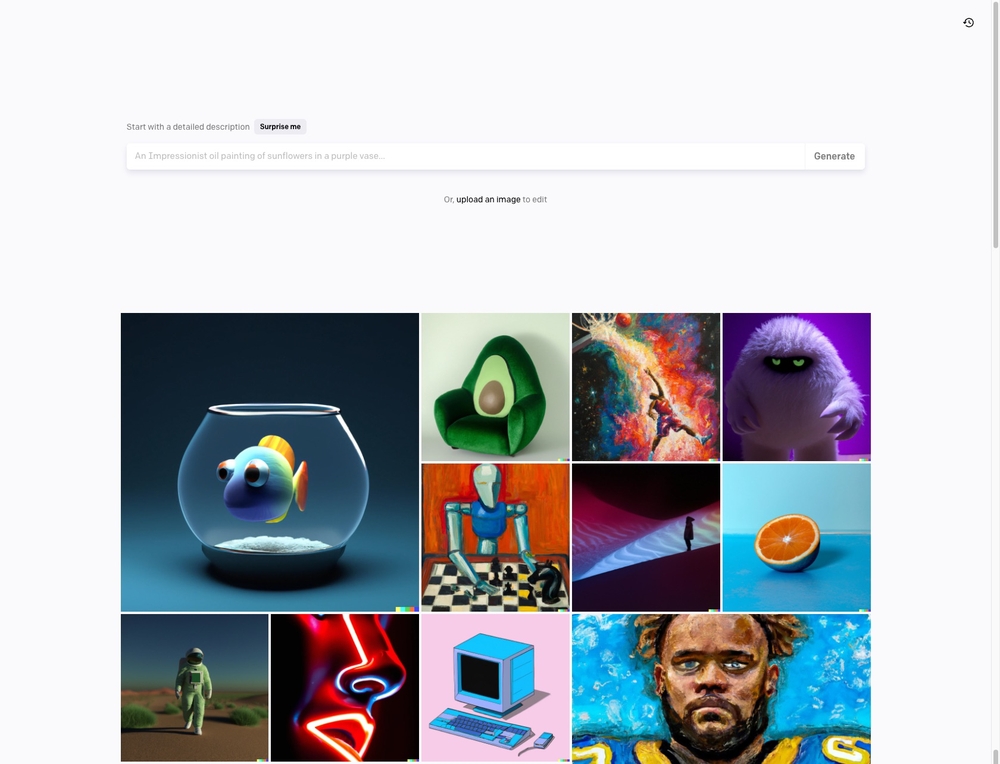
図3 「DALL·E2」の画像制作画面。上部のテキストボックスにプロンプト(テキスト)を入力して画像を生成する
「DALL·E2」には、「Outpainting」と呼ばれる、画像の表示範囲外をAIが自動的に描画する機能があります。この画像生成AIの圧倒的な力を感じさせる機能を使った作品も多く、最近ではNestleのCMに採用され、話題となりました。
動画1 フェルメールの「牛乳を注ぐ女」をブランドイメージに使っているNestle Franceの乳製品デザート「La Laitiere」のCM。「Outpainting」による画像拡張の様子がよくわかる
不要な部分を指定して再描画させる「Image Editing(ベータ版)」や生成した画像をベースにして別の画像を生成する「Variation」、自分の生成画像を一覧できる「My collection」など、使いやすい機能が特徴です。
実際に画像生成した感想としては、プロンプトを“正直”に解釈するので、生成される画像予測がしやすく、アート系の表現には強みがある印象です。悪用防止のため、実在の人物や暴力的な画像などは生成できないよう制限がかけられていますが、生成した画像は、全使用権(転載権、販売権、商品化権)を取得でき、商用利用も許可されています。
Midjourney
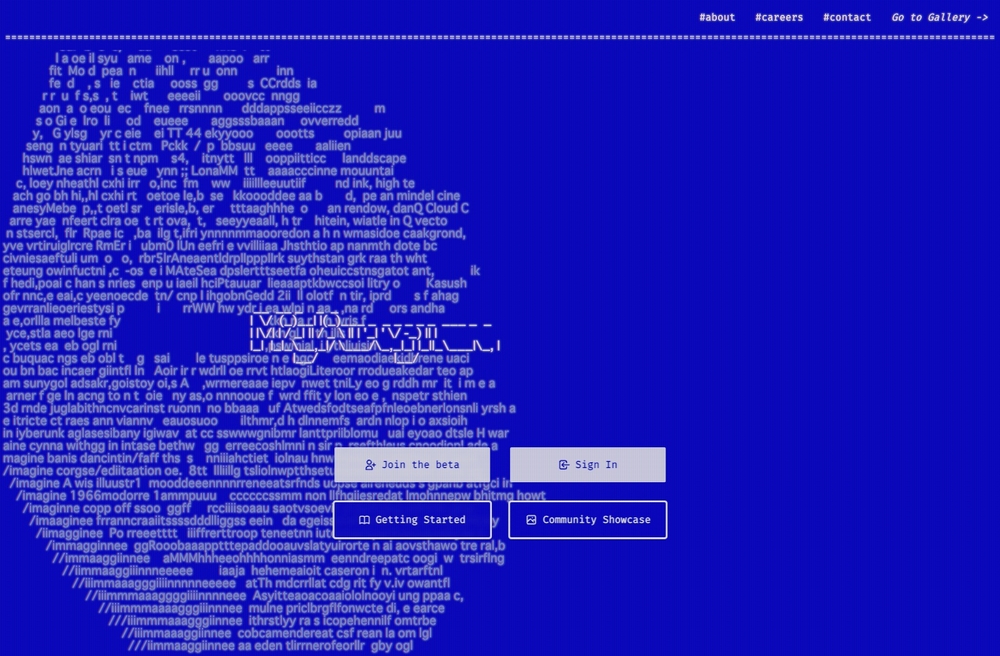
「Midjourney」は、「Text-to-Image」の人工知能モデルを製作している同名の研究所による画像生成AIサービスです。2022年7月12日にオープンベータとしてサービスを開始。すでに収益を上げており、ビジネスとしても成功を収めています。
図4 「Midjourney」のウェブサイト。わずか10数人の小さな企業による「画像生成AI」だが、すでにビジネスとして成功を収めている
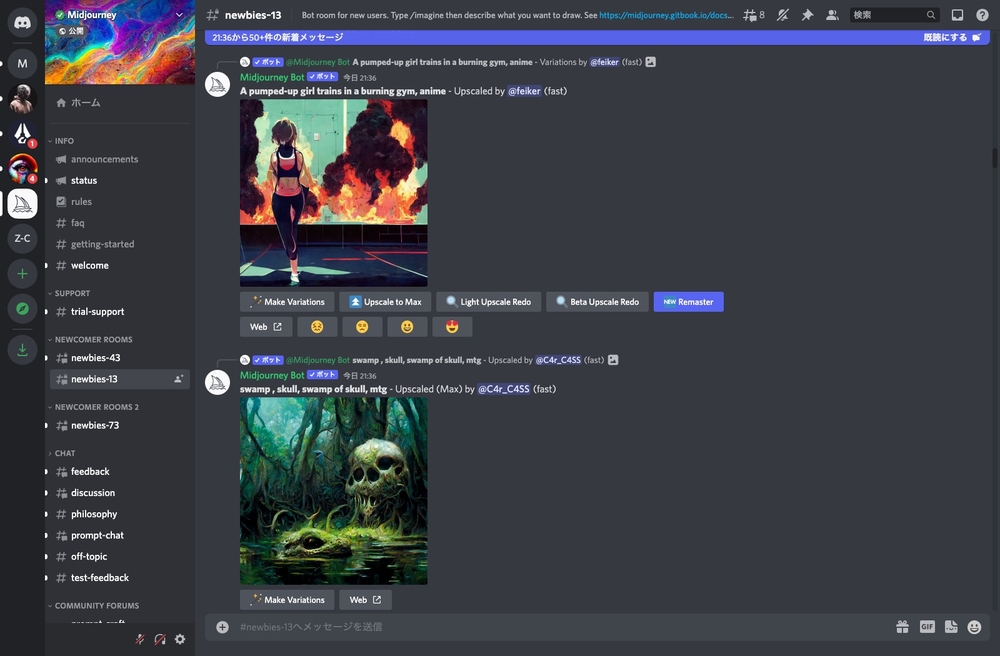
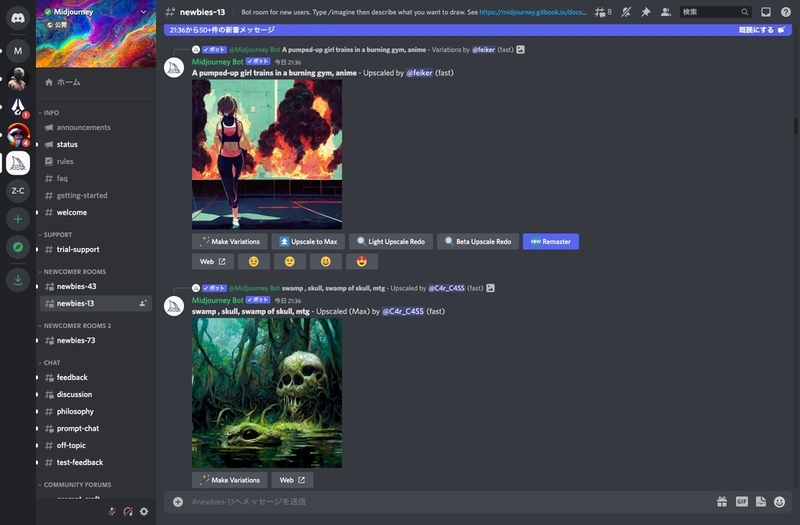
「Midjourney」を利用するには、コミュニケーションサービス「Discord」への登録が必要です。画像生成は「Discord」内の指定チャンネル内でプロンプトを入力して行います。利用開始時に約25回分の画像生成時間が付与され、無料の画像生成時間を使い切った後は、用意されているサブスクリプション会員への加入が必要になります。
