今回は、IkaLogの開発をふりかえりながら、IkaLogの画像処理の基本的な考え方、そしてその背景などについて説明します。
はじめての画面認識の検討
第1回で紹介したとおり、まずはゲームの画像に対してどのような処理をすれば画像認識を達成できるかを検討し始めました。
最初に、スプラトゥーンのプレイ動画を録画してみて、録画を何度か眺めてみました。幸いなことに、スプラトゥーンのゲーム中では、多くのメッセージはたいてい白色で、いつも画面上の同じ位置に表示されます。このため、白色の部分だけを抜き出して、OpenCVのテンプレートマッチング機能を利用して表示内容を検出すればいいのではないかと考えました。
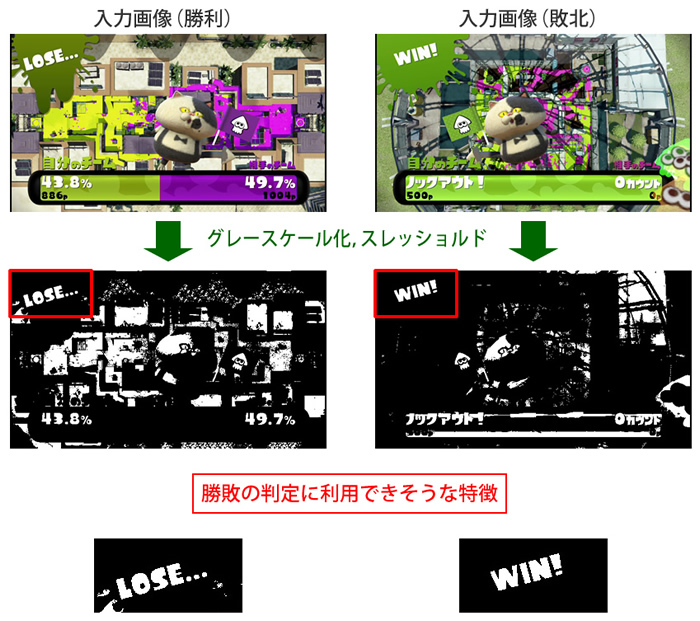
スプラトゥーンのシステムメッセージが真っ白な色で表示されるということは、256階調のグレースケール画像として処理したときに、文字に近いところは255に近い値であり、つまりは非常に高いスレッショルド(閾値フィルタ)をかければシステムメッセージだけが白く残った画像が生成できるだろう、と考えました。その文字形状が綺麗に残った画像が生成できれば理想的です。
この手法がうまくいくか検討するために、オープンソースのビデオエンコードソフトウェアであるFFmpegに、スレッショルドフィルタを実装して試してみました。OpenCVでプログラムを書けばグレースケール化やスレッショルド化の処理も可能ですが、プログラムを書く前に様々なパターンをコマンドラインで試したかったため、まずはFFmpegで、以下のような中間画像の動画を生成できるようにしました。
A. 入力画像(背景=白以外、文字=白)
") B. 入力画像をグレースケール化
B. 入力画像をグレースケール化
 C. グレースケール画像を明るさ230でスレッショルドした結果
C. グレースケール画像を明るさ230でスレッショルドした結果

実際に試してみると、意図どおり、検出したいステージ名(例:デカライン高架下)やルール情報(例:ナワバリバトル)などのメッセージが白色でくっきりと浮き上がっています。
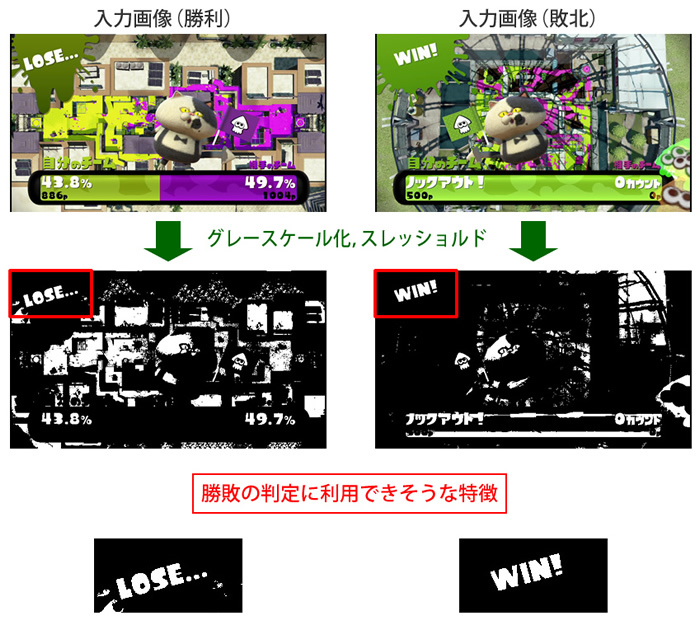
ほかの例を見てみましょう。ゲーム終了後にWIN(勝利)もしくはLOSE(敗北)と表示されるシーンですが、こちらも同じ手順で中間画像を作成すると下記のイメージになり、勝敗の判定に使えるでしょう(ただし、実際のIkaLogはほかの画面で勝敗を判定しています)。
