


目次
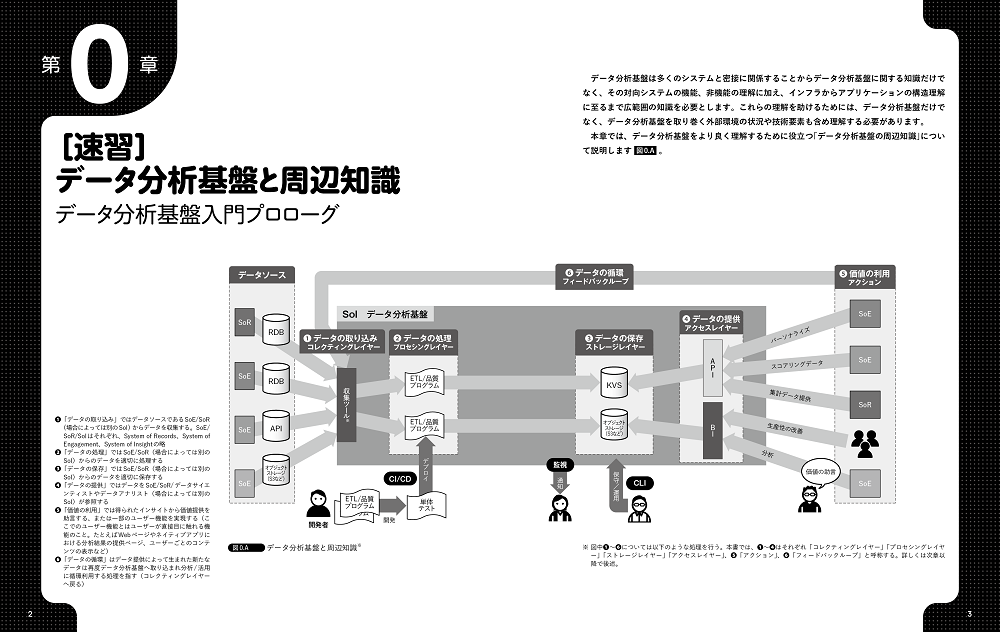
第0章 [速習]データ分析基盤と周辺知識 データ分析基盤入門プロローグ
0.1 データ分析基盤とサービスの提供先 サービスの提供先は4つに分類される
- SoR/SoE/SoI システムは3つに分類される
- データ分析基盤とSoR/SoE/SoI/人 SoIはサービスの提供先とのハブ
0.2 データ分析基盤と周辺技術 データ開発以外でも利用するツールも活躍
- データ分析基盤から見たデータベースとストレージ 役割が異なるストレージとデータベースを使いこなそう
- オブジェクトストレージ データ分析基盤でデータを保存するといったらここ
- RDB オーソドックスなデータベース
- KVS 高速なアクセスを提供するデータベース
- Web API システムを疎結合するためのインターフェース
0.3 データ分析基盤と外部との接点を理解しよう データ分析基盤もユーザー接点が大事
- データの可視化 データの可視化により行動の変革を促す
- 外部への付加価値の提供 データをアプリケーションと連携していこう
0.4 データ分析基盤開発とサポートツール データ開発以外でも利用するツールも活躍
- 単体テスト テストの基本はデータ分析基盤も同じ
- CI/CD 自動化してデータとシステムの品質を上げよう
- コマンドライン オペレーションの効率を高める
- 監視/運用 監視対象を決め継続的に状況を可視化し対策する
0.5 本章のまとめ
第1章 [入門]データ分析基盤 データ分析基盤を取り巻く「人」「技術」「環境」
1.1 データ分析基盤の変遷 多様化を受け入れるために進化する
- データとは何か パターンと関係を捉えるための情報源
- 構造データと非構造データ
- データ分析基盤とは何か パターンと関係を知るためのツールの一つ
- データ分析基盤の変遷 単一のノードから複数ノードへ
- シングルノード時代 個人のPCで分析する時代
- マルチノード/クラスター時代 限られたグループで基盤を利用して分析する時代
- クラウド時代 全社員が分析する時代
- 主要なクラウド関連のプロダクトとデータ利用の流れ
- データ分析基盤が持つ役割 データレイク,データウェアハウス,データマートという名称
- データレイク 非構造データを保持する役割
- データウェアハウス 構造化されたデータを保持する役割
- データマート テーブルを掛け合わせたデータを保持する役割
- データレイク,データウェアハウス,データマートの違い データ量の規模は関係ない
1.2 処理基盤/クラスターの変遷 よりマネージレスにしてコストを減らし,より本来の業務へ集中する時代
- 分散処理の登場 Hadoop MPP,そしてオンプレミスからクラウドへ
- スレッド処理と,マルチノードにおける分散処理 従来のスレッド処理との違いに注目
- Hadoopの登場 Hadoopエコシステムとその進化
- MPPDBの登場 RDBの技術要素をビッグデータにも
- クラウドでのマネージレスなクラスターの登場(Hadoop,Kubernetes,MPPDB) Hadoopがクラウドへ
1.3 データの変遷 ExcelからWeb,IoT,そして何でもあり(!?)へ
- 増え続けているデータ 有り余るほどあるデータ
- 重要性や認知を増すデータ 意思決定の大半はデータにより行われる
- 機密性を増すデータ 個人識別情報が含まれるのが普通
- 種類の増すデータ 決済情報,ログデータ,ストリーミングなど