図5 「Discord」内の「Midjourney」サーバ。指定された「#newbies」チャンネル内でプロンプトを入力して画像作成を行う
サブスクリプション会員は「Basic」(月額10USドル)、「Standard」(月額30USドル)の2種類です。付与される画像生成時間の量で料金が異なりますが、「Standard」では回数制限なく画像生成が可能です。追加料金(月額20USドル)を支払えば、入力するプロンプトを非公開にできるオプションも用意されています。
画像生成後に高解像度化したり、バリエーションの作成も可能です。画像生成のベースとなる画像の指定やプロンプトのワードの重み付けなど、すでにビジネスとして成立しているサービスだけに、ユーザー向けの細やかな機能が多数実装されています。
実際に画像生成した感想としては、プロンプトが“ダイナミック”に解釈され、独特の色彩演出と効果が加わり、「Midjourneyで生成した」とすぐわかる見栄えの良い画像が出てくる印象です。有料会員サービスを利用すれば、生成した画像の商用利用が認められています。
Stable Diffusion
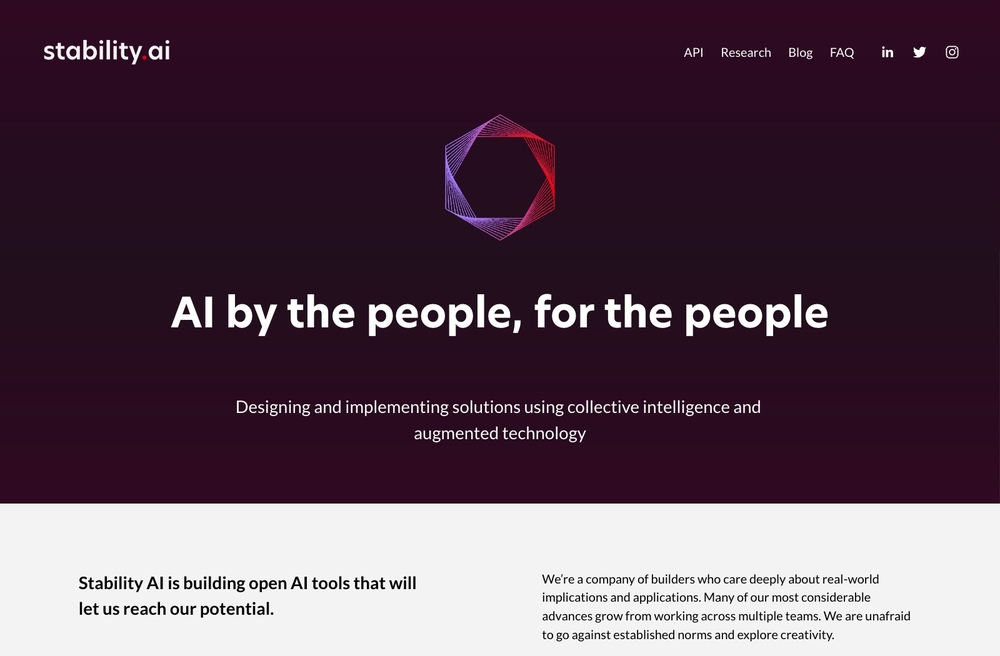
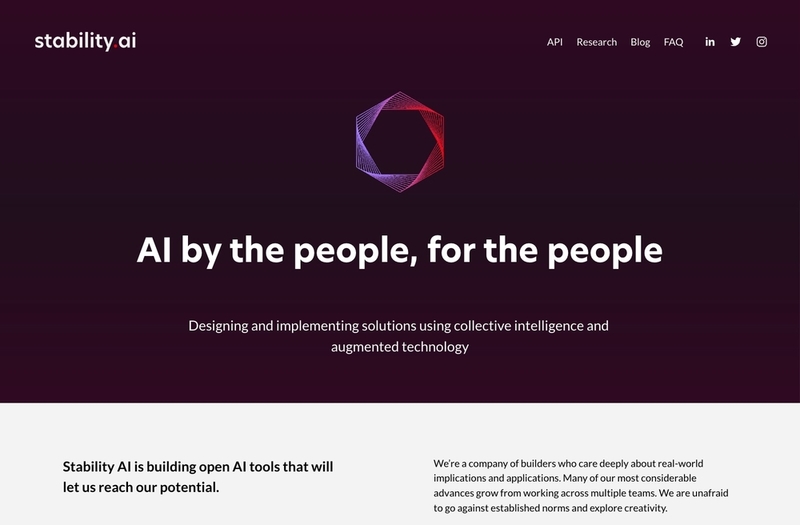
「Stable Diffusion」は、イギリスのStability Aiがオープンソース化して、2022年8月22日に一般公開したモデルです。コードはオープンソースコミュニティ「Hugging Face」で公開されているため、モデルのカスタマイズやモデルを組み込んだ新たなサービスが次々と誕生しています。
図6 「Stable Diffusion」を公開した「Stability Ai」のウェブサイト。画像生成AIの「Stable Diffusion」以外にも、言語や音声、映像や3D用のオープンなAIモデルを開発中
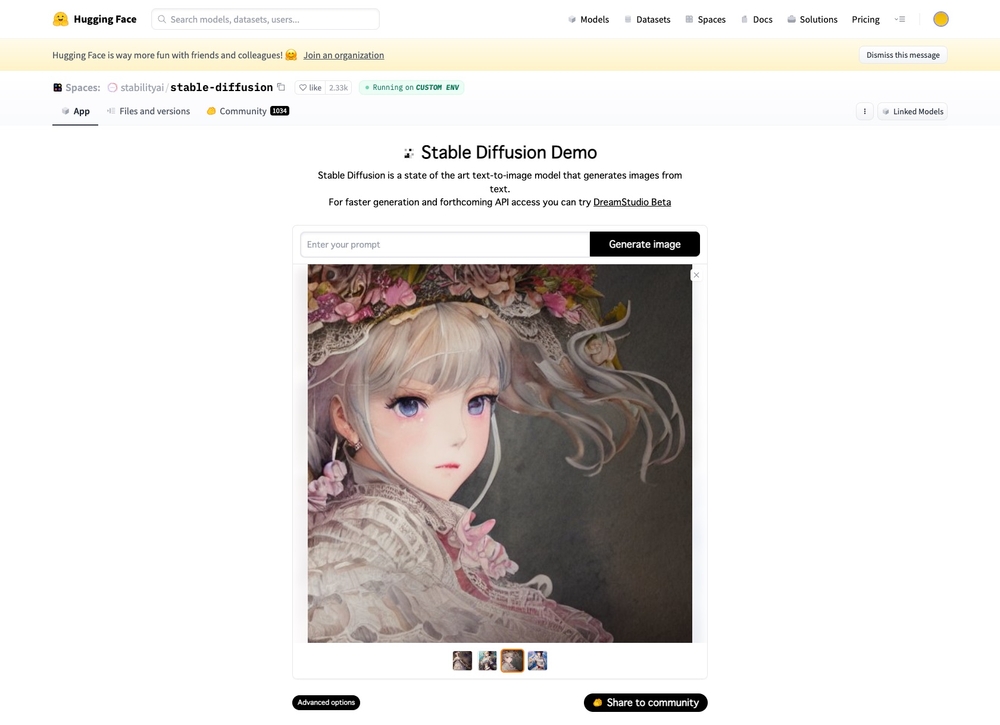
自分の環境に合わせて、ユーザーが利用方法を自由に選択できるのも「Stable Diffusion」の特徴です。試すだけなら「Hugging Face」で公開されているデモ版にプロンプトを入力すれば、すぐ画像が生成できます。
図7 「Hugging Face」で公開されている「Stable Diffusion」のデモ版。プロンプトを入力すれば、すぐ画像が生成できる
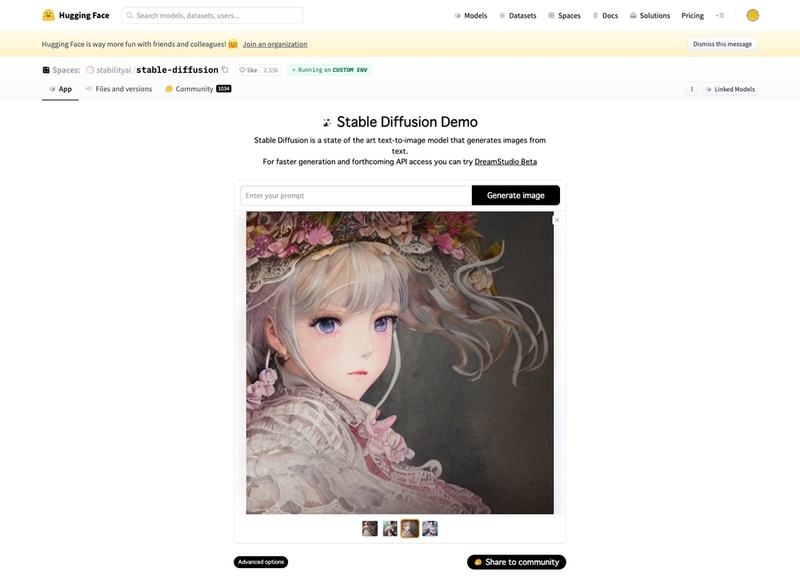
