



目次
Part1 基本編
第1章 PostgreSQL“超”入門
- 1.1 呼び方
- 1.2 データベースとしての分類
- 1.3 歴史
- Column メジャーバージョンとマイナーバージョン
- 1.4 ライセンス
- 1.5 コミュニティ
第2章 アーキテクチャの基本
- 2.1 プロセス構成
- 2.1.1 マスタサーバプロセス
- 2.1.2 ライタプロセス
- 2.1.3 WALライタプロセス
- 2.1.4 チェックポインタプロセス
- 2.1.5 自動バキュームランチャと自動バキュームワーカプロセス
- 2.1.6 統計情報コレクタプロセス
- 2.1.7 バックエンドプロセス
- 2.1.8 パラレルワーカプロセス
- 2.2 メモリ管理
- 2.2.1 共有メモリ域
- 2.2.2 プロセスメモリ
- 2.3 ファイル
- 2.3.1 主なディレクトリ
- 2.3.2 主なファイル
第3章 各種設定ファイルと基本設定
- 3.1 設定ファイルの種類
- 3.2 postgresql.confファイル
- 3.2.1 設定項目の書式
- 3.2.2 設定の参照と変更
- 3.2.3 設定項目の反映タイミング
- 3.2.4 設定ファイルの分割と統合
- Column コマンドラインパラメータによる設定
- 3.2.5 ALTER SYSTEMコマンドによる変更
- 3.3 pg_hba.confファイル
- 3.3.1 記述形式
- 3.3.2 接続方式
- Column SSL接続
- 3.3.3 接続データベース
- Column ログイン属性
- 3.3.4 接続ユーザ
- Column 特殊な名前のデータベースとユーザ
- 3.3.5 接続元のIPアドレス
- 3.3.6 認証方式
- Column pg_hba_file_rulesビュー
- 3.4 pg_ident.confファイル
第4章 処理/制御の基本
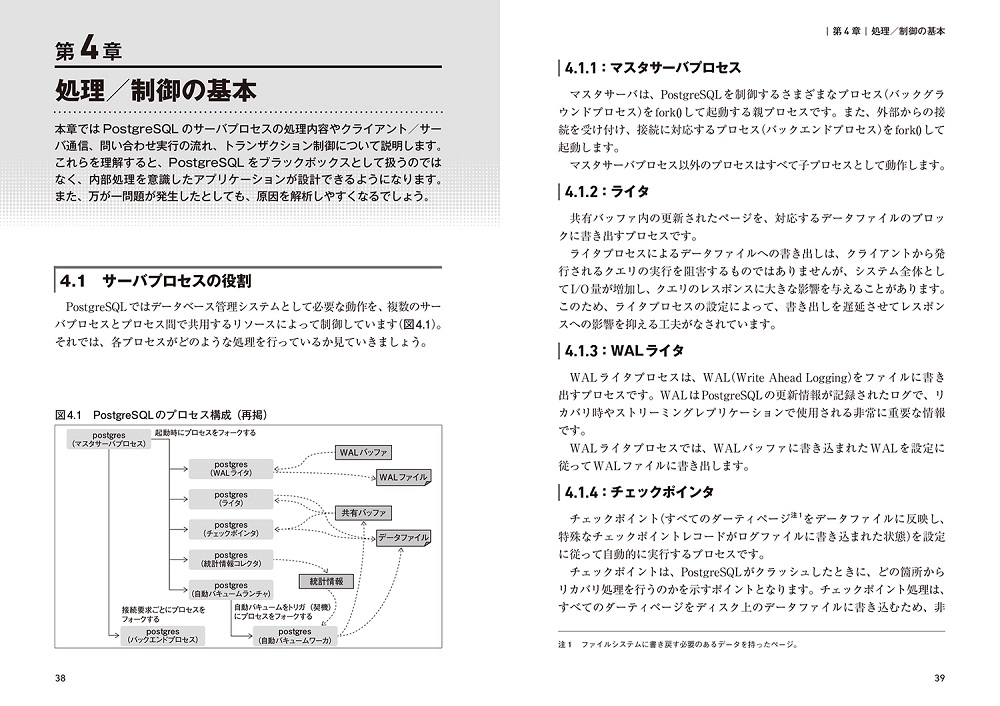
- 4.1 サーバプロセスの役割
- 4.1.1 マスタサーバプロセス
- 4.1.2 ライタ
- 4.1.3 WALライタ
- 4.1.4 チェックポインタ
- 4.1.5 自動バキュームランチャと自動バキュームワーカ
- 4.1.6 統計情報コレクタ
- 4.1.7 バックエンドプロセス
- Column バックグラウンドワーカプロセス
- 4.2 クライアントとサーバの接続/通信
- 4.3 問い合わせの実行
- 4.3.1 パーサ
- 4.3.2 リライタ
- 4.3.3 プランナ/オプティマイザ
- 4.3.4 エグゼキュータ
- 4.3.5 SQLの種別による動作
- 4.4 トランザクション
- 4.4.1 トランザクションの特性
- 4.4.2 トランザクションの制御
- 4.4.3 トランザクションの分離レベル
- Column postgres_fdwのトランザクション分離レベル
- 4.5 ロック
- Column 勧告的ロック
- 4.6 同時実行制御
Part2 設計/計画編
第5章 テーブル設計
- 5.1 データ型
- 5.1.1 文字型
- Column 内部的に使用される文字型
- Column char型に対する文字列操作の注意点
- 5.1.2 数値データ型
- 5.1.3 日付/時刻データ型
- Column アンチパターン:文字型で日時を管理する
- 5.1.4 バイナリ列データ型
- Column JSON型とJSONB型
- Column 型名のエイリアス
- 5.2 制約
- 5.2.1 主キー
- 5.2.2 一意性制約とNOT NULL制約
- 5.2.3 外部キー制約
- 5.2.4 検査制約
- Column 検査制約の適用順序
- Column 生成列
- 5.3 PostgreSQL固有のテーブル設計
- 5.3.1 TOASTを意識したテーブル設計
- Column TOAST圧縮方式
- 5.3.2 結合を意識したテーブル設計
- Column 遺伝的問い合わせ最適化
- 5.4 ビューの活用
- 5.4.1 ビュー
- 5.4.2 マテリアライズドビュー
- 5.5 パーティションテーブルの活用
- 5.5.1 パーティショニング概要
- 5.5.2 宣言的パーティショニングでサポートされる分割方式