- 活用方法の拡大 不正検知,パーソナライズ,機械学習,AI,検索
1.4 データ分析基盤に関わる人の変遷 データにまつわる多様な人材
- データエンジニアのスキルセット 全米で急上昇な仕事8位(IT業界以外含む)
- データエンジニアリング領域
- データエンジニアに求められる知識 データエンジニアとスモールシステムの知識
- データサイエンティストのスキルセット データから価値を掘り出す
- データアナリストのスキルセット データから価値を見い出す
1.5 データへの価値観の変化 データ品質の重要度が高まってきた
- 量より質=Quality beats quantity
- データ品質とデータ管理への注目度が高まっている
1.6 データに関わる開発の変遷 複雑化するプロダクトと人の関係
- データエンジニア中心のシステム 何をするにもデータエンジニアを介さなければならなかった
- とりあえずエンジニアに頼む 一部の玄人しか利用できない基盤
- DataOpsチームの登場 価値のあるものを選択し素早くデータを届けることに価値を置く
- セルフサービスモデルの登場 各個人に権限を委譲,大人数で長期間運用することを前提とした構成
1.7 本章のまとめ
第2章 データエンジニアリングの基礎知識 4つのレイヤー
2.1 データエンジニアリングの基本 ポイントと本書内の関連章について
- みんなにデータを届けよう ニーズを押さえた品質の高いインターフェース
- パフォーマンスとコストの最適化 パーティション,圧縮,ディストリビューション
- データドリブンの土台 数値で語る
- シンプルイズベスト
2.2 データの世界のレイヤー データ分析基盤の世界を俯瞰する
- データ分析基盤の基本構造 データ分析基盤を俯瞰する
- コレクティングレイヤー データを収集するレイヤー
- プロセシングレイヤー 収集したデータを処理するレイヤー
- ストレージレイヤー 収集したデータを保存するレイヤー
- アクセスレイヤー ユーザーとの接点となるレイヤー
2.3 コレクティングレイヤー データを集める
- ストリーミング 絶え間なくデータを処理する
- バッチ 一定以上の塊のデータを処理する
- プロビジョニング ひとまず仮にデータを配置する
- イベントドリブン イベントが発生したら都度処理を行う
2.4 プロセシングレイヤー データを変換する
- ETL 次の入力のためにデータを変換する
- データラングリング データに対する付加価値をつける
- データラングリングの3つの作業
- データストラクチャリング データを構造化する
- データクレンジング データの精度を高める
- データエンリッチング データ分析のための準備作業
- ETLとデータラングリングの違い データに対する付加価値をつける
- 暗号化/難読化/匿名化 データを推測しづらくしてセキュリティやプライバシーに配慮する
- トランスペアレントエンクリプション シンプルな暗号化方式
- エクスプリシットエンクリプション 機密データの暗号方式
- ハッシュ化 元のデータをわかりにくく変換する
- ディアイデンティフィケーション 特定しにくくする難読化手法の一つ
- 匿名化と匿名加工 個人情報を復元できないようにする加工
- データ品質/メタデータ計算 データの状態を可視化する
- モデルの作成 世の中の事象をルールに当てはめる
- モデルを利用した推論 データをルールに通したらどうなったのか
- リバースETL データを外部システムに連携する