Python、OpenCVとNumPyを利用することにした理由
IkaLogの開発には、画像処理ライブラリであるOpenCV、そして数値計算モジュールNumPyをおもに利用することにしました。
OpenCVはコンピュータビジョンに使われるさまざまな機能やアルゴリズムがライブラリ化されて収録されたものです。
- OpenCV
- http://opencv.org/
OpenCVには、以下のような機能が含まれています。
- 画像ファイルを読み書き
- 画像のフォーマット変換、加工
- 画像に図形や文字列を描画
- 画像処理でよく利用されるフィルタ
- 画像からの特徴量抽出、マッチング、AR処理など
- 画像処理で利用される機械学習
いろいろな機能があるため紹介しきれません(私自身、紹介するとして、内容をすべて把握しているわけではありません)が、「画像処理用のアーミーナイフのようなもの」だと思っていただければいいと思います。
開発を使用言語については、「CやC++よりも手軽に開発できる言語で、OpenCVと相性がいいものを使いたい」と考え、今回はPython 3で進めることにしました。
- Python.org
- http://python.org/
OpenCVには、Python向けバインディングモジュールやサンプルコードが含まれています。また、OpenCVのドキュメントもC/C++のほかPythonによる呼び出し例が説明されているため、ドキュメント類も豊富です。Pythonは「プログラミング言語の中では、OpenCVと相性がいい」と言えるでしょう。
Python上では、多次元配列や行列の演算などをPython上でかんたんに行えるモジュールであるNumPyが利用できます。NumPyは、科学技術計算、統計、また機械学習などの用途でよく利用されます。
- NumPy
- http://www.numpy.org/
NumPyを使ったプログラムは、シンプルに記述でき、しかもモジュール内で計算の最適化もされています。Pythonコード上でNumPyを使って計算すれば(本気で最適化したネイティブコードに敵うわけではありませんが)、割と高速に計算してくれます。チューニングの苦労なしに十分な性能が得られるため、PythonとNumPyの組み合わせは、科学者やデータ分析に関わる方などにも人気があるようです。