公式サービス『DreamStudio』は、会員登録後に無料で画像生成のクレジットが付与されます。従量制サービスのため、生成される画像の画質やサイズなどで消費されるクレジットは異なり、利用分だけクレジットを購入(約1000枚で10ポンド)することになります。
動作条件を満たすGPUを搭載したPC環境を整えれば、「Stable Diffusion」はローカルのPC上でも動作します。この場合、無料で制限なく画像生成が可能です。ブラウザ上でPythonを実行できるGoogleのサービス「Google Colaboratory」上でも動作するので、ローカルのPC環境が整わない場合も問題ありません。
「Stable Diffusion」の最大の特徴は、誰でも使用できるようオープンソース化されていることです。用意されたAPIを使った、画像生成できるスマートフォン用アプリ「AIピカソ」やウェブサービス「Memeplex.app」、モデル内の機能の拡張や特定の学習データを使ったジャンル特化型モデルの公開など、ユーザーのアイデアによるカスタマイズ例が数多く公開されています。
実際に画像生成した感想としては、プロンプトを“素直”に解釈して、写実的な表現からイラストやアニメのような画像まで、無難にこなす万能タイプという印象です。生成された画像の公開者が全責任を負うことで、商用使用を許可しています。
ERNIE-ViLG
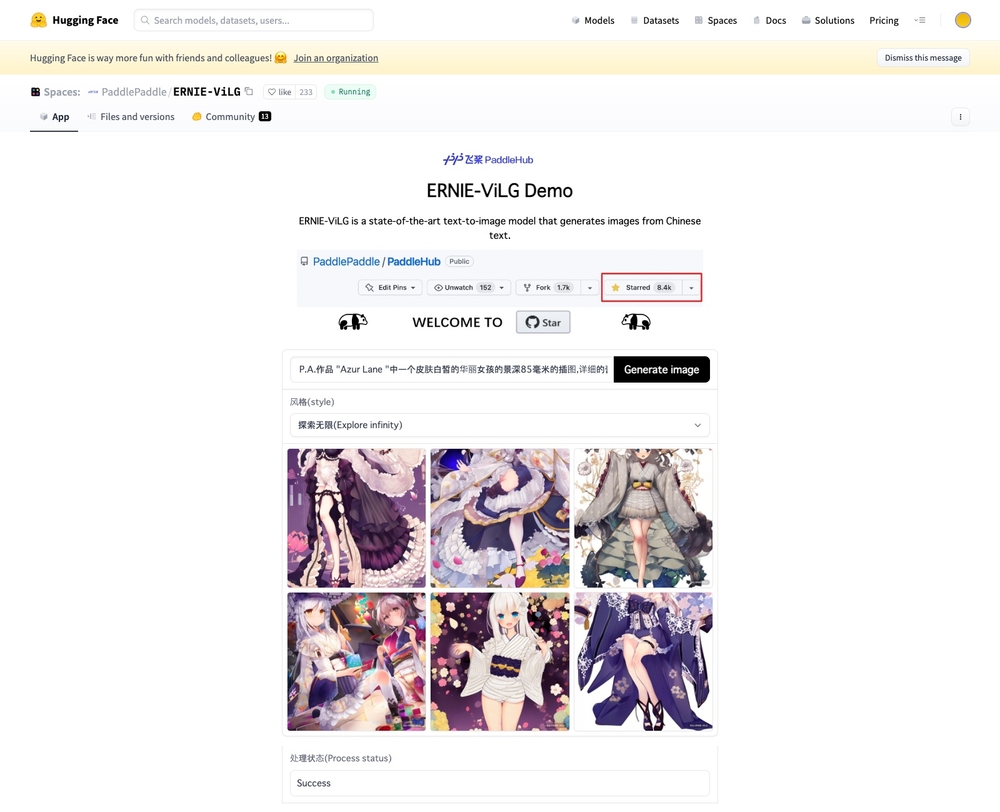
「ERNIE-ViLG」は、2021年に中国のIT企業、Baiduが発表した画像生成AIです。論文は以前から発表されていましたが、今年8月30日にオープンソースコミュニティー「Hugging Face」上でデモ版を公開しました。
図8 「ERNIE-ViLG」のデモ版も「Hugging Face」で公開されている。プロンプトを入力すれば、すぐ画像が生成できる
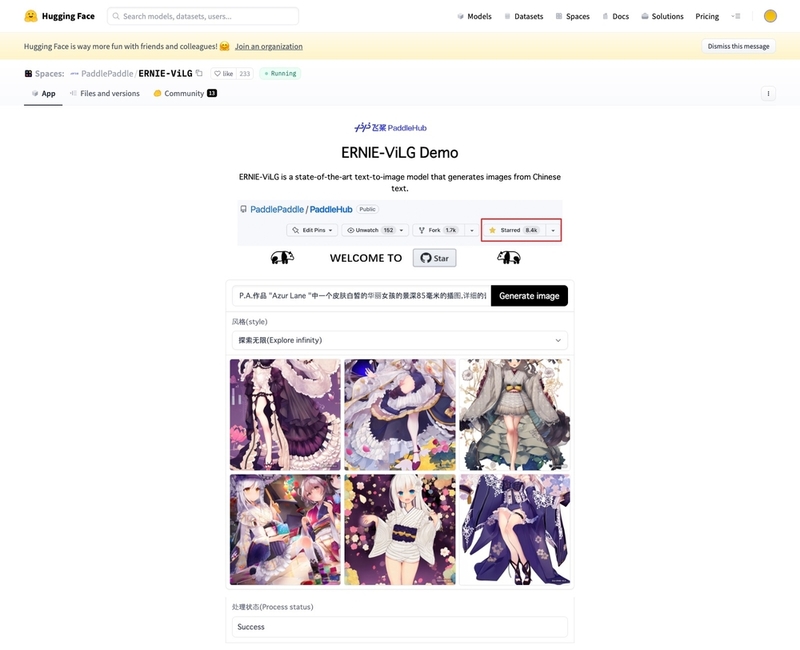
「ERNIE-ViLG」も、ローカルPC環境や「Google Colaboratory」上で動作可能です。プロンプトは中国語での入力が推奨されているため、翻訳する手間がありますが、「Hugging Face」で公開されているデモ版であれば、ブラウザからすぐ使用できます。
実際に画像生成した感想としては、日本のイラストサイトなどで見かける「美少女」「かわいい」系の高品質画像が、簡単なプロンプトで生成できる点に驚きました。それ以外の表現については、どれも無難にこなせる印象です。
