



OLAP関数の基本構文
それではOLAP関数の使い方を見ていこうと思います。最初にどんな関数があるのか、
[1] 通常の集約関数 (SUM/ AVG/ COUNT/ MAX/ MIN) をOLAP関数として使う [2] RANK、 ROW_ NUMBERなどOLAP専用の関数
ではまず
テーブルは図1のものを使います。ある銀行の入出金の処理金額を記録するテーブルです。正数は入金を、
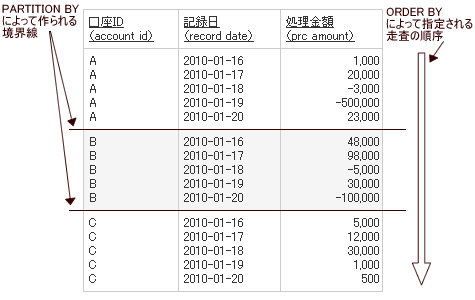
口座テーブル
| 口座ID | 記録日 | 処理金額 |
| A | 2010-01-16 | 1,000 |
| A | 2010-01-17 | 20,000 |
| A | 2010-01-18 | -3,000 |
| A | 2010-01-19 | -500,000 |
| A | 2010-01-20 | 23,000 |
| B | 2010-01-16 | 48,000 |
| B | 2010-01-17 | 98,000 |
| B | 2010-01-18 | -5,000 |
| B | 2010-01-19 | 30,000 |
| B | 2010-01-20 | -100,000 |
| C | 2010-01-16 | 5,000 |
| C | 2010-01-17 | 12,000 |
| C | 2010-01-18 | 30,000 |
| C | 2010-01-19 | 1,000 |
| C | 2010-01-20 | 500 |
さて、
--My SQL以外(ただしSQL ServerではORDER BY句を除外すること)
SELECT account_id,
record_date,
AVG(prc_amt) OVER (PARTITION BY account_id
ORDER BY record_date) AS cumulative_avg
FROM Accounts;
--My SQL
SELECT account_id,
record_date,
prc_amt,
(SELECT AVG(prc_amt)
FROM Accounts A2
WHERE A1.account_id = A2.account_id
AND A1.record_date >= A2.record_date ) AS cumulative_avg
FROM Accounts A1;account_id record_date amount cumulative_avg ---------- ----------- ------ -------------- A 2010-01-16 1,000 1,000 A 2010-01-17 20,000 10,500 A 2010-01-18 -3,000 6,000 A 2010-01-19 -500,000 -120,500 A 2010-01-20 23,000 -91,800 B 2010-01-16 48,000 48,000 B 2010-01-17 98,000 73,000 B 2010-01-18 -5,000 47,000 B 2010-01-19 30,000 42,750 B 2010-01-20 -100,000 14,200 C 2010-01-16 5,000 5,000 C 2010-01-17 12,000 8,500 C 2010-01-18 30,000 15,667 C 2010-01-19 1,000 12,000 C 2010-01-20 500 9,700
AVG関数を使っていますが、
1/16: 1000 = 1000
1/17: 10500 = (1000 + 20000) / 2
1/18: 6000 = (1000 + 20000 + (-3000)) / 3
1/19:-120500 = (1000 + 20000 + (-3000) + (-500000)) / 4
1/20: -91800 = (1000 + 20000 + (-3000) + (-500000) + 23000) / 5通常の集約関数との違い
このクエリには、
このことからもわかるとおり、
- OLAP関数のルール 1
- OLAP関数は見かけ上集約関数を使っているように見えても、
実は集約は一切行っていない
構文上の特徴
さて、
PARTITION BYとORDER BY
OVER句で指定する必要があるのは、
- PARTITION BY
テーブルをどのようなキーでカットするかを指定します。構文はGROUP BY句と同じです。ここで指定したキーでカットされた部分集合を、
パーティションまたはウィンドウ [3] と呼びます。普通に 「グループ」 と呼んでもよいのですが、 それだとGROUP BY句でカットした場合の部分集合 (前述のように集約されることが前提となる) と混同するので、 違う用語が使われているのでしょう。 - ORDER BY
ここでは、
パーティション内部のレコードをどういう順序で走査するかを指定します。構文は、 SELECT文の最後につける普通のORDER BY句とまったく同じで、 昇順/ 降順の指定もASC/ DESCで行います (デフォルトはASCで、 省略するとASC扱いになります)。
いわば、
口座テーブル
PARTITION BY、ORDER BYを省略した場合
なお、
一方、
- OLAP関数のルール 2
- PARTITION BYは省略することもあるが、
ORDER BY句は通常はいつも指定する
OLAP関数を使いこなすコツは、
なお、