IkaLogでは、OpenCVを介して得られた画像データを、大きな配列として扱い、NumPyを用いて計算します。このためNumPyも、OpenCVと同様に、IkaLogにとって欠かせないモジュールだと言えます。
なぜ、OpenCVの画像認識アルゴリズムを使わなかったのか
OpenCVには、先述した画像フォーマットの変換やフィルタリングのほかに、物体検出などのアルゴリズムもたくさん用意されています。OpenCVに含まれている画像認識処理の流れについては、gihyo.jpでも過去に紹介記事が掲載されていますので、そちらをご覧になるといいかと思います。
- OpenCVで学ぶ画像認識
- http://gihyo.jp/dev/feature/01/opencv
私自身も、この記事やインターネット上のリソースを参考に、スプラトゥーンの画面メッセージを認識できるか試し始めました。最初の数日は、先の特集でも触れられているHaar-Like特徴を用いたカスケード型分類器による画像検出を試していました。
Haar-Like特徴によるカスケード型分類器は、多数のポジティブ/ネガティブサンプルに対して機械学習を適用し、検出器を生成することで、画像から類似した特徴をもつ部分を見つけ出せるしくみなのですが、そのためには何百~何千ものサンプルを事前に学習させる必要があります。また、事前の機械学習には大量の計算、つまりは時間が必要になります。
実際に何百もの画像ファイルを準備して学習作業を行ったのですが、その過程でOpenCVに付属する学習ツールが(バグと思われる症状で)クラッシュしてしまったり、何時間もかけて学習させた分類器で画像認識を試みても期待どおりの認識ができないなど、ガックリしてしまいました(OpenCVの問題ではなく、私の使い方に問題があるのだと認識しています)。仮にひとつ、きちんと利用できる分類器が作れたとして、想定される画像パターンが今後数十個になるであろうことを考えると、どれだけの作業量になるか想像もつきません。そのため、カスケード型分類器からはいったん離れ、別のアプローチを探すことにしました。
OpenCVには、そのほかにもテンプレートマッチングという機能が提供されています。カスケード型分類器と同様に、画面中のどこかに目的の画像があれば、それを見つけ出すことができるものです。テンプレートマッチングでは、事前学習に多大な時間を費やす必要はありません。
