



はじめに
「よろしく」
ユーザの行動を予測する方法はいろいろなものが考えられます。上の例の場合は
予測インタフェースが成功する要件
予測インタフェースは次のような特徴を持っている必要があります。
予測の精度が高いこと
システムの予測結果がユーザの期待と一致しないことが多ければ予測システムを利用しようとは思わないでしょう。次の入力単語を完全に予測することは不可能ですが、
予測により作業が邪魔されないこと
予測のための計算に時間がかかったり、
予測の実行に手間がかからないこと
システムが正しい予測を行ったとき、
予測に失敗したとき被害をこうむらないこと
入力単語を予測するような場合は予測に失敗してもそれほど困ることはありませんが、
上述の条件をすべて満たすシステムは多くないため、
Dynamic Macro
ここでは、
テキストエディタ上で同じような編集操作を繰り返すことがよくあります。よくある例として次のようなものがあるでしょう。
- ① ブロックをまとめて字下げする
- ② 変数名を変更する
- ③ 連続する行にコメント記号を挿入する
上に挙げた編集操作はすべて同じ編集操作の繰り返しになっています。①は
Emacsの場合、
Dynamic Macroは、
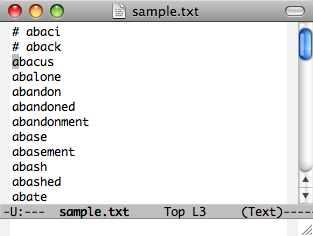
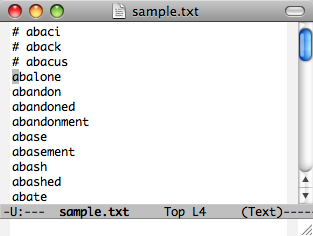
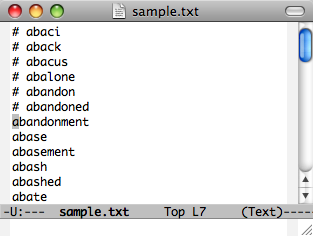
FirefoxでもDynamic Macro
Dynamic MacroはもともとEmacs上で開発したものなので、
Keysnailはmoozさんが開発したFirefoxの拡張機能で、
KeysnailとDynamic Macroプラグインをインストールすると、
key.setEditKey('C-t', function (ev) {
ext.exec("dmacro-exec");
}, 'Dynamic macro');Twitterで投稿テキストを強調するために文字間に空白文字を入れる場合、



予測とデータ圧縮
大きなファイルを配布するとき、
多くの圧縮アルゴリズムは、
つまり、
PPM法
効率の良いデータ圧縮アルゴリズムとしてPPM法
- ① 「a」
は5回、 「b」 は2回、 「c」 は1回出現している - ② 「a」
の次が 「b」 である例は2つあり、 「c」 「d」 であった例が1つずつある - ③ 「ra」
の次が 「c」 であった例が1つあり、 それ以外の文字が出た例は存在しない - ④ 「bra」
の次が 「c」 であった例が1つあり、 それ以外の例は存在しない
①から判断すると次の文字は
②の情報だけを見ると、
| 文字 | 出現確率 |
|---|---|
| b | 2/ |
| c | 1/ |
| d | 1/ |
| その他 | 1/ |
| 文字 | 出現確率 |
|---|---|
| c | 1/ |
| その他 | 1/ |
PPM法では、
統計情報がない場合はあらゆる文字に対して同じ長さのコードを割り当てる必要があるでしょうが、
PPM法によるデータ圧縮は圧縮率が高いことが知られていますが、
予測を利用したじゃんけんシステム
PPM法のような予測手法は予測インタフェースの実装に有効であるだけでなく、
PPM法を圧縮に利用する場合は次の文字の出現確率を細かく見積もる必要がありますが、
このような考え方に基づいて、
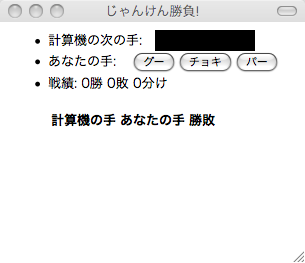
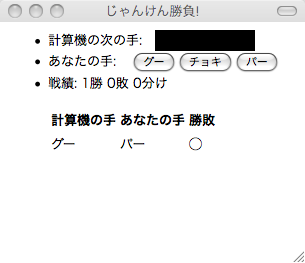
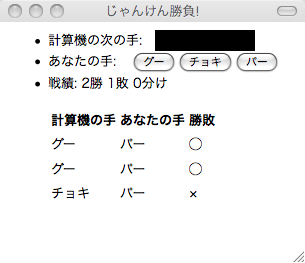
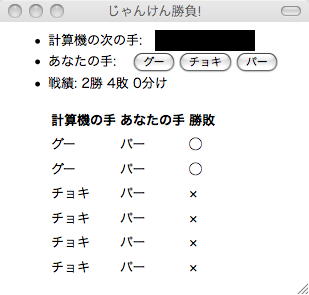
単純なアルゴリズムですが、
<html>
<head>
<meta http-equiv="Content-Type" content="text/html;
charset=utf-8">
<title>じゃんけん勝負!</title>
</head>
<ul>
<li>
<div style="float:left;">計算機の次の手: </div>
<div id="computer" style="width:100px;color:
black;float:left;"></div>
<br clear='all'>
<li>あなたの手:
<input type='button' onclick='bet("g")' value="グー">
<input type='button' onclick='bet("c")' value="チョキ">