2.5 データ分析基盤におけるデータの種別とストレージ戦略 プロセスデータ,プレゼンテーションデータ,メタデータにおける保存先の選択
- プロセスデータ/プレゼンテーションデータ/メタデータ データの種別と利用用途の組み合わせにより格納場所が変わる
- 各種データとデータ置き場オーバービュー データの種類とアクティビティによって保存先を使い分けよう
2.6 ストレージレイヤー データやメタデータを貯蔵する
- データレイク/DWH プロセスデータをメインとして管理する場所
- マスターデータ管理 マスターデータによってデータはもっと活きる
- データ活用型のマスターデータ管理 既存のシステムが大量にある場合はこの方式がお勧め
- データのライフサイクル管理 データの誕生から役目の終わりまで
- データのゾーン管理 データを管理するときの基本
- プレゼンテーションデータストア 外部アプリケーションとの連携を前提とした保存場所
- メタデータストア メタデータを管理/保存する場所
2.7 アクセスレイヤー データ分析基盤と外の世界との連携
- GUI Web画面の提供
- GUIを通したメタデータの参照/更新 みんなの強い味方
- GUIを通したデータ分析基盤へのオペレーションの提供
- BIツール(SQL)アクセス データアクセスの王道
- ストレージへの直接アクセス データの貯蔵庫へ直接アクセスをする
- [参考]Sparkにて,プロセシングレイヤーからストレージレイヤーのParquetファイルを読み込む
- ファイル連携 ファイルを介したデータの連携
- データエンリッチング データに付加価値をつける
- クロスアカウントによるアクセス アカウントを分けてアクセス
- API連携 データ分析基盤へのアクセスをラップする
- データ分析基盤をAPIを通して操作可能にする ジョブの実行から指標提供まで
- プレゼンテーションデータ向けのAPI活用 活用データを利用して改善サイクルを回そう
- メタデータアクセス 指標提供を行う
- 分散メッセージングシステム ストリーミングデータを一時保存するところ
2.8 セマンティックレイヤーとヘッドレスBI アクセスレイヤーを拡張して外部へのデータ提供をより効率的に行う
- セマンティックレイヤー アクセスレイヤーを拡張して指標を統一しよう
- データ利用における不確実性 同一目的に対するアプローチのばらつき
- セマンティックレイヤーの効果と配置パターン データの一貫性を確保するための最適なアプローチ
- ヘッドレスBI データ提供をより確実に簡単にするソリューション
2.9 本章のまとめ
第3章 データ分析基盤の管理&構築 セルフサービス,SSoT,タグ,ゾーン,メタデータ管理
3.1 セルフサービスの登場 全員参加時代への移行期
- データ利用の多様化 データに対する価値観が異なる人たち
- 従来のエンジニア中心のモデル Analytics as IT Service
- セルフサービスモデル Analytics as Self-Service
- セルフサービスモデルの特徴 ユーザーごとに適切なインターフェースを提供する
3.2 SSoT データは1ヵ所に集めよう
- データのサイロ化 とくに避けるべき事態
- フィジカルSSoT 実際にデータを1ヵ所に集める
- ロジカルSSoT 1ヵ所に集めたようにユーザーに見せる
3.3 データ管理デザインパターン ゾーンとタグ
- タグとゾーンを組み合わせる 管理の汎用性を向上させる