しかし、関数の仕様やサンプルを見ているうちに、「カスケード型分類器やテンプレートマッチングなどの機能を使うのではなく、もっと単純なアルゴリズムで対応できないか?」と考え始めました。
作成したい「スプラトゥーン画像認識ソフト」で目下必要としている画像認識は、未知の画像に何かの特徴が含まれているかを探し出すものではありません。画像の「決まった座標に」「決まったパターンがあるか」さえ判断できればいいのです。カスケード型分類器やテンプレートマッチングは、そもそも必要とする画像認識の用途にはオーバーキルです。
| マッチングアルゴリズム | Haar-Like特徴によるカスケード型分類器 | テンプレートマッチング | 本当に欲しかったもの |
|---|
| 学習の手間 | 大変 | かんたん | 現実的であればOK |
|---|
| パターンの座業(位置)検出 | 自動的に検出 | 自動的に検出 | 固定でいい |
|---|
| パターンの大きさ検出 | 自動的に検出 | 固定 | 固定でいい |
|---|
このため、もっと単純で明解な画像認識アルゴリズムを適用できないか、検討を始めました。
マスク画像を用いたマッチングの検討
先述のとおり、スプラトゥーンのシステムメッセージの多くは、画面上の決め打ちの座標に、決め打ちの大きさで文字として表示されます。また、先述のスレッショルドフィルタなどの手順によって、文字部分を二値化し、綺麗に抜き出した、グレースケールの中間画像が生成できています。
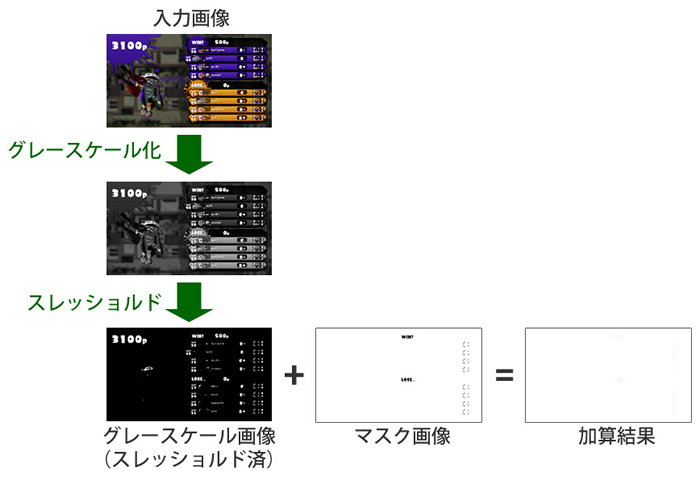
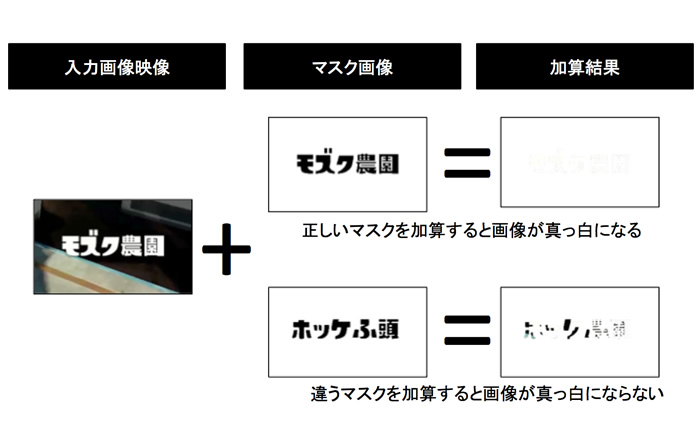
中間画像が256段階のグレースケール画像であれば、黒い部分は0、白い部分は255となったバイトの配列です。そこで、「その中間画像に対して“文字を0、文字以外の部分を255”としたマスク画像を加算すると、画像のすべてのピクセルが白色(255)になることを判定に使えないか?」と考えました。
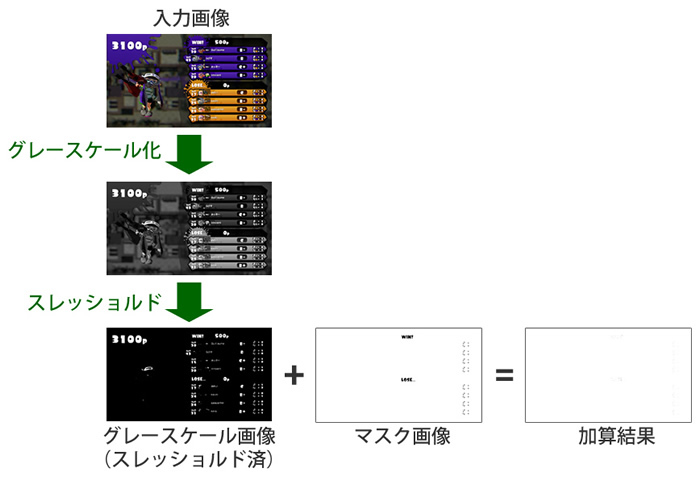
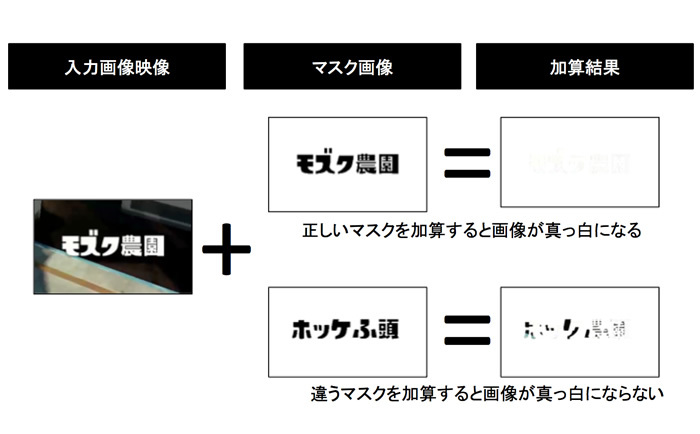
画像の加算処理は、NumPyで配列同士を加算すればOKです。また、画像が真っ白かどうかは、OpenCVの機能でヒストグラムを算出すると、黒~白の分布を調べられます。この結果を見れば、かんたんに判定できそうです。