- 5.5.3 パーティショニング利用要否の判断
- 5.5.4 パーティションテーブルの設計方針
第6章 物理設計
- 6.1 各種ファイルのレイアウトとアクセス
- 6.1.1 PostgreSQLのテーブルファイルの実体
- 6.1.2 テーブルファイル
- Column テーブルアクセスメソッド
- 6.1.3 インデックスファイル
- 6.1.4 テーブルファイルに対するアクセス
- 6.2 WALファイルとアーカイブファイル
- 6.2.1 WALファイル
- Column WALセグメントサイズ
- 6.2.2 アーカイブファイル
- 6.3 HOTとFILLFACTOR
- 6.3.1 HOT
- 6.3.2 FILLFACTOR
- Column FILLFACTORの確認方法
- 6.4 データ配置のポイント
- 6.4.1 base領域
- 6.4.2 WAL領域
- 6.4.3 アーカイブ領域
- 6.5 テーブル空間とテーブルパーティショニング
- 6.5.1 テーブルパーティショニングとの組み合わせ
- Column 別のテーブル空間へのデータベース・オブジェクトの一括移動
- 6.6 性能を踏まえたインデックス定義
- 6.6.1 インデックスの概念
- 6.6.2 更新に対するインデックスの影響
- 6.6.3 複数列インデックス使用時の注意
- 6.6.4 関数インデックスの利用
- 6.6.5 部分インデックスの利用
- Column インデックスの種類
- 6.7 文字エンコーディングとロケール
- 6.7.1 文字エンコーディング
- 6.7.2 ロケール
第7章 ロール設計
- 7.1 データベースセキュリティ設計の概要
- 7.2 PostgreSQLにおけるロールの概念
- 7.2.1 PUBLICロール
- 7.2.2 定義済みロール(Predefined Roles)
- Column publicスキーマに対するセキュリティ強化(PostgreSQL 15)
- 7.3 ロールの設計方針
- 7.3.1 PostgreSQLにおける職務分掌・最小権限の対応機能
- 7.3.2 管理者ユーザと一般ユーザの分離の例
- 7.3.3 設計が必要な要素
- Column 監査のためのロールの分離
- 7.4 ロール設計のサンプル
- Column createuser/dropuserクライアントユーティリティ
第8章 バックアップ計画
- 8.1 最初に行うこと
- 8.2 PostgreSQLのバックアップ方式
- 8.2.1 オフラインバックアップ
- 8.2.2 オンラインバックアップ
- 8.3 主なリカバリ要件/バックアップ要件
- 8.3.1 要件と方式の整理方法
- 8.4 各バックアップ方式の注意点
- 8.4.1 コールドバックアップの注意点
- 8.4.2 オンライン論理バックアップの注意点
- 8.4.3 オンライン物理バックアップの注意点
- 8.4.4 データ破損に対する注意事項
- 8.5 バックアップ/リカバリ計画の例
- 8.5.1 バックアップの取得方法
- 8.5.2 バックアップファイルの管理
- Column バックアップ世代管理機能について
第9章 監視計画
- 9.1 監視とは
- 9.2 監視項目の選定
- 9.2.1 「サーバに問題が起きていないか」の監視
- 9.2.2 「PostgreSQLに問題が起きていないか」の監視
- 9.3 サーバログの設定
- 9.3.1 ログをどこに出力するか
- 9.3.2 ログをいつ出力するか
- 9.3.3 ログに何を出力するか
- 9.3.4 ログをどのように保持するか
- 9.4 異常時の判断基準
第10章 サーバ設定
- 10.1 CPUの設定
- 10.1.1 クライアント接続設定
- 10.1.2 ロックの設定
- 10.2 メモリの設定
- 10.2.1 OSのメモリ設定
- 10.2.2 PostgreSQLのメモリ設定
- 10.2.3 HugePage設定
- 10.3 ディスクの設定
- 10.3.1 OSのディスク設定
- 10.3.2 PostgreSQLのディスク設定
Part3 運用編
第11章 高可用化と負荷分散
- 11.1 サーバの役割と呼び名
- 11.2 ストリーミングレプリケーション