どうやって画像生成AIから作品が生まれるのか
画像生成AIモデルから画像を生み出すには、どのような作業が必要なのでしょうか。「Text-to-Image」の代表的なモデルを使い、毎日1〜2時間程度の画像生成を約一週間、実際に行ってみました。テーマを「アニメ風の女性」と決めて、「生成する枚数が大量になる」と考えたため、AI画像生成モデルは「Stable Diffusion」を選択。筆者のローカルPC環境は非力なため、「Google Colaboratory」でモデルを実行させながら、画像を生成します。
まず「Stable Diffusion」の基本マニュアルを読んで、プロンプトの基本的な書き方を学びます。その後、筆致やスタイルに関して調べながら、自分が生成したい画像に利用できそうな芸術関連の知識や名称を集め、プロンプトを作成します。画像生成作業を始めて感じたことは「単語と画風を並べるだけでは、思い通りの画像は生成されない」ということでした。
図9 筆者が「Stable Diffusion」で初日に生成した画像。とにかくプロンプトに書いたワードが画像に反映されない

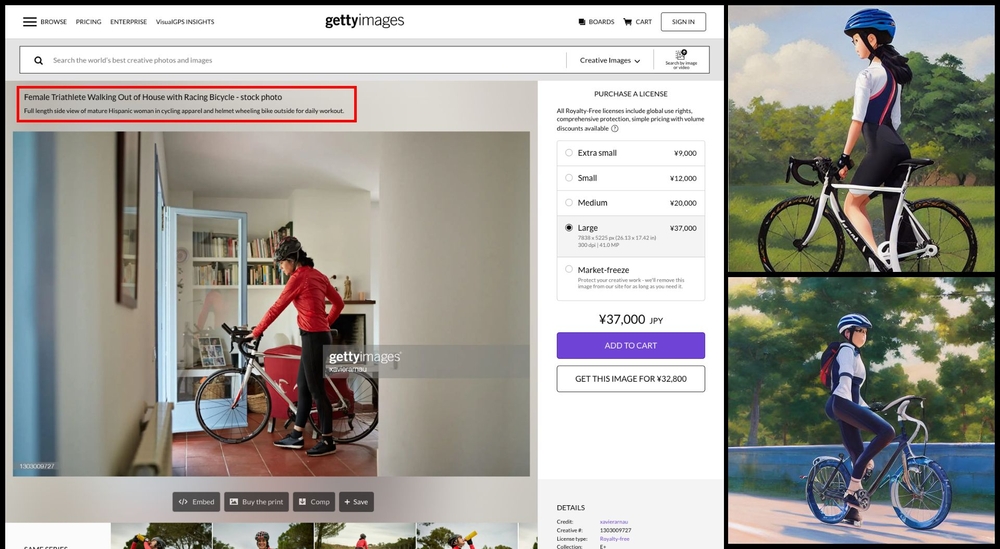
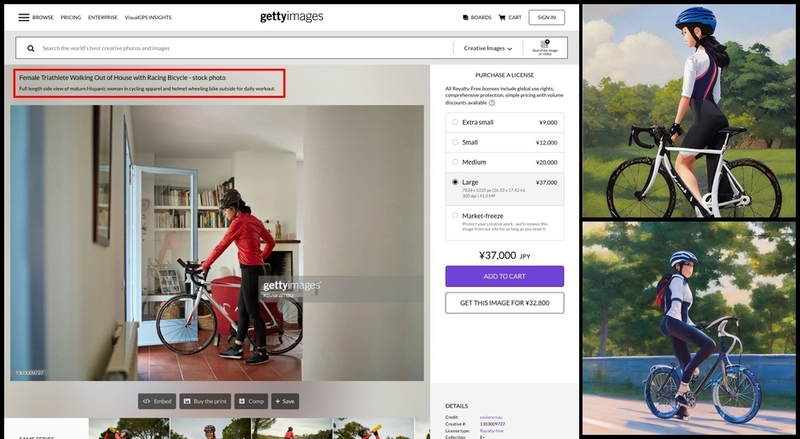
そこで、求める画像に似たものを探し、公開されているワードをプロンプトに少しづつ加えていくことを始めました。構図については、ストックフォトサービスなどに書かれているキャプション(画像の説明文)を参考に、ワードを組み立てます。
図10 ストックフォトサービスの「gettyimages」などの画像(左側)に書かれた写真の説明文(赤枠部分)を参考にプロンプトを組み立てて画像を生成した結果(右側)
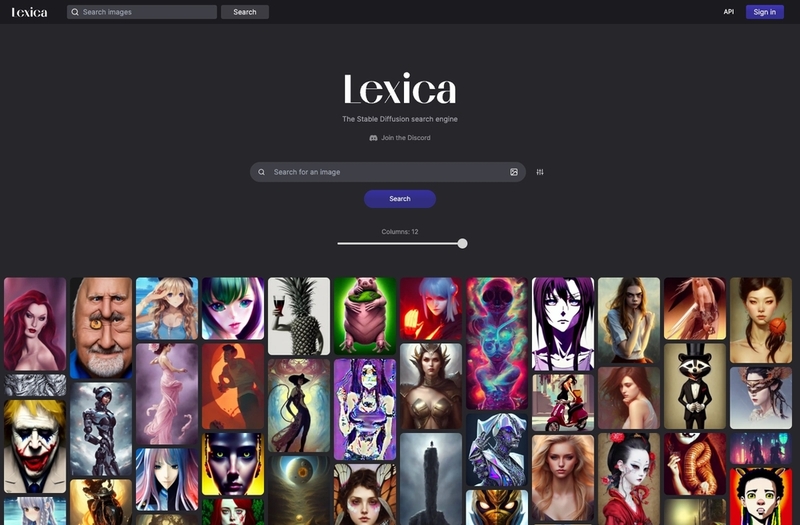
最近は画像生成で使われるプロンプトを集めたサービスも登場しており、求めるイメージに合ったワードの選択・追加は楽になっています。
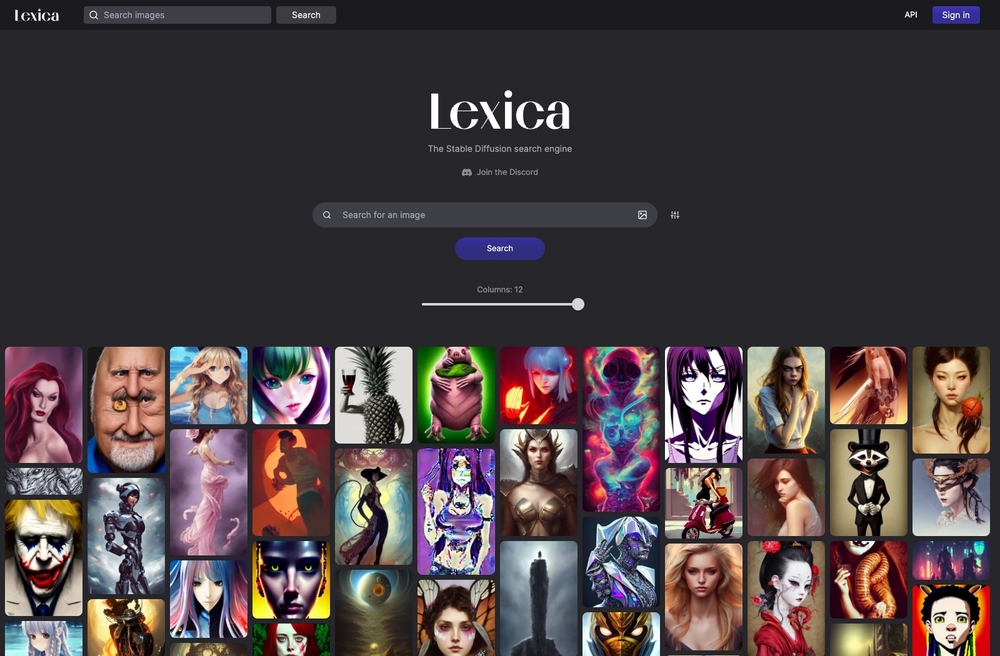
図11 「Stable Diffusion」の画像生成で使われているプロンプトを集めた『Lexica』。画像やワードから生成したい画像のプロンプトが見つけられるサービス
こうして、少しづつワードを追加しながら、軸となるプロンプトを決めた後は、画像を大量に生成して様子を見ていくという作業が続きます。ワードの順番による重み付けもあり、画像生成の途中で、追加するワードの順番を何度も入れ替える必要もあります。