- タグを使った論理ゾーン化によるゾーンの管理 物理的ロケーションに囚われずに管理する
- タグによるデータ管理 物理ゾーン化の弱点を解消する
- GAパターン 一般公開は少し待ってから
- GAパターンにおけるデータの動き データは手続きを得て公開される
- プロビジョニングパターン お好きなときにお好きにどうぞ
- プロビジョニングパターンにおけるデータの動き ユーザー主体で分析可能
- プロビジョニングパターンとGAパターンの弱点 人のボトルネック
- システムによる自動チェック データのチェックは機械(システム)にまかせる
3.4 データの管理とバックアップ データ整理と,もしものときの準備
- テーブルによる管理 ビッグデータの世界でもテーブル
- ロケーション テーブル定義と物理データの分離に対応する
- パーティション ビッグデータでは必須。データの配置を分割する
- データのバックアップと復元 一番怖いのは「人」
- フルバックアップ すべてのデータをバックアップしておく
- 一部のデータをバックアップするパターン しくみやルールで解決
- 復元方法も考えておく いざ戻せないと意味がない
- バージョニング 効率的なバックアップ&復元手段
3.5 データのアクセス制御 ほど良いアクセス権限の適用
- データのアクセス権限 できる限りオープンな環境作り
- アクセス制御の種類 アクセス制御が必要になる背景にも注目
3.6 One Size Fits All問題 デカップリングで数々の問題を解決しよう
- デカップリングを前提に考える One Size Fits All問題への対応
- 障害時の影響の最小化 できる限り持続可能なシステムに
- 計算リソースの最適化 システムによって,元々の要件が異なる
- ストレージレイヤーとプロセシングレイヤーの分離 デカップリングの基本戦略
- コレクティングレイヤーやアクセスレイヤーの分離 ソフトウェアやミドルウェアのアップデートを簡単に
3.7 データのライフサイクル管理 不要なデータを残さないために
- データの発生 絶え間なく生まれるデータ
- データの成長 データのバトン
- データの最後 そして,生まれ変わる
- サマリー化 サマリーによるデータ圧縮
- コールドストレージへデータをアーカイブ 使用頻度の低いものは,アクセス速度の遅い場所に配置
- 不要なデータは削除する データマートやデータウェアハウスのデータ
3.8 メタデータとデータ品質による管理 データを知る基本ツール
- メタデータストアはどのように管理される データベースやマネージドツールなど
3.9 ハイブリット構成 柔軟に技術を選択しよう
- ハイブリット構成の大きなメリット 柔軟な機能実現と,データ統合コスト削減
- データバーチャライゼーション そもそも取り込まない(!?)
- ハイブリッドのデメリット 迷わせないことがデメリット解消の一歩
- ❶データの所在,オーナーが不明になりやすい
- ❷管理対象の増加によるコスト増大や障害復旧の複雑化
3.10 データ分析基盤とSLO/SLA データ分析基盤の説明書を作る
- SLO/SLAとは? システムのお約束
- データ分析基盤とSLO より目線を上げて規定する
- 可用性 どれだけ継続可能か
- データの取り扱い データはどのように管理されている?
- パフォーマンス/拡張性 どこまでの規模を想定する?
- セキュリティ 基本的な対策で思わぬ落とし穴を防ごう
- 技術/環境要件 データ分析基盤を構成する要素と動いている場所は?
