



前回はショッピングカートを作成しつつ、
Ember DataはEmber.
まだ発展途上のライブラリですが、
環境準備
まずは環境準備です。前回の記事を参考に必要なファイルを準備してください。また、
本稿での対象バージョンはこちらです。
- jQuery … 2.
1.3 - Ember.
js … 1. 10. 0 - Ember Data … 1.
0.0-beta. 15
準備ができたらHTMLをブラウザで表示してください。ブラウザの開発者コンソールにEmber Dataのバージョンが表示されていれば準備完了です。
DEBUG: -------------------------------
DEBUG: Ember : 1.10.0
DEBUG: Ember Data : 1.0.0-beta.15
DEBUG: jQuery : 2.1.3
DEBUG: -------------------------------それでは実際にEmber Dataに触れてみましょう。
データを扱う
DS.Model
Ember Dataでデータを扱う際はDS.を継承したクラスを作成します。まずはブログ記事を表すPostと、Commentを作成しましょう。
App.Post = DS.Model.extend({
title: DS.attr('string'),
body: DS.attr('string'),
comments: DS.hasMany('comment')
});
App.Comment = DS.Model.extend({
text: DS.attr('string'),
post: DS.belongsTo('post')
});データとモデルの対応付け
データと対応させたいプロパティにはDS.を指定します。こうすることで、
型変換
DS.の引数に形名を指定すると、
stringnumberbooleandate
特にJSONで表現できない日付Date)dateを指定してください。データの型変換が不要な場合
データの形式
この例では、
// post
{
"id": ...,
"title": ...,
"body": ...
}
// comment
{
"id": ...,
"text": ...
}このデータのプロパティのうち"id"は自動でマッピングされるため、DS.を指定します。
また、DS.とDS.を使って一対多の関連を定義しました。DS./DS.の引数には、
| クラス | モデル名 |
|---|---|
| Post | post |
| Comment | comment |
| TopicCategory | topic-category |
このモデル名は、
次はデータを読み込む部分を解説します。
DS.Store
Ember Dataでは、DS.によって管理されます。DS.はクライアントサイドのデータベースのようなもので、
外部サーバからデータを取得する方法は後述するので、
App.ApplicationRoute = Ember.Route.extend({
beforeModel: function() {
this.store.push('post', {
id: 1,
title: 'はじめての Ember.js',
body: 'これから Ember.js を始めようという方向けの記事です。'
});
this.store.push('post', {
id: 2,
title: '公式サイトの歩き方',
body: 'http://emberjs.com/ の解説です。'
});
this.store.push('comment', {
id: 1,
text: 'はじめまして',
post: 1
});
this.store.push('comment', {
id: 2,
text: '入門しました。',
post: 1
});
this.store.push('comment', {
id: 3,
text: '詳しい説明を知りたいときはまず参考にします。',
post: 2
});
}
});では、DS.のインスタンスにアクセスする方法を説明します。Ember DataはControllerとRouteにstoreというプロパティを定義し、DS.のインスタンスを設定します。これにより、ControllerとRouteの中ではthis.でストアにアクセスできます。
そしてストアにデータを読み込むにはストアのpush()メソッドを利用します。push()メソッドの第一引数はモデル名、
データが関連を持っている場合、
さて、
ルーティングを作成します。
App.Router.map(function() {
this.resource('posts', {path: '/'});
this.resource('post', {path: '/post/:id'});
});
App.PostsRoute = Ember.Route.extend({
model: function() {
return this.store.all('post');
}
});
App.PostRoute = Ember.Route.extend({
model: function(params) {
return this.store.find('post', params.id);
}
});ここではストア経由でモデルを取得しています。モデルを取得するにはいくつかの方法があります。
DS.Store#all() ストアに読み込み済みのモデル全件を取得します。第一引数にはモデル名を指定します。
DS.Store#find() モデル名とIDを指定してモデルを取得します。もし該当するモデルがストアに存在しなければ、
ストアはサーバに対してHTTPリクエストを発行してデータを取得します [4]。ここまでのサンプルではサーバを用意していないのでリクエストは失敗します。
次はテンプレートを作成します。