<input type='button' onclick='bet("p")' value="パー">
<li>戦績: <span id="total">0勝 0敗 0分け</span>
</ul>
<blockquote>
<table id='score'>
<tr><th>計算機の手</th><th>あなたの手</th>
<th>勝敗</th></tr>
</table>
</blockquote>
<script type="text/javascript">
var level = 5;
var accum = [];
var C = [];
var U = [];
var win = 0, lose = 0, draw = 0;
var name = {'g':'グー', 'c':'チョキ', 'p':'パー'};
function add(c){ // ユーザの手を登録
U.push(c);
for(i=1;i<=level;i++){
s = U.slice(U.length-i,U.length).join('');
accum[s] = (accum[s] ? accum[s]+1 : 1);
}
}
function show(){ // 勝敗を判断して戦績を表示
c = C[C.length-1];
u = U[U.length-1];
if(c == u){
r = '△'; draw++;
}
else if(c == 'g' && u == 'c' ||
c == 'c' && u == 'p' ||
c == 'p' && u == 'g'){
r = '×'; lose++;
}
else {
r = '◯'; win++;
}
document.getElementById('total').innerHTML =
win + '勝 ' + lose + '敗 ' + draw + '分け';
s = document.getElementById('score');
e = document.createElement('tr');
f = document.createElement('td');
f.innerHTML = name[c];
e.appendChild(f);
f = document.createElement('td');
f.innerHTML = name[u];
e.appendChild(f);
f = document.createElement('td');
f.innerHTML = r;
e.appendChild(f);
s.appendChild(e);
}
function bet(v){ // ユーザが勝負
document.getElementById('computer').style.
backgroundColor = 'white';
add(v);
show();
predict();
setTimeout('nextround()',1000);
}
function predict(){ // 計算機の次の手を計算
res = [];
n = 0;
for(var i=1;i<=level;i++){
s = U.slice(U.length+i-level, U.length).join('');
for(c in name){
r = s + c;
if(accum[r]){
if(accum[r] > n){
n = accum[r];
res = [c];
}else if(accum[r] == n){
res.push(c);
}
}
}
if(res.length > 0) break;
}
c = res[Math.floor(Math.random() * res.length)];
C.push(c == 'p' ? 'c' : c == 'g' ? 'p' : 'g');
}
function nextround(){ // 次の手を隠して表示
var k = document.getElementById('computer');
k.style.backgroundColor = 'black';
k.innerHTML = name[C[C.length-1]];
}
function init(){
for(i=0;i<level;i++){
add(['g','c','p'][Math.floor(Math.random() * 3)]);
}
predict();
nextround();
}
init();
</script>
</body>
</html>まとめ
予測インタフェースの研究の歴史は古いのですが、