存在の階層
どんな言語にせよそうですが、使い始めてしばらくしたころ、直観的に理解できない癖のようなものに突き当たることが起こります。SQLにも当然、そういう「誰もが一度は通る道」がいくつか存在します。NULLのデータを検索するときに「col = NULL」と書いてしまうことなどがその典型ですが、それと並んで初心者がよく嵌ってしまう間違いが、「 集約キー以外の列をSELECT句に書いてしまう」というものです。
具体的に、図8 の商品テーブルをサンプルに考えてみましょう。
図8 サンプルのテーブル(その2) Items
item_id(商品ID) item_name(商品名) item_group(分類) price(値段) 001 白菜 野菜 100 002 にんじん 野菜 150 003 ピーマン 野菜 150 004 バナナ 果物 100 005 キウイ 果物 200 006 豚バラ 肉類 500 007 ヨーグルト 乳製品 120 008 クリーム 乳製品 400
さて、まずはリスト4 のクエリとその実行結果(図9 )から見てください。商品分類ごとに集計して、各分類の中で一番高い値段を求めています。野菜ならにんじんとピーマンの150円、果物ならキウイの200円。このSQLに疑問のある人はいないでしょう。
リスト4 各分類の中で一番高い値段を求めるクエリSELECT item_group, MAX(price)
FROM Items
GROUP BY item_group;図9 各分類の中で一番高い値段
item_group max 野菜 150 果物 200 肉類 500 乳製品 400
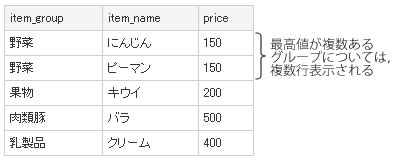
では、このクエリをほんの少しだけ変えたコードを見てみましょう(リスト5 ) 。このクエリを作った意図は、「 最高値の商品名も一緒に表示したい」というものです。多分、期待する結果としては、図10 のようなものをイメージしているのでしょう。分類が「野菜」の行については、最高値の商品が2つあるため、そのうち1つを任意で表示しています。今回は、たまたま「にんじん」を使っています。
リスト5 各分類の中で一番高い値段と商品名を求めようとするクエリSELECT item_group, item_name, MAX(price)
FROM Items
GROUP BY item_group;図10 リスト5を用いて求めたい結果
item_group item_name max 野菜 にんじん 150 果物 キウイ 200 肉類豚 バラ 500 乳製品 クリーム 400
しかし、残念! このクエリは、My SQL以外ではエラーになります(My SQLの場合も、結果は図10のようにはなりません) 。エラーになる理由は、item_nameが集約キー(GROUP BY句に指定される列)ではないからです。
本誌Vol.44の「SQLアタマ養成講座」でも述べましたが、GROUP BY句を使用した場合、SELECT句に書ける要素は次の3つに制限されます。
リスト5のクエリにおけるitem_nameは、このどれにも当てはまらないため、エラーになるわけです。では、なぜそもそもこの3種類以外の要素をSELECT句に記述することが許されないのでしょうか。
一言で言うと、これは存在の階層の差 に起因するものです。GROUP BY句を使うということは、テーブルを小分けにして、文字通りいくつかのグループ(集合)を作るということです。そして、SQLにおいては、こうして作られた集合のほうが、集合に含まれる要素よりも一段レベルの高い、高次の存在と見なされることになっています。
そのため、GROUP BYによって作られたグループに対しては、もともとテーブルに存在していた行の属性は適用できません。適用できるのは、合計、平均、最大といった集合レベルの属性(=統計的な属性)だけです。これが、GROUP BY句を使ったら実質的に集約関数を使わないと意味のある結果が得られない理由です。リレーショナルデータベースにおいて、テーブルの列が理論上「属性(attribute) 」と呼ばれるのも、この理由によります。したがって、My SQLの独自拡張は、要素と集合のレベルを混同したおかしなものなのです。
目的のために手段を選ぶ
さて、理論的な理解はともかく、最高値をつけた商品名も一緒に表示したい、という要望もあるでしょう。これから、そういう場合に対処する方法をいくつか紹介します。
まず、筆者が一番妥当な案と思うのは、次のように相関サブクエリを使うものです(リスト6 ) 。
リスト6 各分類の中で一番高い値段と商品名を求めるクエリSELECT item_group, item_name, price
FROM Items I1
WHERE price = (SELECT MAX(price)
FROM Items I2
WHERE I1.item_group = I2.item_group
