


こんにちは、
協調フィルタリングとは
協調フィルタリングとは、
協調フィルタリングはユーザのコミュニティや過去の振る舞いを利用して、
ユーザベース協調フィルタリング
もっと具体的に見てみましょう。協調フィルタリングの最も直感的な説明は、
では実際にこれをどう実現しているのでしょうか。今回は簡単な説明のため、
| 商品1 | 商品2 | 商品3 | 商品4 | |
|---|---|---|---|---|
| ユーザーA | 購入 | × | 購入 | × |
| ユーザーB | 購入 | × | × | 購入 |
| ユーザーC | 購入 | 購入 | 購入 | × |
| ユーザーD | × | 購入 | × | × |
このような購入履歴のデータを持っており、

購入した履歴を1、
ユーザ間の類似度を求めるには、
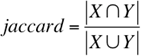
◆相関に関連することと思いますが、
jaccard係数を使ってユーザの類似度を求めた結果が図4です。
| jaccard係数 | |
|---|---|
| ユーザーB | 0. |
| ユーザーC | 0. |
| ユーザーD | 0. |
この jaccard相関係数は、
それでは購入していない商品2と4を推薦するかどうかはどう決定するのでしょうか。商品2のスコアはユーザAの平均評価値に各ユーザの類似度を考慮した重みつきの評価を加えることで計算します。簡易ではありますが今回は次のように実装してみました。
#! /usr/local/bin/python
# -*- coding:utf-8 -*-
import sys
def jaccard(v1, v2):
"""
jacard係数を求める
"""
v1_and_v2 = 0.
v1_or_v2 = 0.
for i in xrange(len(v1)):
if v1[i] == 1 or v2[i] == 1:
v1_or_v2 += 1
if v1[i] == 1 and v2[i] == 1:
v1_and_v2 += 1
try:
return v1_and_v2 / v1_or_v2
except ZeroDivisionError:
return 0.0
def calc_users_similarity(user_id, user_data, sim=jaccard):
"""
userとuserの類似度を求める
"""
users_similarity = {}
for target_id in xrange(len(user_data)):
if target_id == user_id:
continue
users_similarity[target_id] = sim(
user_data[user_id], user_data[target_id])
return users_similarity
def calc_user_average_score(user_id, user_data):
"""
ユーザーの平均スコア
"""
return sum(user_data[user_id]) / len(user_data[user_id])
def userbase_scoring(user_id, item_id, user_data, users_similarity):
"""
userとitemのスコアを求める
"""
if user_data[user_id][item_id] == 1.:
return -1. * sys.maxint
ave_score = calc_user_average_score(user_id, user_data)
bunshi = 0.
bunbo = 0.
for target_id in xrange(len(user_data)):
if target_id == user_id:
continue
bunshi += users_similarity[target_id] * (
user_data[target_id][item_id]
- calc_user_average_score(target_id, user_data)
)
bunbo += users_similarity[target_id]
return ave_score + (bunshi/bunbo)
if __name__ == "__main__":
user_data = [[1., 0., 1., 0.],
[1., 0., 0., 1.],
[1., 1., 1., 0.],
[0., 1., 0., 0.]]
user_id = int(sys.argv[1])
users_similarity = calc_users_similarity(user_id, user_data, sim=jaccard)
for item_id in xrange(len(user_data[0])):
print "item{}:".format(item_id),
print userbase_scoring(user_id, item_id, user_data, users_similarity)結果は図5のようになりました。(実装上ではすでに購入した商品はスコアを-sys,maxintにしています)
| スコア | |
|---|---|
| 商品1 | - |
| 商品2 | 0. |
| 商品3 | - |
| 商品4 | 0. |
この結果から、
アイテムベース協調フィルタリング
次にアイテムベース協調フィルタリングを考えてみましょう。ユーザベースではユーザ間の類似度を計算しましたが、
特徴量の選択
前述の例では購入か購入していないかの2値を利用し、
ユーザの行動は購入履歴以外にも、
また、
どのような特徴を選択するかはそのモデルの精度を決める重要な要素になります。そのため推薦システムで何を実現したいのか、
協調フィルタリングの課題
さて、
- データのスパース性
- コールドスタート問題
- スケーリング
- 同一性
- Shilling Attack
- ノイズ処理
- プライバシー保護
とくにデータのスパース性やコールドスタート問題、
また近年、
コールドスタート問題
ところで、
| 商品1 | 商品2 | 商品3 | 商品4 | 商品5 | |
|---|---|---|---|---|---|
| ユーザーA | 購入 | × | 購入 | × | × |
| ユーザーB | 購入 | × | × | 購入 | × |
| ユーザーC | 購入 | 購入 | 購入 | × | × |
| ユーザーD | × | 購入 | × | × | × |
商品5は新製品なので、
コールドスタート問題への対策もいろいろ研究されています。たとえば前回で紹介した内容ベースフィルタリングと組み合わせハイブリッドなモデルによって解決するといった方法もその1つです。Gunosyではコールドスタート問題に対して、
今後、
メモリベースとモデルベース
協調フィルタリングにはユーザの行動データをすべてメモリに乗せて扱うメモリベースと、
モデルベースの推薦では、
次回は、