



前回までの説明でCassandraのインストールと動かすところまでいきました。今回はCassandraのデータモデルを理解して、
データはすべて4次元または5次元の連想配列
Cassandraのデータは非常にシンプルなデータモデルを持っています。データはすべて4次元または5次元の連想配列のようになっています。
4次元の場合は以下の形で値にアクセスします。
[キースペース][カラムファミリ][キー][カラム]そして5次元の場合は以下の形でデータを特定します。
[キースペース][カラムファミリ][キー][スーパーカラム][カラム]Cassandraのデータモデルは以下の4つの概念で成り立っています。
- カラム:
- データの最小単位。実際のキーと値、
そしてタイムスタンプを持つ。 - スーパーカラム:
- カラムの集合を扱う単位。
- カラムファミリ:
- カラムまたはスーパーカラムの集合を扱う単位。RDBMSでいうところのテーブル。
- キースペース:
- RDBMSでいうところのデータベース。一般に1アプリケーションで1つ使用する。
1つ1つ見ていきましょう。
カラム ─データ構造の最小単位
カラムとは、
- name:カラムにアクセスするためのキー
- value:カラムの値
- timestamp:カラムの更新日時
これらの値はすべてアプリケーションから与えられるもので、
| Column | ||
|---|---|---|
| name(byte[]) | value(byte[]) | timestamp(long) |
これがもっとも基本的なデータ構造になります。たとえばカラム
| Column:twitter | ||
|---|---|---|
| shot6 | 1271419252387 | |
スーパーカラム ─カラムの集合を扱う
スーパーカラムはカラムの集合を扱うデータ構造です。複数のカラムを束ねて、
スーパーカラムは以下の項目を保持しています。
- key:
- このスーパーカラムにアクセスするためのキーです。
- value:
- このスーパーカラムで保持するカラムの配列です。
スーパーカラムはタイムスタンプを持たないのが特徴です。使い方としては、
- スーパーカラムのキーでカラムの集合を特定する
- 第2のキーとして、
カラム名でカラムを特定する
データ構造を図示すると以下のようになります。
| SuperColumn | |
|---|---|
| key | byte[] |
| value | Column[] |
具体例で見てみましょう。
複数Webサービスのプロフィールを表現するスーパーカラム
| SuperColumn:profile | |||
|---|---|---|---|
| key | Column | ||
| hatena | name | value | timestamp |
| id | shot6 | 1271419252387 | |
| firstname | Shinpei | 1271419252387 | |
| lastname | Ohtani | 1271419252387 | |
| lastupdate | 2010/ | 1271419252387 | |
| name | value | timestamp | |
| userid | shot6 | 1271419252387 | |
| name | Shinpei Ohtani | 1271419252387 | |
| location | Tokyo | 1271419252387 | |
| web | htttp:// | 1271419252387 | |
この場合、
では次に、
実はCassandraではカラムファミリごとに異なるカラムを持つことができます。カラムは実行時に追加できるので、
カラムファミリ ─カラムを保持する
カラムファミリはカラムを保持する器です。カラムの集合をロウと呼びますが、
- カラムが入る場合
- スーパーカラムが入る場合
カラムとスーパーカラムを同一のカラムファミリに入れることはできません。必ずどちらかのケースになります。
各カラムファミリはロウごとにソートされており、
カラムファミリはstorage-conf.
カラムファミリの変更を行った場合、
カラムファミリのデータ構造は、
| ColumnFamily | |
|---|---|
| key | byte[] |
| value | Column[] |
この場合、
一方、
| ColumnFamily | |
|---|---|
| key | byte[] |
| value | SuperColumn[] |
カラムの場合と違ってくるのは、
下記のように、
| ColumnFamily:profile-group | |||||
|---|---|---|---|---|---|
| key | SuperColumn | ||||
| shot | key | Column:profile | |||
| hatena | name | value | timestamp | ||
| id | shot6 | 1271419252387 | |||
| firstname | Shinpei | 1271419252387 | |||
| lastname | Ohtani | 1271419252387 | |||
| lastupdate | 2010/ | 1271419252387 | |||
| name | value | timestamp | |||
| userid | shot6 | 1271419252387 | |||
| name | Shinpei Ohtani | 1271419252387 | |||
| location | Tokyo | 1271419252387 | |||
| web | htttp:// | 1271419252387 | |||
| yone098 | key | Column | |||
| livedoor | name | value | timestamp | ||
| id | yone098 | 1271419677179 | |||
| title | yone098's livedoor Blog | 1271419677179 | |||
| latest | tokyo-marathon-2010 | 1271419677179 | |||
| name | value | timestamp | |||
| userid | yone098 | 1271419677179 | |||
| name | Masaaki Yonebayashi | 1271419677179 | |||
| location | Toyama | 1271419677179 | |||
| web | htttp:// | 1271419677179 | |||
このような場合、
このように、
キースペース ─最上位のデータ構造
最も上位のデータ構造が、
| Keyspace | |
|---|---|
| key | String |
| value | ColumnFamily[] |
カラムに対しての操作を行う場合、
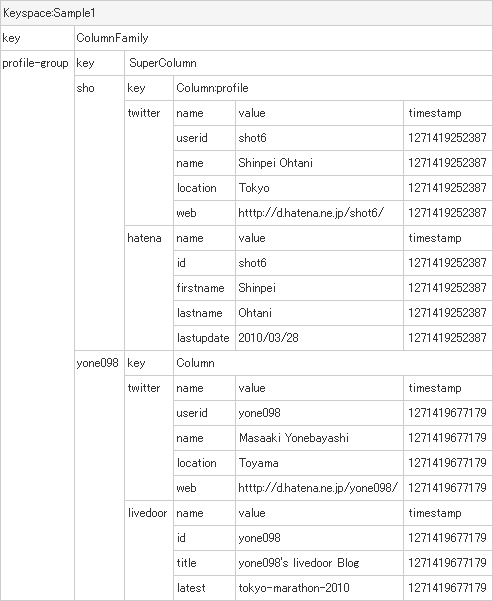
なんとなくイメージをつかんでいただけたでしょうか?
あらためて4つのデータモデルの特徴をまとめると、
| 名前 | 説明 | 設定方法 | タイムスタンプ |
|---|---|---|---|
| カラム | Cassandraのデータ最小単位 | 動的 | 持つ |
| スーパーカラム | 複数カラムの集合 | 動的 | 持たない |
| カラムファミリ | カラムまたはスーパーカラムの集合 | 設定ファイルに指定 | 持たない |
| キースペース | 最上位の構造。複数のカラムファミリを持つ | 設定ファイルに指定 | 持たない |
感覚がつかめてきたでしょうか? そうであれば幸いです。
CassandraのWikiページにも、
- データモデルの和訳
- URL:http://
wiki. apache. org/ cassandra/ DataModel_ JP - データモデルの本文
- URL:URL:http://
wiki. apache. org/ cassandra/ DataModel
長くなってしまいましたが、