GROUP BY item_group);この方法だと、グループ内で最高値をつけた商品名が網羅的に表示されます。したがって、「 野菜」グループのように複数の商品が同点首位の場合、それらの行がすべて表示されます(図11 ) 。
リスト6で重要なポイントは2点あります。まず1つ目は、サブクエリ内で使用している「I1.item_group =I2.item_group」という結合条件です。これによって、商品グループ内に制限した最高値を求めることができます。したがって、この条件(リスト6-❶ の行)をなくしたクエリは、エラーとなります。
図11 リスト6の実行結果
なぜエラーになるかというと、あたりまえですが次のような複数行を返すからです。つまり、このサブクエリが、スカラサブクエリではないからです。
複数行を返すサブクエリを、スカラ演算子である「=」で受けることはできません[1] 。そう、ここが2つ目のポイントなのですが、この場合、正しい結果を得るには、サブクエリはスカラサブクエリでなくてはならないのです。
正確には、リスト6のサブクエリも複数行を返しています。しかし、リスト6-❶ の結合条件を付加することで、計算を「グループ単位」で行うよう指定できます。そして、1つのグループ内では、最大値は常に1つであることが保証されます。だから、事実上スカラサブクエリとして扱われる ため、エラーにはなりません。混乱しがちですがここは重要なポイントなので、よく理解してください。
さて、話を元に戻しましょう。筆者は先ほど、複数の商品が同点首位の場合はそれらをすべて結果に表示するのが良いのではないか、と言いました。ですが要件によっては、あくまで「1グループ1行」という結果にこだわりたい場合もあるでしょう。
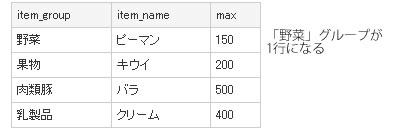
そんなときは、最初のクエリをリスト7 のように変えましょう。実行結果は図12 のようになります。
リスト7 1グループ1行にこだわるクエリ(その1) SELECT item_group, MAX(item_name) AS item_name, MAX(price)
FROM Items I1
WHERE price = (SELECT MAX(price)
FROM Items I2
WHERE I1.item_group = I2.item_group
GROUP BY item_group)
GROUP BY item_group;図12 リスト7の実行結果
外側のクエリにおいて、商品グループで集約すれば、必ずグループ単位で一意になることが保証できます。この場合、問題の「野菜」グループについて、ピーマンとにんじんのどちらを取るかについては特に優先順位はないはずですから、MAX関数を使って適当に選んでいます。MAXは集約関数ですから、GROUP BY句を使った場合にも使用できます。もちろん、MINを使ってもかまいません。
トリッキーな手段
これと同じ結果を求める方法が、もうひとつあります。これもやはりスカラサブクエリを応用するのですが、見る人によってはかなり衝撃的なものです(リスト8 ) 。
リスト8 1グループ1行にこだわるクエリ(その2) SELECT item_group,
(SELECT MAX(item_name)
FROM Items I2
WHERE I1.item_group = I2.item_group
AND I2.price = MAX(I1.price)) AS item_name,
MAX(price)
FROM Items I1
GROUP BY item_group;基本的な考え方はリスト7と同じです。商品グループ単位で最高値をつけた商品の集合に限定し、その中から「MAX(item_name)」によって、適当な商品名を1つ選び出しているのです。だから、このスカラサブクエリも、商品グループについて1行の結果だけを返すため、エラーにならないのです[2] 。
しかし、私たちがSQLを習うときに教えられる原則では、WHERE句に集約関数を書いてはならない はずです。だからこそ、次のようなクエリはエラーになるのです。
SELECT item_name
FROM Items
WHERE price = MAX(price);
すべてのデータベースが、このクエリに対しては「WHERE句で集約関数は使ってはならない」というエラーメッセージを返します。それなのに、リスト8のクエリでは平然と「I2.price = MAX(I1.price)」と、集約関数をWHERE句で使っています。いったい、なぜこんなことが許されるのでしょうか。
これは、SQLの内部動作についての理解度を測る格好の問題なので、演習問題にしましょう。皆さん、理由を考えてみてください。
[2] とはいえ、このクエリは人間だけでなくデータベースエンジンにとってもトリッキーなようで、正しく動作するのは、今のところSQL Server、Postgre SQLなどの一部のデータベースだけです。