3.11 本章のまとめ
第4章 データ分析基盤の技術スタック データソースからアクセスレイヤー,クラスター,ワークフローエンジンまで
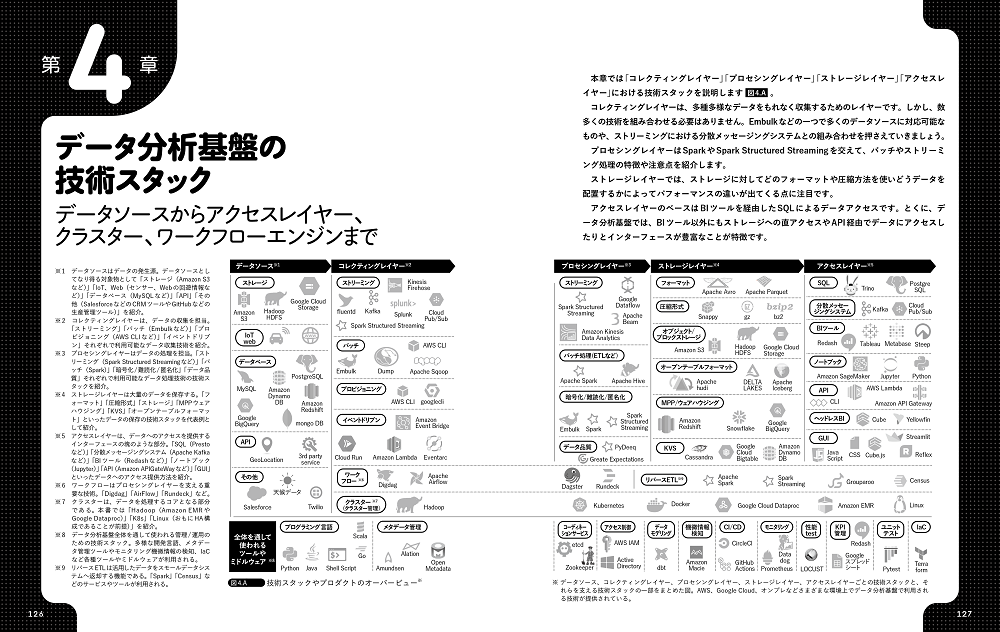
4.1 データ分析基盤の技術スタック 全体像を俯瞰する
- データ分析基盤のクラスター選択 データ分析基盤における計算能力の要
- クラスターの計算能力 インプットを処理してアウトプットするための能力
- コレクティングレイヤーの技術スタック 多種多様なデータを取り込む入り口
- プロセシングレイヤーの技術スタック 多種多様なデータを処理する場所
- ストレージレイヤーの技術スタック 多種多様なデータを格納する場所
- アクセスレイヤーの技術スタック 多種多様なアクセスを提供する場所
- 全体を通して利用する技術スタック 堅牢なデータ分析基盤運用を支えるツール
4.2 データ分析基盤のためのクラスター選択 無理な利用にも耐えられる必要がある
- Hadoop ビッグデータの黎明期,オンプレミスのHadoopの問題
- デカップリングの登場 クラウド環境のクラスター
- Hadoop on クラウド Hadoopのマネージドは今でも便利
- EMRとDataproc クラウド上で簡単に分散処理を実現する
- Kubernetes コンテナライズされた環境
- MPPDB ビッグデータシステムでも使えるスモールデータシステムの技術
- HA環境下のLinuxサーバー 切っても切り離せないLinuxサーバー
- SaaS型データプラットフォーム インフラの構築/管理の手間を省き別作業へシフトする
4.3 コレクティングレイヤーの技術スタック セルフサービス時代のデータの取り込み
- コレクティングレイヤーオーバービュー データソースによって技術を使い分けよう
- バッチ処理のデータ取り込み データの塊を一度に処理する
- Embulkを活用したデータ収集 プラグインが豊富な取り込みの王道
- CLIを活用したデータ収集 さまざまなコマンドを使いこなしてデータ収集しよう
- API経由でのデータ収集 制限や速度に注意しながら取り込み方法を工夫しよう
- ストリーミングのデータ取り込み 組み合わせの基本
- 分散メッセージングシステム Kafka pub/sub kinesissなど
- プロビジョニング データを簡単に素早く取り込む
- イベントドリブンにおけるデータ取り込み 応答性を確保して逐次処理する
4.4 プロセシングレイヤーの技術スタック データ変換を行うレイヤー
- バッチ処理のデータ変換 王道のデータ変換
- Apache Spark 最強のコンピューティングエンジンの登場
- Apache Hive
- ストリーミング処理のデータ変換 データを1行ずつ処理する
- ストリーミングETL データに付加価値をつける
- Spark Structured Streamingと分散メッセージングシステム ストリーミングにおける組み合わせの基本
- データ転送 データ分析基盤間,プロダクト間,クラウドベンダー間の連携
- データをバッチで転送する際に気をつけるポイント 正しく送られているか確認しよう
- プロダクトの連携時によく使われるファイルのバッチ転送方法 クラウドベンダーのコマンド
- クラウド間でよく使われる転送方法 オンプレミス,クラウド間で使われるツール