<script type="text/x-handlebars" data-template-name="posts">
<h1>ブログ記事一覧</h1>
<ul>
{{#each post in model}}
<li>{{link-to post.title "post" post}}</li>
{{/each}}
</ul>
</script>
<script type="text/x-handlebars" data-template-name="post">
<h1>{{model.title}}</h1>
<pre>
{{model.body}}
</pre>
<ul>
{{#each comment in model.comments}}
<li>{{comment.text}}</li>
{{/each}}
</ul>
{{link-to "戻る" "posts"}}
</script>この状態でブラウザを表示すると、
REST APIを扱う
ここまででストアに読み込んだデータを扱うことができるようになりました。ここからはREST API経由でデータの取得とデータの保存を解説します。
今までデータを準備していたApp.は不要になるので、
そして、PostsRouteもmodel()メソッドではall()メソッドの代わりにfind()メソッドを利用します。
App.PostsRoute = Ember.Route.extend({
model: function() {
return this.store.find('post');
}
});これで、
しかし、
APIサーバのURLは次のとおりです。
それでは、
DS.Adapter
Ember Dataでデータの取得元を指定するためにはDS.を利用します。Ember DataにはDS.のサブクラスがいくつか用意されていて、DS.が利用されます
DS.は、
| メソッド | URL |
|---|---|
|
store. |
/posts |
|
store. |
/posts/ |
|
store. |
/posts?page=2 |
この規則はカスタマイズ可能ですが、
では先ほど紹介したAPIサーバを利用するための設定を行います。
App.ApplicationAdapter = DS.RESTAdapter.extend({
host: 'https://tricknotes-gihyo-ember-07.herokuapp.com',
namespace: 'v1'
});すべてのモデルに共通するアダプタはApplicationAdapterという名前で定義します。もしPostやComment専用のアダプタを作成したい場合は、PostAdapterやCommentAdapterといった
ではここで登場した設定項目を説明します。
hostAPIサーバのスキームとホスト名を指定します。指定しない場合は現在のURL
( window.)location. origin が利用されます。 namespaceAPIの名前空間を指定します。例えば
namespace: 'v1'が設定されていると、/posts/というURLの代わりに1 /v1/に対してリクエストが発行されます。今回利用するAPIサーバではいろいろな形式のJSONを扱う例を紹介したいので、posts/ 1 各セクション毎に別の namespaceを用意しました。
これで、
次はAPIサーバが返すべきJSONの形について考えてみましょう。
DS.Serializer
JSONに含まれるデータとモデルのマッピングにはDS.を使います。デフォルトでは、DS.というREST APIに特化したシリアライザが利用されます。
このDS.をカスタマイズするとクライアントサイドで自由なマッピングを指定できますが、
ブログ記事一覧で返すべきJSONは次のような形になります。
{
"posts": [
{
"id": 1,
"title": "はじめての Ember.js",
"body": "これから Ember.js を始めようという方向けの記事です。"
},
{
"id": 2,
"title": "公式サイトの歩き方",
"body": "http://emberjs.com/ の解説です。"
}
],
"comments": [
{
"id": 1,
"text": "はじめまして",
"post": 1
},
{
"id": 2,
"text": "入門しました",
"post": 1
},
{
"id": 3,
"text": "詳しい説明を知りたいときはまず参考にします。",
"post": 2
}
]
}ポイントは次の2点です。
- JSONのルートのキーはモデル名を使う
(オブジェクトが複数あればモデル名の複数形を指定する) - 関連するデータがあればレスポンスに含める
(今回の例では /postsへのリクエストに対してcommentsをレスポンスに含めている)
これを満たすことで、DS.がレスポンスのJSONをモデルにマッピングしてくれます。
また、
{
"post": {
"id": 1,
"body": "これから Ember.js を始めようという方向けの記事です。",
"title": "はじめての Ember.js"
},
"comments": [
{
"id": 1,
"text": "はじめまして",
"post": 1
},
{
"id": 2,
"text": "入門しました",
"post": 1
}
]
}記事一覧のJSONとの違いは、
postとcommentsのような関連するリソースを扱う場合、
- JSON生成に利用するライブラリの都合上、
"post"と"comments"を並列に並べるのが困難である - commentsの数が膨大で全部をpostのレスポンスに含めるとパフォーマンスが劣化する
こういった場合に対応するため、
子リソースを親リソースに埋め込む
ここでは、
{
"posts": [
{
"id": 1,