試行錯誤のなかで、少しおもしろい話があります。正面からの女性像を生成しようとしても、どうしても後ろ姿や振り返る女性の姿しか生成できません。「正面を見る」「目を合わせる」などのワードを入力しましたが、効果的だったのは「眼鏡をかける」「胸元のアクセサリー」というワードを含めた場合でした。
図12 最終日に筆者が「Stable Diffusion」で生成した画像。画像生成初日と比較すれば、少しは望み通りの画像が出てくるようになった

その後もプロンプトのワードの順番や重み付け、何を指示するのか、何に注目するのか、させるのか、じっくり考えながら画像を生成しました。SNSで見かける美しいAI生成画像も、こうした試行錯誤と地道な作業、大量の画像生成から生まれた“ほんのひとしずく”なのだなと今は感じています。
作業から見える「できること」「できないこと」
実際に画像生成AIを使用したことで、現状と今後についての方向性を、わずかですが感じることができました。画像生成AIの現状について、個人的に気づいた点をいくつか挙げていきます。
基本的な表現レベルの底上げが始まる
筆者のような“まったく絵が描けない人”が、テキストだけでイメージする画像を生成できるようになったのは画期的です。画像生成AIモデルの持つ“個性(クセ)”を分析して、プロンプトで明確な指示が出せれば、高品質な画像が生成できます。画像生成AIの利用が広がれば、今後の制作物で「画像生成AIで作られるレベルが最低基準」となり、全体的な表現レベルの底上げがなされていくでしょう。
大量に数を求められる作業は淘汰される
画像生成AIでは、短時間で多くのバリエーションを生成できます。回数制限もなく、時間の限り多くのアイデアを試行錯誤できるのは、画像生成AIの大きなメリットです。「素早く、数多くのパターンやバリエーションが見たい」といった作業は、画像生成AIに任されるでしょう。大量の試行錯誤から、人間の考えつかなかったアイデアが生まれる可能性も秘めています。
言語ベースによる表現の難しさ
言葉は文化を表します。画像生成AIでは、英語ベースのプロンプト入力が必要です。プロンプト経由で表現を指示する場合、私たちが利用する日本語と英語とのギャップを感じる部分が少なからずあります。優秀な翻訳ツールもありますが、ニュアンスをつかむため、海外の歴史や文化、外国語の習得に力を入れる必要があるかもしれません。