マスクデータと検知したい画像の加算結果は、原則として真っ白の画像になります。このため、加算後の画像のヒストグラムを生成し、およそ100%白であれば目的の画像である可能性が高いと言えます。ただ、実際にはキャプチャ環境の差により、100%にならない(99.x%など)場合も考えられます。このため、実際のマッチングでは「99%以上が白なら……」といった感じで、判定にはある程度の余裕を持たせています。
また、もともと真っ白な画像は、何を加算しても真っ白ですから、どのようなマスクデータを使ってもマッチしてしまいます。この問題を回避するため、「入力画像をグレースケール化した時点のヒストグラムを確認し、もともと真っ白な画像は無視する」などの工夫も必要でした。
このように、“コンピュータビジョン”と言うにはおこがましいような、たいした方法ではないのですが、このかんたんな考え方の延長でIkaLogにおける画像認識の大半が実現されています。
マスク画像を準備
このアルゴリズムで使用するマスクデータは、ゲーム開始時に表示されるステージ名およびルールの表示内容から生成して用意しました。また、ゲームが終了してスコアボードが表示された場合にも、常に同じ場所に同じ文字や画像が白色で表示されますので、そのパターンに反応するマスクデータとして用意しました。
先述の簡易的な画像認識アルゴリズム、そしてひととおりのマスクデータを組み合わせることで、ゲームの開始・終了および勝敗をPythonスクリプトから判定できるようになりました。
マスク画像を用いた判定回数/秒は?
現在IkaLogで利用しているマッチング処理は、この仕組みをベースに拡張したものを使用しています。マスク画像のサイズにもよりますが、ノートパソコン向けHaswell 2.5GHzで、演算の所要時間は65us~300us程度、秒間およそ3,000回~15,000回のマッチングができる速度です。
アルゴリズムのゴールが違うので単純比較しても意味がないのですが、同じ環境でカスケード型分類器による画像検出には数十ms~数百msを要します(手元でかんたんに確認した結果です)。この所要時間と比較しても、マスク加算方式は、必要十分な画像認識処理が高速にできていると言えるでしょう。また、入力画像に対して、20近くの“特定の画像パターン”が含まれているかを繰り返し調べるIkaLogにとって適したアルゴリズムだと思っています。
