



ここはとある街の総合病院。
ここには通常の診療科のほかに、
何軒もの病院をたらいまわしにされた、
それがSQL緊急救命室、
そう、

ロバート
救命室部長。腕の立つエンジニアだが、
(AM10:00 休憩室。ワイリーが机に向かって一人で何かしている)
![]() どってぃろーんどってぃろーん、
どってぃろーんどってぃろーん、
![]()
![]() ああ、
ああ、
![]() なるほど、
なるほど、
![]() そういうことです。どってぃろーん…
そういうことです。どってぃろーん…
![]()
![]() え? ああ、
え? ああ、
UNIONで条件分岐するのは正しいか
![]() ふうん、
ふうん、
問1:商品を管理する図1のようなテーブルItemsが存在する。各商品について、

item_name| year | price ---------+------+------- カップ | 2000 | 500 カップ | 2001 | 520 カップ | 2002 | 630 カップ | 2003 | 630 スプーン | 2000 | 500 スプーン | 2001 | 500 スプーン | 2002 | 525 スプーン | 2003 | 525 ナイフ | 2000 | 600 ナイフ | 2001 | 550 ナイフ | 2002 | 577 ナイフ | 2003 | 420
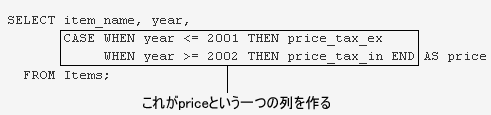
![]() 条件分岐問題の基礎ね。year 列の値を分岐の条件に使う、
条件分岐問題の基礎ね。year 列の値を分岐の条件に使う、
![]() これです。はい!
これです。はい!
SELECT item_name, year, price_tax_ex AS price
FROM Items
WHERE year <= 2001
UNION ALL
SELECT item_name, year, price_tax_in AS price
FROM Items
WHERE year >= 2002;![]() イタタた…。
イタタた…。
![]() 足の小指でもぶつけました?
足の小指でもぶつけました?
![]() いや、
いや、
UNIONを使うと実行計画が冗長になる
ヘレンがなぜ頭痛を覚えてしまったのか、
ワイリーの解は、
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 13 | 611 | 6 (50)| 00:00:01 |
| 1 | UNION-ALL | | | | | |
|* 2 | TABLE ACCESS FULL | ITEMS | 7 | 329 | 3 (0)| 00:00:01 |
|* 3 | TABLE ACCESS FULL | ITEMS | 6 | 282 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("YEAR"<=2001)
3 - filter("YEAR">=2002)
QUERY PLAN
------------------------------------------------------------
Append (cost=0.00..2.42 rows=12 width=47)
-> Seq Scan on items (cost=0.00..1.15 rows=6 width=47)
Filter: (year <= 2001)
-> Seq Scan on items (cost=0.00..1.15 rows=6 width=47)
Filter: (year >= 2002)
このように、
UNIONは便利な道具です。簡単にレコード集合をマージできるため、
SQLにおける正しい条件分岐の書き方がどうなるか、
WHERE句で分岐させるのは素人
![]() いい? SQLを使ううえで、
いい? SQLを使ううえで、
![]() ああ、
ああ、
![]() もし
もし
![]() なるほど…。でもUNIONって、
なるほど…。でもUNIONって、
![]() そのモジュール的思考を脱しない限り、
そのモジュール的思考を脱しない限り、
![]() うっ、
うっ、
SELECT句で分岐させると実行計画もすっきり
ヘレンの解の実行計画を見てみましょう
-------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 12 | 564 | 3 (0)| 00:00:01 | | 1 | TABLE ACCESS FULL | ITEMS | 12 | 564 | 3 (0)| 00:00:01 | --------------------------------------------------------------------------
QUERY PLAN ------------------------------------------------------- Seq Scan on items (cost=0.00..1.18 rows=12 width=51)
SQLのコードの良し悪しは、
集計における条件分岐
(ワイリーとヘレンが話していると、
![]() 遅れたな。なんだ、
遅れたな。なんだ、
![]() 患者といえば患者ね。ワイリーだけど。
患者といえば患者ね。ワイリーだけど。
![]() う、
う、
![]() 細かいこと気にするな。どれ、
細かいこと気にするな。どれ、
![]() ああ、
ああ、
![]() これだけじゃないだろう。次の問題も同じ間違え方してるじゃないか。
これだけじゃないだろう。次の問題も同じ間違え方してるじゃないか。
![]() ああっ見ないで。あとで直そうと思ってたのに。
ああっ見ないで。あとで直そうと思ってたのに。
問2:都道府県別、