"body": "これから Ember.js を始めようという方向けの記事です。",
"title": "はじめての Ember.js",
"comments": [
{
"id": 1,
"text": "はじめまして"
},
{
"id": 2,
"text": "入門しました"
}
]
},
{
"id": 2,
"body": "http://emberjs.com/ の解説です。",
"title": "公式サイトの歩き方",
"comments": [
{
"id": 3,
"text": "詳しい説明を知りたいときはまず参考にします。",
}
]
}
]
}まずはアダプタの設定を変更しましょう。
App.ApplicationAdapter = DS.RESTAdapter.extend({
host: 'https://tricknotes-gihyo-ember-07.herokuapp.com',
namespace: 'v2'
});この形のJSONから子リソースを取得したい場合、DS.を利用します。
App.PostSerializer = DS.RESTSerializer.extend(DS.EmbeddedRecordsMixin, {
attrs: {
comments: {embedded: 'always'}
}
});attrsattrsはDS.JSONSerializer ( DS.の親クラス)RESTSerializer で提供されているプロパティです。ここではデータとモデルのプロパティの対応を設定できます。 embeddedDS.を使うと、EmbeddedRecordsMixin attrsでデータの取得時と送信時での子リソースの扱い方を指定きます(データ送信時の振る舞いについては後述)。ここで指定している {embedded: 'always'}というのは、「データ送信時・ 取得時ともに子リソースを埋め込む」 ということを意味します。
非同期で子リソースを取得する(ID参照)
さて、
{
"posts": [
{
"id": 1,
"title": "はじめての Ember.js",
"body": "これから Ember.js を始めようという方向けの記事です。",
"comments": [
1,
2
]
},
{
"id": 2,
"title": "公式サイトの歩き方",
"body": "http://emberjs.com/ の解説です。",
"comments": [
3
]
}
]
}まずはアダプタの設定を変更しましょう。
App.ApplicationAdapter = DS.RESTAdapter.extend({
host: 'https://tricknotes-gihyo-ember-07.herokuapp.com',
namespace: 'v3'
});「子リソースを親リソースの埋め込む」PostSerializerは不要なので削除します。
そして、
App.Post = DS.Model.extend({
// ...
comments: DS.hasMany('comment', {async: true})
});では、
記事詳細を表示すると、
実際にどのタイミングでコメントが取得されているのかというと、postテンプレート中でコメントが参照されたタイミングです。
{{#each comment in model.comments}}ではここで、

コメントの数だけHTTPリクエストが発行されています。もしコメントが大量に存在する場合コメントの数だけHTTPリクエストが発行されるため、
App.ApplicationAdapter = DS.RESTAdapter.extend({
// ...
coalesceFindRequests: true
});
コメントを取得するURLに、idsというパラメータ付きでリクエストが発生するようになりました。このAPIサーバがこの形式に対応していればこちらの方がリクエスト数を減らせます。
非同期で子リソースを取得する(URL参照)
先ほどと同じく、
linksというプロパティを使うと、
{
"posts": [
{
"body": "これから Ember.js を始めようという方向けの記事です。",
"title": "はじめての Ember.js",
"id": 1,
"links": {
"comments": "https://tricknotes-gihyo-ember-07.herokuapp.com/v4/posts/1/comments"
}
},
{
"body": "http://emberjs.com/ の解説です。",
"title": "公式サイトの歩き方",
"id": 2,
"links": {
"comments": "https://tricknotes-gihyo-ember-07.herokuapp.com/v4/posts/2/comments"
}
}
]
}ではこのJSONを扱うためにアダプタを設定しましょう。
App.ApplicationAdapter = DS.RESTAdapter.extend({
host: 'https://tricknotes-gihyo-ember-07.herokuapp.com',
namespace: 'v4'
});この状態で、

linksプロパティで指定したURLに対してリクエストが発行されています。
子リソースを扱ういくつかの方法を紹介しましたが、
CRUD を扱う
ここまではデータを取得方法を紹介してきましたが、
まずはアダプタを設定します
App.ApplicationAdapter = DS.RESTAdapter.extend({
host: 'https://tricknotes-gihyo-ember-07.herokuapp.com',
namespace: 'v5'
});JSONの形式はv1と同じものを使っているため、
App.Post = DS.Model.extend({
// ...