図13 「Stable Diffusion」で女性の年代を表すワード(英単語)だけを変更して画像の変化を比較した結果。ワードによって微妙に女性の顔の輪郭、顔や目の大きさなどが変化する

画像生成AIだけで作業は完成しない
プロンプトによる画像生成AIへの指示は、画像内にすべて反映されません。何度も試行錯誤できるとはいえ、仕事であれば時間の制限があります。すでに画像生成AIモデルは、動きや手の部分、奥行きや重ね順などの理解が苦手であると指摘されています。少なくとも現状では、最終的な納品レベルまで質を上げるため、人間の判断や修正が必要不可欠です。
クリエイティブ分野の基本的スキルを持つ人が強い
画像生成AIを利用しても、満足できる画像はなかなか生成されません。筆者の体験談でも述べましたが、プロンプトの試行錯誤には、芸術や絵画に関する広範囲の知識とその応用が必要です。画像生成AIの利用は、クリエイティブ分野における知識や経験、スキルを持つ人たちにとって、大きな武器となるでしょう。
「画像生成AI」のこれから
何度も述べてきましたが、画像生成AIの現状は、プロンプトだけで作品が完成するレベルではありません。とりわけ人間の持つ表情、感情を表現する手や腕の動き、魅力を引き出す光源やカメラの位置など、作品の完成度を大幅に引き上げる細部の表現をプロンプト経由で再現させるのは至難の業です。
SNSで「画像生成AI」が話題になった8月上旬から、約2か月が経過しました。SNSの発言数やGoogleでの検索数は、ピークの約3割程度まで減少しています。画像生成AIを使い始めたユーザーの多くは、“画像生成AIのお試し期間”が終了して、継続的な利用は減少しています。
一方で、強い興味を持っているイラストレーターや映像・3Dモデルを扱うクリエイター、AIモデルに興味を持つエンジニアなど、知識と経験、スキルを持った人たちによる個別の画像生成や試行錯誤は大幅に増え、その内容の尖鋭度は増しています。
画像生成AIモデルが一般公開されてからは、ユーザーの行動にも変化が生まれています。初めは「どんな画像を作れるのか」について、簡単なワードによる確認が始まりました。その後は自分が描いたキャラクターの背景に利用したり、小説の挿絵や画像を使ったマンガ制作といった、生成画像と自分の制作物を組み合わせた事例が増えていきます。
「プロンプトだけで完全な画像はできない」という現状を理解して、複数の機能を使い分ける事例も増えました。「Outpainting」による画像領域の拡張、自作イラストから画像を生成する「img2img」の利用、「GFPGAN」による顔面画像の修復・高解像度化などがよく使われています。