prefecture | pop_men | pop_wom -----------+---------+--------- 香川 | 90 | 100 高知 | 100 | 100 徳島 | 60 | 40 愛媛 | 100 | 50 福岡 | 20 | 200
※ pop_
![]() 見ないでって言ったのに…
見ないでって言ったのに…
SELECT prefecture, SUM(pop_men) AS pop_men, SUM(pop_wom) AS pop_wom
FROM ( SELECT prefecture, pop AS pop_men, null AS pop_wom ――┐
FROM Population |①
WHERE sex = '1' --男性 ―――――――――――――――――――――――――――――─┘
UNION
SELECT prefecture, NULL AS pop_men, pop AS pop_wom ――┐
FROM Population |②
WHERE sex = '2') TMP --女性 ―――――――――――――――――――――――――┘
GROUP BY prefecture; ――――③![]() …。
…。
![]() …。
…。
![]() …2人とも、
…2人とも、
![]() お前の白衣の中にゲロをぶちまけたい気分だ。
お前の白衣の中にゲロをぶちまけたい気分だ。
![]() 冗談でもそういうこと言わないでください。
冗談でもそういうこと言わないでください。
![]() さっきも言ったでしょう、
さっきも言ったでしょう、
SELECT prefecture,
SUM(CASE WHEN sex = '1' THEN pop ELSE 0 END) AS pop_men,
SUM(CASE WHEN sex = '2' THEN pop ELSE 0 END) AS pop_wom
FROM Population
GROUP BY prefecture;集計における条件分岐もやっぱりCASE式
この問題は、
ワイリーは、
prefecture | pop_men | pop_wom -----------+---------+--------- 徳島 | 60 | 徳島 | | 40 香川 | 90 | 香川 | | 100 愛媛 | 100 | 愛媛 | | 50 高知 | 100 | 高知 | | 100 福岡 | 20 | 福岡 | | 200
これを県単位に1 行に集約する必要があるため、
(病院の外からサイレンが聞こえる。救急車が到着したようだ)
![]() ほ、
ほ、
![]() あ、
あ、

(手術室に患者が運ばれてくる。患者を見た3人が驚いたことに…)
![]() あら、
あら、
![]() しかも重症だ。良かったな、
しかも重症だ。良かったな、
![]() …はい、
…はい、
カルテ:社員とその所属するチームを管理するテーブルEmployeesがある
- ①所属するチームが1つだけの社員は、
1列にそのチーム名を表示する - ②所属するチームが2つの社員は、
「2つを兼務」 という文字列を表示する - ③所属するチームが3つ以上の社員は、
「3つ以上を兼務」 という文字列を表示する
結果は図11のようになるはずである。