comments: DS.hasMany('comment')
});次は記事詳細画面からコメントの投稿/
<script type="text/x-handlebars" data-template-name="post">
<h1>{{model.title}}</h1>
<pre>
{{model.body}}
</pre>
<ul>
{{#each comment in model.comments}}
<li>{{comment.text}} <a href="#" {{action "deleteComment" comment}}>×</a></li>
{{/each}}
<li>{{input value=text action="createComment" required=true placeholder="どうでしたか?"}}</li>
</ul>
{{link-to "戻る" "posts"}}
</script>記事詳細画面に対応するコントローラを作成して、
App.PostController = Ember.Controller.extend({
text: null,
actions: {
createComment: function() {
var controller = this;
var text = this.get('text');
var comment = this.get('model.comments').createRecord({text: text});
comment.save().then(function() {
controller.set('text', null);
}, function() {
alert('保存に失敗しました');
comment.unloadRecord();
});
},
deleteComment: function(comment) {
comment.destroyRecord();
}
}
});新しく登場した記述を解説します。
createRecord()モデルのオブジェクトを生成するメソッドです。ここでは
postの関連であるcommentsに対してcreateRecord()メソッドを呼び出しているため、記事への関連を保持した状態のコメントを生成します。この状態ではまだサーバに保存はされません。関連を元にせずオブジェクトを生成したい場合は store.を利用します。この場合、createRecord() 第一引数はモデル名、 第二引数は初期値を指定します。 save()モデルをサーバに保存します。クライアントサイドで生成されたモデルであれば新規保存され、
サーバから取得してきたモデルであれば更新されます。サーバに送信されるデータはシリアライザによって決定されます。関連するリソースも一緒にサーバに送信したいという場合は前述の DS.を使います。サーバに送信されるデータをあらかじめ確認したい場合は、EmbeddedRecordsMixin モデルの serialize()メソッドを利用してデータを取得します。また、save()メソッドはPromiseを返します。保存に成否を待ってから実行したい処理がある場合、Promiseのコールバックを利用してください。 unloadRecord()クライアントサイドのモデルを破棄します。クライアントでモデルが不要になった際に呼び出します。
destroyRecord()モデルをサーバから削除します。似たような機能を持つ
deleteRecord()メソッドもあります。前者はすぐにサーバのデータも削除されるのに対し、後者は save()メソッドを呼ぶまでサーバのデータは削除されないという違いがあります。
これらのメソッドは、
メソッドとAPIの対応は次のとおりです。
| メソッド | URL | リクエストメソッド |
|---|---|---|
comment. (新規)
|
/comments/ | POST |
comment. (更新)
|
/comments/ |
PUT |
comment.
|
/comments/ |
DELETE |
動作するサンプルはこちらです。
ここまでは、DS./DS.が期待する形のAPIサーバを前提として解説をしてきました。APIサーバを実装しつつアプリケーションを開発する際にはここまでで紹介した方法で十分でしょう。
外部のAPIを扱う
せっかくなので、
サンプルとして
GitHubでのログイン名を入力してエンターキーを押します。
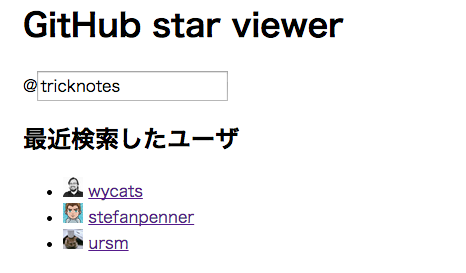
ユーザの最近のお気に入り一覧が表示されます。
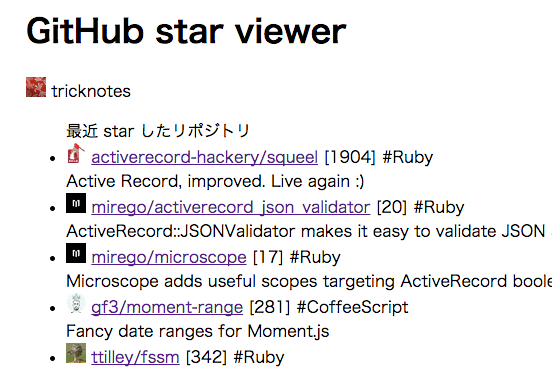
今回対象とするAPIはGitHub APIです。
まずはこのAPIを使うようアダプタを設定します。
App.ApplicationAdapter = DS.RESTAdapter.extend({
host: 'https://api.github.com'
});今回はユーザとリポジトリさえあれば十分なので、
App.User = DS.Model.extend({
login: DS.attr('string'),
avatar_url: DS.attr('string'),
starred: DS.hasMany('repo', {async: true})
});
App.Repo = DS.Model.extend({
name: DS.attr('string'),
full_name: DS.attr('string'),