これだけの処理性能は、現代のコンピュータの計算能力の賜物ですが、Pythonでカジュアルに書いたコードがまともな最適化もなしに現実的なスピードで動いてくれるのは、OpenCVやNumPyといったライブラリが十分にチューニングされているおかげで、これらに関わられたハードウェア設計者やソフトウェア開発者を拝み倒したい気持ちでいっぱいです。
勝敗の判定
次にチャレンジしたのは、ゲームのリザルト画面でプレイヤーが勝ったのか、負けたのかを判定する機能です。
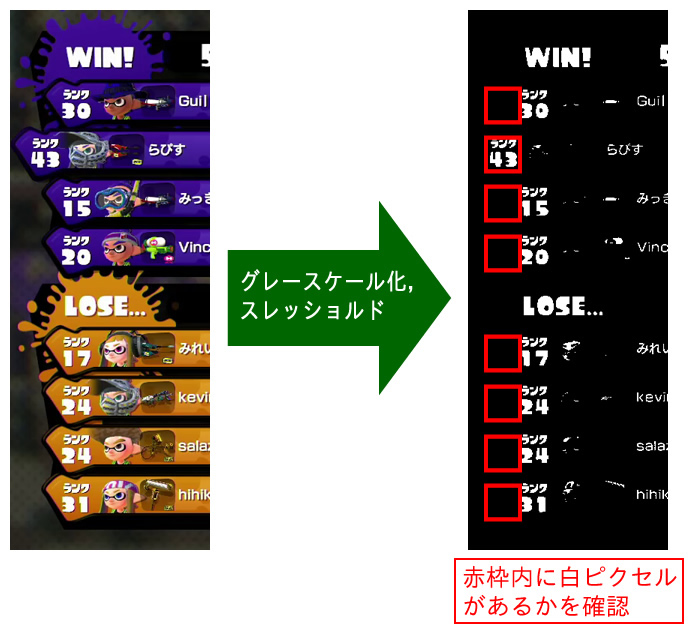
スプラトゥーンで試合が終わると、各プレイヤーの成績が表示されたスコアボード画面が表示されます。この画面では、勝ちチームが画面上段に、負けチームが画面下段に表示されます。また「ローカルのプレイヤーの情報は、ほかのプレイヤーの情報とは横方向の表示位置が違う」という特徴があり、視覚的には「左側に飛び出している」ように見えます。
ゲームに参加した8プレイヤー分の表示内容をチェックし、画像中でプレイヤー情報が左側に飛び出している部分を見つけて、「飛び出しているプレイヤーが何人目であるか」がわかれば、ローカルのプレイヤーはこのゲームに勝利/敗北した、と判断できます。
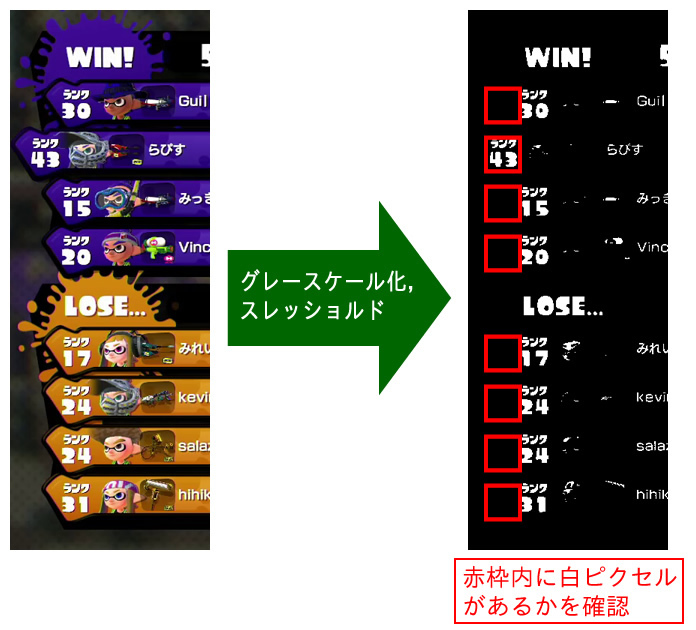
プレイヤーの表示が左側に飛び出しているかどうかは、以下の要領で判定しています。
- カラー画像をグレースケールに変換
- スレッショルドフィルタで2値化
- “飛び出している場合に限り、文字が表示されている範囲”(赤枠)を切り抜いた画像を生成
- その範囲のピクセル値の合計を求めて、スコアとする
- スコアが一定の閾値を超えていれば、そのエントリがローカルのプレイヤーを指している、と判断する
次回予告
今回解説した画像処理により、下記の機能を持つIkaLogのプロトタイプが完成しました。
- OpenCV(+FFmpeg)のビデオ入力機能を用いて、ビデオファイルからフレーム(静止画像)を逐一読み込み
- ゲーム開始時に表示されるステージ名、ルール名を検出
- ゲーム終了時に表示されるスコアボード画面を検出、勝敗を判定
- リザルト画面をスクリーンショット保存
- ステージ名、ルール名、勝敗の結果をCSVファイルに記録
次回は、GitHubへのIkaLogプロジェクト立ち上げ前後で進めた作業、そしてIkaLog公開後1~2ヶ月に起きたことについて紹介していきたいと思います。




")