はじめに
リレーショナルデータベースが関わる案件において、その開発効率と品質を最も大きく決定する要因は、テーブル設計です。テーブル設計は、工程のかなり初期の段階でなされますが、ここがまずいと、その後の開発全体を無駄に不効率で混乱したものにしてしまい、かつ容易に後戻りがきかないという重要なステップです。したがって、「 はじめにテーブルありき」は何にもまして重要な合言葉です。
しかし、この工程の難しいところは、往々にして一義的な正解を定められないことです。常に「これが正解」と呼べるような決まったアルゴリズムが存在しないのです。もちろん、数十年にわたる多くの人々の努力によって、いくつかの効果的な設計技法や、原則として踏み外してはいけない最低限のルール(可能な限り正規化すること、主キーを必ず設定すること、多対多の関連は作らないこと、等々)は確立されています。それでもなお、DB界の権威であるクリス・デイト氏自ら『データベース設計はきわめて主観的である』と認めなければならないのが、この分野の悩ましいところです。
今回は、上で挙げたような最低限の基礎ルールを踏まえたうえで、使い方次第によっては有用であり得る..しかし万能ではない..いわば「グレーゾーン」に位置する設計方法やモデルを紹介し、そのメリット/デメリットについて考えてみたいと思います。毒にも薬にもなるため、現場での微妙な判断が要求されるものばかりですが、たとえ自ら使うことがなくとも、既存の設計にこうした方法が使われていた場合に対処するためにも、知って損をすることはないでしょう。
稼働環境
Oracle
SQL Server
DB2
Postgre SQL
My SQL
今回の内容は実装のバージョンには依存しません。実際に動作確認を行った環境は「Oracle 10.2.0.1」「 Postgre SQL 8.3」「 My SQL 5.0」です。
単一参照テーブル~テーブルにポリモフィズムは必要か
みなさんも、日々の業務の中では、いろいろなコード体系を使っていると思います。「 都道府県コード」「 顧客コード」「 性別コード」「 疾病コード」など、きっとテーブルにはいろいろな種類のコード列が含まれていることでしょう。中には「年齢階級」や「人口規模の階級」など「階級」という名前で呼ばれているものもありますが、これらもある特定の集団や範囲、概念を指示するという点で同じ働きをするので、ここでは一括して「コード」と呼ぶことにします。
こういうコードを扱う際、重要な存在となるのが、俗に「マスタ(台帳) 」と呼ばれるテーブルです。つまり、コードのすべての集合(県コードなら47種類)を保持しておくテーブルです。SQLを使って帳票を作成するときは、このマスタテーブルを主としてデータテーブルと外部結合 する、という方法が一般的です。
そうすると、このマスタテーブルというのは、基本的にコード体系の数だけ必要ということになります(図1 ) 。
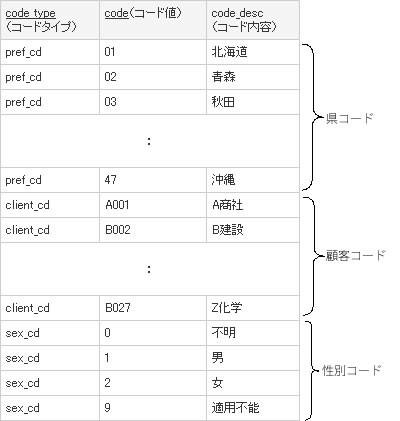
図1 増えていくマスタテーブル都道府県マスタ:PrefMaster
code (コード値) code_desc(コード内容) 01 北海道 02 青森県 03 秋田県 : 47 沖縄県
顧客マスタ:ClientMaster
code (コード値) code_desc(コード内容) A001 A商社 B002 B建設 C003 C保険 : B027 Z化学
性別マスタ:SexMaster
code (コード値) code_desc(コード内容) 0 不明 1 男 2 女 3 適用不能
マスタの数が増えること自体が即座に悪い、というわけではありません。しかし行数の少ない小規模テーブルが増えると、いささかER図も暑苦しくなり、管理する人間の側も一目でシステムの構造を把握できなくなってきます。しかもマスタテーブルの構造は、どれも似たり寄ったり。とすれば、「 いっそこれらのテーブルをすべてひとつにまとめてしまったほうが、すっきりして何かと便利なのではないか?」という発想が出てくるのも、不思議なことではありません。
こうして生まれるのが、いわゆる「One True Lookup Table」略してOTLTです[1] 。あえて訳すなら単一参照テーブルとでもなるでしょうか。具体的には図2 のような構造をとります。
図2 OTLT:雑多なコード体系の寄せ集め
そう、一見しておわかりでしょう。複数のコード体系を1つのテーブルにまとめてしまったのです。あとは、「 コードタイプ」をキーに必要なコードだけ切り出して使用するわけです。たとえば、47都道府県を表側として各県の人口を求めるSQLは、リスト1のようになるでしょう。データテーブルは図3 を使います。実行した結果は図4 のようになります。
リスト1 OTLTを利用して人口一覧を出力する帳票を作成SELECT MASTER.code_value AS pref_cd,
MASTER.code_description AS pref_name,
DATA.population AS pop
FROM OTLT MASTER LEFT OUTER JOIN DataPop DATA
ON MASTER.code_value = DATA.pref_cd
WHERE MASTER.code_type = 'pref_cd';図3 使用するデータテーブル
pref_cd (県コード) population(人口) 01 1000 03 2000 04 1200 05 5000 07 8000
図4 リスト1の結果pref_cd pref_name pop
------- --------- ------