モデルを行き来したり、他の技術との組み合わせで、生成画像の欠点を補いながら新たな表現を模索しています。
図14 「Stable Diffusion」で生成した女性の画像(右側)に「GFPGAN」の顔面修復・高解像度化を実行したもの(左側)。女性の目鼻立ちがくっきりしたのがわかる

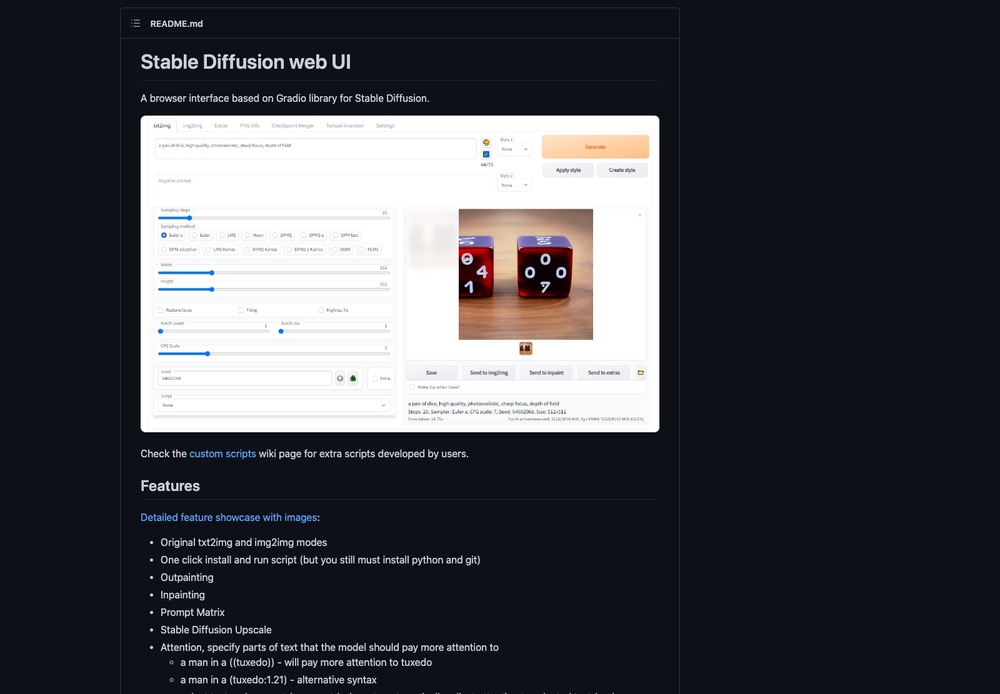
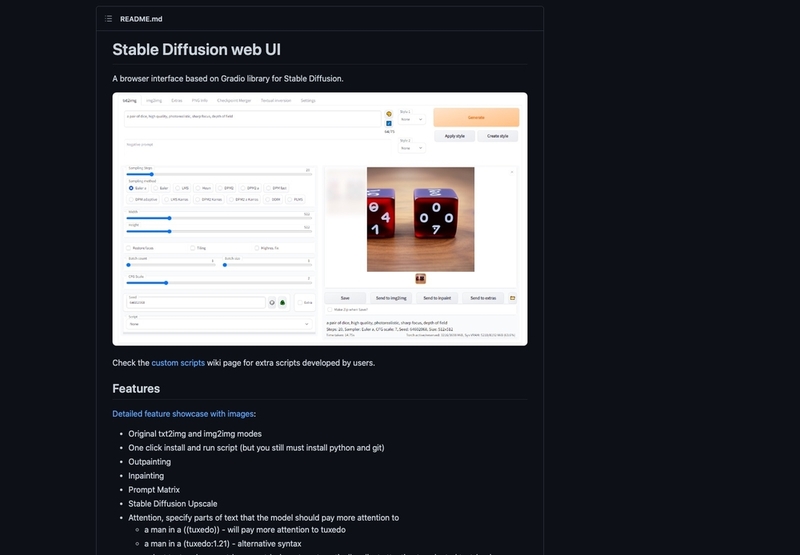
オープンソースで公開されているモデルそのものを、使いやすく改良する事例も出てきました。モデルの高速化やGUIの追加、他モデル固有の機能の移植、モデル自体の個別チューニング(再学習)によるジャンル特化型モデル(アニメ画像生成に特化した「Waifu Diffusion」など)の登場、アプリケーション内でのモデルの実行など、そのバリエーションは今も増え続けています。
図15 「Stable Diffusion」からフォークされた「Stable Diffusion web UI」。画像の一部描き直しやタイル画像の生成、人物の顔補正や高解像化などの機能が使いやすいブラウザのUIとともに提供されている
こうしたユーザーの行動から考えると、将来は自分だけの「画像生成AI」が登場すると考えています。現在はどの分野も無難にこなす“汎用的な「画像生成AI」モデル”ばかりですが、特定のジャンルに特化した「画像生成AI」モデルを、調整・チューニングしながら育てることが一般的になるでしょう。
最終的には、個人の持つ独自スキルのデータを学習させた世界でたったひとつの「画像生成AI」、すなわち自分の分身と協力しながら、クリエイティブを創作していく時代が来るはずです。その際には、AIを成長させるデータとなる各個人の持つ知識やスキルが、表現において大きな差をもたらすと考えています。
AIの自動生成は「どう使うか」の道具に過ぎない
ここまで名前は出ていませんが、GAFAのようなIT大手企業も「画像生成AI」の研究を行なっています。Googleは同社の研究部門、Google Researchが画像生成モデル「Imagen」「Parti」を発表し、これらのモデルを生かした動画生成AI「Imagen Video」も発表。
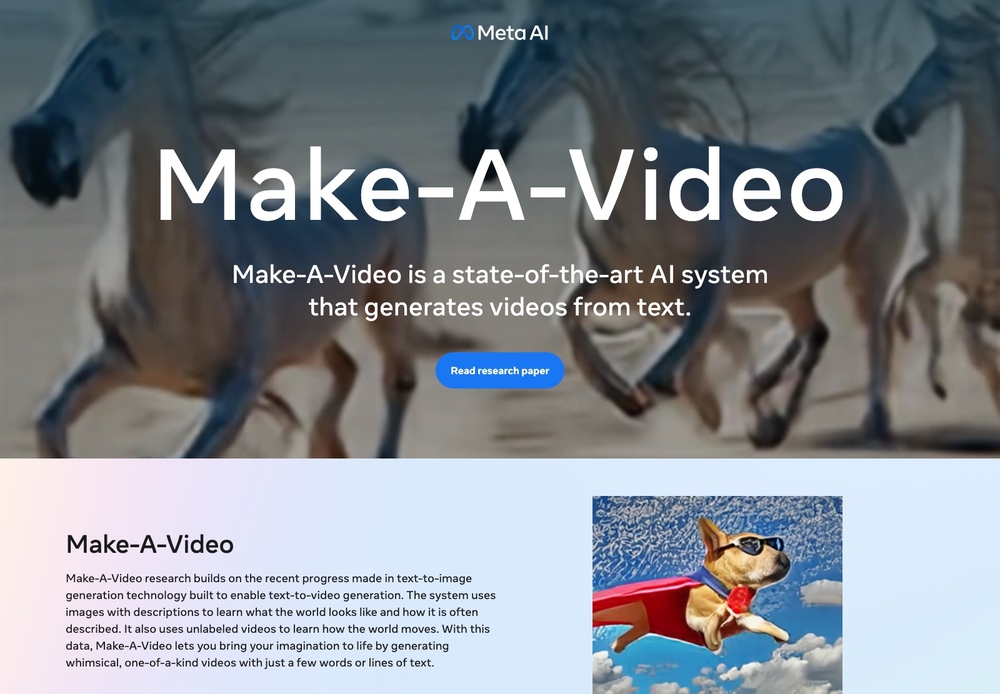
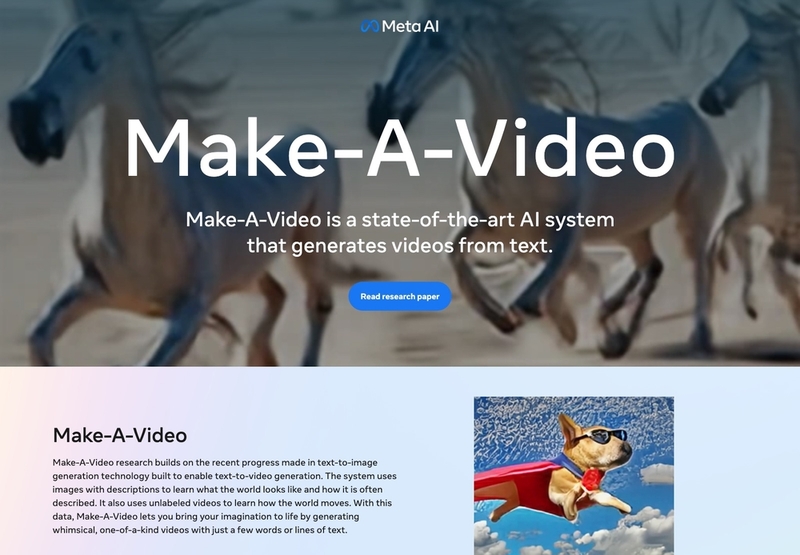