emp_name | team ------------+------------------ Jim | 開発 Bree | 3つ以上を兼務 Joe | 3つ以上を兼務 Carl | 営業 Kim | 2つを兼務
UNIONで分岐させるのは簡単だが…
![]() ワイリー、
ワイリー、
![]() こうですね。
こうですね。
- ① Jim、
Carl - ② Kim
- ③ Bree、
Joe
![]() OK。患者のコードは、
OK。患者のコードは、
SELECT emp_name, ―――――┐
MAX(team) AS team │
FROM Employees │①
GROUP BY emp_name │
HAVING COUNT(*) = 1 ―――――┘
UNION
SELECT emp_name, ―――――――┐
'2つを兼務' AS team │
FROM Employees │②
GROUP BY emp_name │
HAVING COUNT(*) = 2 ――――――┘
UNION
SELECT emp_name, ――――――――┐
'3つ以上を兼務' AS team │
FROM Employees │③
GROUP BY emp_name │
HAVING COUNT(*) >= 3; ――――――┘![]() 自分でもきっとこう書いただろうから、
自分でもきっとこう書いただろうから、
![]() この問題のおもしろいところは、
この問題のおもしろいところは、
SELECT emp_name,
CASE WHEN COUNT(*) = 1 THEN MAX(team)
WHEN COUNT(*) = 2 THEN '2つを兼務'
WHEN COUNT(*) >= 3 THEN '3つ以上を兼務'
END AS team
FROM Employees
GROUP BY emp_name;集約結果に対する分岐もSELECT句で
患者のコード
Oracleで、
----------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | ----------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 33 | 792 | 15 (80)| 00:00:01 | | 1 | SORT UNIQUE | | 33 | 792 | 15 (80)| 00:00:01 | | 2 | UNION-ALL | | | | | | |* 3 | FILTER | | | | | | | 4 | HASH GROUP BY | | 11 | 396 | 5 (40)| 00:00:01 | | 5 | TABLE ACCESS FULL | EMPLOYEES | 11 | 396 | 3 (0)| 00:00:01 | |* 6 | FILTER | | | | | | | 7 | HASH GROUP BY | | 11 | 198 | 5 (40)| 00:00:01 | | 8 | TABLE ACCESS FULL | EMPLOYEES | 11 | 198 | 3 (0)| 00:00:01 | |* 9 | FILTER | | | | | | | 10 | HASH GROUP BY | | 11 | 198 | 5 (40)| 00:00:01 | | 11 | TABLE ACCESS FULL | EMPLOYEES | 11 | 198 | 3 (0)| 00:00:01 | ----------------------------------------------------------------------------------- Predicate Information (identified by operation id): --------------------------------------------------- 3 - filter(COUNT(*)=1) 6 - filter(COUNT(*)=2) 9 - filter(COUNT(*)>=3)
-------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 11 | 396 | 4 (25)| 00:00:01 | | 1 | HASH GROUP BY | | 11 | 396 | 4 (25)| 00:00:01 | | 2 | TABLE ACCESS FULL | EMPLOYEES | 11 | 396 | 3 (0)| 00:00:01 | --------------------------------------------------------------------------------
ロバートの解は、
SELECT句においては、
先ほどはヘレンが
手続き型と宣言型
![]() うーん…。
うーん…。
![]() 何だ、
何だ、
![]() どんな顔ですか。いや、
どんな顔ですか。いや、
![]() ??
??
![]() ??
??
![]() いや、
いや、
![]() ほう、
ほう、
![]() スキーマ問題ね。
スキーマ問題ね。
![]() 隙間?
隙間?
![]() スキーマ
スキーマ
![]() そうだ。ワイリー、
そうだ。ワイリー、
![]() はあ、
はあ、
![]() ふむ。まあすぐにわからんのはしかたあるまい。どうせ今後も常についてまわる問題だ。詳しく説明する機会もあるだろう。
ふむ。まあすぐにわからんのはしかたあるまい。どうせ今後も常についてまわる問題だ。詳しく説明する機会もあるだろう。
![]() とりあえず、
とりあえず、
![]() うっ、
うっ、
終わりに
SQLの初心者
一方、
手続き型の世界から宣言型の世界へ、
【参考資料】
- 1.ミック
「CASE式のススメ (前編)/ (後編)」 - 本稿でも見たように、
SQLで条件分岐を表現するにはCASE式を使います。逆に言うと、 もし分岐をCASE式以外で表現していたら、 そのSQLは間違えている可能性が高い、 と考えてください。 - 2.Joe Celko
『SQLパズル 第2版』 (翔泳社、 2007年) - 本書はすばらしいコードサンプルの宝庫です。SQLにおける分岐を練習する問題としては、
「パズル13:2人かそれ以上か、 それが問題だ」 「パズル36:1人2役」 が最適です。 - 3.ミック WEB+DBVol.
60 連載 「DBアタマアカデミー」 第4回 「クエリ評価エンジンと実行計画」 - 実行計画の読み方、
DBMS内部でのSQLの実行のされ方などについて知りたい方はこちらを読むと基礎的なことがわかります。gihyo. jp でも公開しております。 - 3.ミック WEB+DBVol.