01 北海道 1000
02 青森
03 秋田 2000
04 岩手 1200
05 宮城 5000
06 山形
07 福島 8000
:
47 沖縄 外部結合することによって、データテーブルには含まれていない県(青森や沖縄など)まですべて含む47都道府県の完全なリストが得られる点は、通常のマスタテーブルと変わりません。1つのテーブルが、あるときは「都道府県」の集合になり、またあるときは「顧客」の集合になる、というように七変化するのが、このOTLTの特徴です。呼び出されるたびにテーブルの役割が変わることから、これをオブジェクト指向におけるポリモフィズムになぞらえる論者もいます[2] 。このOTLTを使うことのメリットは、大きく次の3つにまとめられます。
マスタテーブルの数が減るので、ER図やスキーマがシンプルになる
コード検索のSQLを共通化できるため、コーディングを簡略化できる
複数の業務で使用するコード群を一ヵ所で管理できるので、保守/管理が容易になる
こうした実用的なメリットから、OTLTは現場においてしばしば利用されています。私もこのテーブルを実際に開発で使ったことがあります(私が設計したのではなく、プロジェクトに参加したときにはすでに存在していたのですが) 。私がOTLTを使ってみた第一印象は、あまり大きな声では言えないのですが、「 結構便利なものだな」という肯定的なものでした。特に、業務ごとに同じコードのマスタがいくつも分散して作られることを防止するためには、この中央集権的な管理方法は有効に思えました。
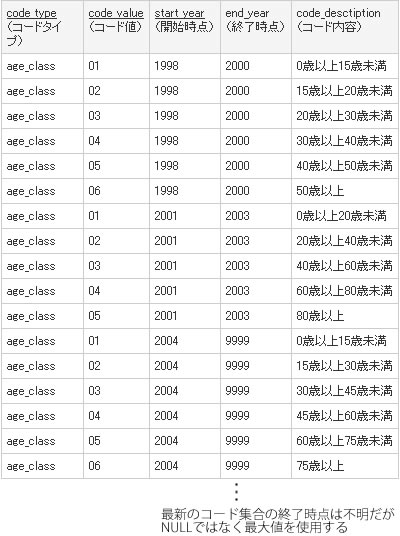
このバリエーションとしてさらに、使用するコードに「寿命」がある場合に対応した「期間範囲つきOTLT」もあります。都道府県コードのように明治維新クラスの革命でも起きないと変更されない体系や、性別のように太古から不変とされてきた体系であれば、有効期限を心配する必要はあまりありません。しかし、年齢階級や商品分類のように、割に決定根拠が恣意的でコロコロ変更される可能性のある体系は、その生存期間に注意しなければなりません。
図5 では、年齢階級を期間別に管理した場合のOTLTを表しています。「 age_class」というコードタイプで参照される点は常に変わりませんが、2002 年のage_class と2005年のage_classは、内容的に別の体系となります。そのため、テーブルの主キーにも、「 開始時点」列を追加する必要があります。このとき、最新の体系の「終了時点」はまだわかっていないのですが、NULLを使ってはいけません。そうすると、たとえば2005年のコード体系を取得しようとしたときに、次のような共通の検索SQLにおいては結果が空になってしまいます。
SELECT code_value, code_description
FROM OTLT
WHERE 2005 BETWEEN start_year AND end_year;
end_yearがNULLだと、比較結果がunknownとなり1行も選択されない 図5 期間範囲つきOTLT:同じコードでも年によって内容が異なる
ところで、このOTLTは、普通の設計技法の書籍には載っていないか、載っていても批判的なコメントが付されています。いわば、非公認の民間療法のような扱いを受けています。なぜかというと、このモデルが次のような無視できない欠点も抱えるからです。
① コードの整合性を保つために、テーブル定義のDDLにCASE式を用いた長大なCHECK制約を書かねばならない(もしこの制約を省略したら、コードの登録/編集する段階でかなりの注意を要する)
② 「 コードタイプ」「 コード値」「 コード内容」の各列とも、どれだけのサイズを用意すればよいかわからないため、余裕を見てかなり大きなVARCHAR型で宣言する必要がある
③ 複数のマスタを使う場合に比べてひとつのテーブルの行数が多くなり、検索のパフォーマンスが悪化する(「 コード値」列の結合時に型変換が発生するとなおさら) 。そして実際、データテーブルのコード値は桁数が固定のため、CHAR型が使われている可能性が高い
④ SQL内でコードタイプやコード値を間違えて指定してもエラーにならず、間違った結果が返される。そのためコーディングの間違いに気づきにくく、潜在的なバグを埋め込む危険が増す
⑤ 「 テーブルは無関係な物の寄せ集めではなく、同一種類の物の集合である」という関係モデルの原理に反する
原理を尊重するDB界のグルたちがこのモデルを公認する気にならないのは、⑤の理由が大きいと思いますが、それ以外にも①~④の理由は実務上でも問題になります。都道府県や性別のように数えるほどしかないのなら、行数が増えすぎることはないでしょうが、何百、何千種類ものコードを保持する場合は、パフォーマンスが悪化します。
また、私は②の欠点のために嫌な経験をしたことがあります。「 コード値」列のサイズがたったの5バイト(!)で宣言されていたため、7バイトのコードを登録できなかったのです。おまけに、さまざまな業務で共通に使うテーブルということが災いして、列のサイズを拡張することも許されず、結局、別にそれ専用のマスタテーブルを作るという本末転倒な結果に終わりました。せめて最初に10バイトぐらいで宣言しておいてくれれば…… でもそうしたら今度は12バイトのコードが登録できないわけで、原理的に同じ問題は常に残ります。
そのようなわけで、OTLTは便利ではあるものの、使う場合はかなり慎重を期する必要があります。複数の業務にまたがった、それこそ名のとおり「唯一の参照マスタ」となる可能性が高く、影響範囲もそれだけ広くなります。