Microsoftも「DALL·E2」を搭載したデザインアプリ「Microsoft Designer」や画像・動画の生成モデル「NUWA-Infinity」を、メタ・プラットフォームズも動画生成AI「Make-A-Video」を発表するなど、続々と自動生成AI分野への参入が続いています。
動画2 Microsoftが発表した「Microsoft 365」のグラフィックデザインアプリ「Microsoft Designer」。MicrosoftのAI技術とOpenAIの「DALL·E2」が採用されており、プロンプトから素早く画像生成できる。今後、同様の機能が他のMicrosoft製品にも組み込まれる見込み
図16 メタ・プラットフォームズが発表した動画生成AIモデル「Make-A-Video」のウェブサイト。アメリカの大手IT企業も、続々と自動生成AI分野の研究成果を公開し始めている
「画像生成AI」の利用は始まったばかりです。法的な部分ではっきりしない部分もありますが、AIによる人間の能力拡張と大幅な効率化は、時代の流れとして止められません。音楽や映像、文章やプログラミング、3Dの分野など、誰でも使いこなせるようになるAIが登場する分野は、これからも広がっていくはずです。
新しい技術の登場時には、できるだけ早めの試行錯誤から、知識と経験を積み重ねることが大事です。「画像生成AI」での表現は、広範囲の知識と経験、相手である「画像生成AI」モデルそのものへの理解も必要です。画像の生成に慣れ親しみながら、上手な利用方法を考えていくべきでしょう。
「画像生成AI」の生成物に評価や付加価値をつけるのは、私たち“人間”です。この最終的な権限が人間側にある限り、各個人が基本的な知識と技術、それに伴う経験を高めていくことは、決してムダにならないでしょう。
絵を書くことを仕事にしている人たちにとっては、「自分でなければ描けない世界観」「絵に込められたストーリーや背景の表現」「微妙なニュアンスや細部へのこだわり」など、人間の感情を揺さぶる表現が「画像生成AI」であっても求められます。こうしたポイントをしっかり考えながら制作してきた人たちであれば、今後の作品制作で「画像生成AI」が大きな力となってくれるはずです。
原稿の執筆中にも、驚くような技術や利用方法が毎日のように登場して、画像生成AIの状況は目まぐるしく変化しています。裏を返せば、人と時間、お金と技術が集中した、人々にもっとも注目されている技術でもあります。湧き出る大量の情報はすべて追いきれませんが、静かに興奮しながら、AIの広がっていく時代の流れを体験していきたいものです。