- 11.2.1 ストリーミングレプリケーションの仕組み
- Column pg_resetwalコマンド
- 11.2.2 可能なレプリケーション構成
- 11.2.3 レプリケーションの状況確認
- 11.2.4 レプリケーションの管理
- 11.2.5 設定手順の整理
- 11.3 PostgreSQLで構成できる3つのスタンバイ
- 11.3.1 それぞれのメリットとデメリット
- 11.3.2 コールドスタンバイ
- 11.3.3 ウォームスタンバイ
- 11.3.4 ホットスタンバイ
- 11.4 ホットスタンバイ
- 11.4.1 ホットスタンバイで実行可能なクエリ
- 11.4.2 ホットスタンバイの弱点はコンフリクト
- 11.5 ストリーミングレプリケーションの運用
- 11.5.1 フェイルオーバ時の処理
- 11.5.2 プライマリ/スタンバイの監視
- 11.5.3 プライマリ/スタンバイの再組み込み時の注意点
- Column pg_rewindによる巻き戻し
- 11.5.4 コンフリクトの緩和策
- Column レプリケーションスロット
第12章 論理レプリケーション
- 12.1 論理レプリケーションの仕組み
- 12.1.1 ロジカルデコーディングとバックグラウンドワーカ
- 12.1.2 論理レプリケーションの制限事項
- Column 長時間続くトランザクションのレプリケーション
- 12.2 パブリケーションとサブスクリプション
- 12.3 可能なレプリケーション構成
- 12.4 レプリケーションの状況確認
- 12.4.1 サーバログの確認
- 12.4.2 プロセスの確認
- 12.4.3 レプリケーション遅延の確認
- 12.5 レプリケーションの管理
- 12.5.1 レプリケーションスロットの対処
- 12.6 論理レプリケーション構成の構築例
- 12.6.1 パブリッシャの設定
- 12.6.2 サブスクライバの設定
- 12.6.3 動作確認
- 12.7 論理レプリケーションの運用
- 12.7.1 コンフリクトの対処
第13章 オンライン物理バックアップ
- 13.1 オンライン物理バックアップの仕組み
- Column pg_basebackupコマンドのメリット
- 13.1.1 pg_start_backup関数の処理内容
- Column 並行したバックアップ取得の制御
- 13.1.2 pg_stop_backup関数の処理内容
- 13.1.3 backup_labelとバックアップ履歴ファイルの内容
- 13.1.4 WALのアーカイブの流れ
- 13.2 PITRの仕組み
- 13.2.1 WALレコード適用までの流れ
- 13.2.2 pg_controlファイル
- 13.2.3 リカバリ設定
- Column タイムラインとリカバリ
- 13.3 バックアップ/リカバリの運用手順
- 13.3.1 バックアップ手順
- 13.3.2 リカバリ手順
第14章 死活監視と正常動作の監視
- 14.1 死活監視
- 14.1.1 サーバの死活監視
- 14.1.2 PostgreSQLの死活監視(プロセスの確認)
- Column プロセス確認の落とし穴
- 14.1.3 PostgreSQLの死活監視(SQLの実行確認)
- 14.2 正常動作の監視
- 14.2.1 サーバの正常動作の監視
- 14.2.2 PostgreSQLの正常動作の監視
第15章 テーブルメンテナンス
- 15.1 なぜテーブルメンテナンスが必要か
- 15.2 バキュームの内部処理
- 15.2.1 不要領域の再利用
- Column VACUUMのオプション
- 15.2.2 トランザクションID(XID)周回問題の回避
- 15.3 自動バキュームによるメンテナンス
- 15.3.1 自動バキュームの進捗状況の確認
- 15.4 VACUUM FULLによるメンテナンス
- 15.4.1 VACUUMが機能しないケース(例)
- 15.4.2 VACUUM FULL実行時の注意点
- 15.4.3 VACUUM FULLの進捗状況の確認
- 15.5 テーブル統計情報の更新
- 15.5.1 自動バキュームによるテーブル統計情報の更新
- 15.5.2 テーブル統計情報の個別設定
第16章 インデックスメンテナンス