html_url: DS.attr('string'),
description: DS.attr('string'),
language: DS.attr('string'),
watchers: DS.attr('number'),
owner: DS.attr() // owner はオブジェクトが渡ってくるので型変換は行わない
});次は、
App.UserSerializer = DS.RESTSerializer.extend({
primaryKey: 'login',
normalizePayload: function(payload) {
payload.links = {
starred: payload.url + '/starred'
};
return {
user: payload
};
}
});
App.RepoSerializer = DS.RESTSerializer.extend({
normalizePayload: function(payload) {
return {
repo: payload
};
}
});細かく見ていきましょう。
primaryKeyプライマリーキーとして扱うプロパティを指定します。デフォルトは
idです。GitHub APIではユーザのJSONにidが含まれているのですが、今回のアプリケーションではログイン名をキーにしてユーザを取得するため、 モデルを簡単に扱うために loginプロパティをIDとみなすことにします。normalizePayloadAPIから取得したJSONをEmber Dataで扱う形に変換するためのメソッドです。引数にはサーバから取得したJSONがそのまま渡ってくるので、
先ほど紹介した形に加工して戻り値に指定します。デフォルトの実装では引数で渡されたJSONをそのまま返すようになっています。
ここまででGitHub APIを扱う準備が完成しました。あとはルーティングとテンプレートを作成して実際に動かしてみましょう。
ルーティングは以下のとおりです。
App.Router.map(function() {
this.resource('user', {path: 'user/:id'});
});
App.IndexRoute = Ember.Route.extend({
model: function() {
return this.store.all('user');
}
});
App.UserRoute = Ember.Route.extend({
model: function(params) {
return this.store.find('user', params.id);
}
});
App.IndexController = Ember.Controller.extend({
name: null,
actions: {
addUser: function() {
var user = this.store.find('user', this.get('name'));
this.set('name', null);
this.transitionToRoute('user', user);
}
}
});テンプレートは次のとおりです。
<script type="text/x-handlebars">
<h1>GitHub star viewer</h1>
{{outlet}}
</script>
<script type="text/x-handlebars" data-template-name="index">
@{{input value=name action="addUser" placeholder="username(GitHub)"}}
{{#if model.length}}
<h2>最近検索したユーザ</h2>
{{/if}}
<ul>
{{#each user in model}}
<li>
<img {{bind-attr src=user.avatar_url}} width="20px" height="20px"/>
{{link-to user.id "user" user}}
</li>
{{/each}}
</ul>
</script>
<script type="text/x-handlebars" data-template-name="user">
<img {{bind-attr src=model.avatar_url}} width="20px" height="20px"/>
{{model.id}}
<ul>
最近 star したリポジトリ
{{#each repo in model.starred}}
<li>
<img {{bind-attr src=repo.owner.avatar_url}} width="20px" height="20px"/>
<a {{bind-attr href=repo.html_url}} target="_blank">{{repo.full_name}}</a>
[{{repo.watchers}}]
#{{repo.language}}
<div>
{{repo.description}}
</div>
</li>
{{/each}}
</ul>
{{link-to "戻る" "index"}}
</script>このように、
まとめ
今回はEmber Dataについて解説しました。Ember Dataには今回解説したもの以外にもいつくかの部品が存在します。さらに詳しい説明は公式ドキュメントを参照してください。
次回は、