- 16.1 インデックスメンテナンスが必要な状況
- 16.1.1 インデックスファイルの肥大化
- 16.1.2 インデックスファイルの断片化
- 16.1.3 クラスタ性の欠落
- 16.2 【予防策】インデックスファイルの肥大化
- 16.3 【改善策】インデックスファイルの断片化
- 16.4 【改善策】クラスタ性の欠落
- 16.4.1 CLUSTER実行時の基準となるインデックス
- 16.4.2 CLUSTER実行時の注意点
- Column CREATE INDEXやCLUSTERコマンドの進捗確認
- 16.5 インデックスオンリースキャンの利用
- 16.5.1 インデックスオンリースキャンの利用上の注意
- Column カバリングインデックスの利用
Part4 チューニング編
第17章 実行計画の取得/解析
- 17.1 最適な実行計画が選ばれない
- 17.1.1 PostgreSQLが原因となる場合
- 17.1.2 PostgreSQL以外が原因となる場合
- 17.2 実行計画の取得方法
- 17.2.1 EXPLAINコマンド
- 17.2.2 ANALYZEコマンド
- 17.2.3 統計情報取得のためのパラメータ設定
- Column システムカタログ「pg_statistic」とシステムビュー「pg_stats」
- 17.2.4 実行計画を自動収集する拡張モジュール「auto_explain」
- 17.2.5 拡張統計情報(CREATE STATISTICS)
- 17.3 実行計画の構造
- Column JITコンパイル(Just-In-Time Compilation)
- 17.3.1 スキャン系ノード
- 17.3.2 複数のデータを結合するノード
- 17.3.3 データを加工するノード
- 17.3.4 そのほかのノード
- 17.4 パラレルクエリ
- 17.4.1 パラレルクエリとは
- 17.4.2 パラレルクエリのチューニング
- 17.4.3 集約関数・集約処理の使用
- 17.5 実行計画の見方
- 17.5.1 処理コストの見積もり
- 17.5.2 処理コスト見積もりのパラメータ
- 17.6 処理コスト見積もりの例
- 17.6.1 シンプルなシーケンシャルスキャンの場合
- 17.6.2 条件付きシーケンシャルスキャンの場合
- 17.6.3 ソート処理の場合
- 17.6.4 インデックススキャンの場合
- 17.6.5 見積もりと実行結果の差
第18章 パフォーマンスチューニング
- 18.1 事象分析
- 18.1.1 PostgreSQLログの取得
- 18.1.2 テーブル統計情報の取得
- 18.1.3 クエリ統計情報の取得
- 18.1.4 システムリソース情報の取得
- 18.2 事象分析の流れ
- 18.3 スケールアップ
- 18.3.1 【事例1】SSDへの置き換えが有効なケース
- 18.3.2 【事例2】メモリ容量の拡張が有効なケース
- 18.4 パラメータチューニング
- 18.4.1 【事例3】work_memのチューニング
- 18.4.2 【事例4】チェックポイント間隔のチューニング
- 18.4.3 【事例5】統計情報のチューニング
- 18.4.4 【事例6】パラレルスキャン
- 18.5 クエリチューニング
- 18.5.1 【事例7】ユーザ定義関数のチューニング
- 18.5.2 【事例8】インデックスの追加
- 18.5.3 【事例9】カバリングインデックスの利用
- 18.5.4 【事例10】プリペアド文による実行計画再利用の設定
- 18.5.5 【事例11】テーブルデータのクラスタ化
Appendix PostgreSQLのバージョンアップ
- A.1 PostgreSQLのバージョンアップポリシー
- A.2 バージョンアップの種類
- A.2.1 マイナーバージョンアップ
- A.2.2 メジャーバージョンアップ
- A.3 マイナーバージョンアップの手順
- A.4 ローリングアップデート
- A.5 メジャーバージョンアップの手順
- A.5.1 ダンプ/リストアによるデータ移行方式
- A.5.2 pg_upgradeコマンドによるデータ移行方式
- A.5.3 論理レプリケーションによるデータ移行方式
- A.5.4 拡張機能を使った場合の注意点