- ストリーミング処理における転送方法
- ストリーミングデータの送受信で気をつける点 データの重複,遅延,偏りに注意
- リバースETL データ分析基盤から外部システムへデータを連携する
4.5 ワークフローエンジン データ取り込みと変換を統括する
- データパイプラインとワークフローエンジン 次へつながるインプットに着目する
- 汎用型と特化型 大まかな分類
- データ分析基盤向けのワークフローエンジン選択 5つのポイント
- Digdag 汎用型ワークフローエンジン
- Apache Airflow Pythonで定義可能
- Rundeck GUIが直感的で使いやすい
4.6 ストレージレイヤーの技術スタック データの保存方法
- データレイクやDWHで扱う技術スタック データ保存の効率化と最適化
- ❶ストレージレイヤーが扱うフォーマット データウェアハウス,データマートで何を使うか
- ❷列指向フォーマットと行指向フォーマット パフォーマンスと用途の違い
- Parquet 多くのデータ分析基盤はこのフォーマットで事足りる
- Avro ストリーミングや,部門間にまたがり開発する際に有効
- ❸データ分析基盤が扱う圧縮形式 特性と選択基準に注目
- ❹その形式は「スプリッタブル」か 分散処理可能な組み合わせを選ぼう
- スプリッタブル 適度に分割したほうが処理しやすい
- 圧縮形式とフォーマットの組み合わせ スプリッタブルな組み合わせかどうかが重要
- ❺データストレージの種類 基本的なストレージから,データ分析基盤に特化したストレージまで
- オブジェクトストレージ データレイク/DWHにおけるデータ保存候補としての筆頭
- プロダクトストレージ オブジェクトストレージより早い処理が可能
- オンプレミスにおけるストレージ 安価になったSSD
- ❻データストレージへのデータ配置で気をつけたいポイント 偏りをできる限りなくそう
- 1ファイルの大きさ スモールファイルに注意
- データスキューネス データやファイルサイズの偏りに注意
- ❼オープンテーブルフォーマット 既存フォーマットを拡張するソフトウェア
4.7 プレゼンテーションデータを扱う技術スタック 効果的なデータ参照のための設計戦略
- データモデル設計 データ分析基盤では参照要件を気にしよう
- プレゼンテーションデータストアにおけるデータ保存 データ分析基盤から外部システムへデータを書き込む
4.8 アクセスレイヤー構築の技術スタック セルフサービス時代のユーザーへのデータ提供
- BIツールを提供する 万人とつながる可視化ツール
- 参照者が多い場合に利用するBIツール シンプルなダッシュボード向け
- 編集者が多い場合に利用するBIツール 大半のBIツールはこの部類
- SQLの提供 最強のデータ分析/活用技術
- Presto(Trino) BIツールを通して,よく実行されるSQLのタイプ❶
- PostgreSQL BIツールを通して,よく実行されるSQLのタイプ❷
- ノートブック 多様なデータアクセスを提供するインターフェース
- Jupyter Notebook オープンソースの対話型ツール
- APIを提供する データ分析基盤へのインターフェースとして活躍
4.9 セマンティックレイヤー 統一的なデータを提供しよう
- セマンティックレイヤーとは何か アクセスレイヤーを拡張する
- BIツールと連携したセマンティックレイヤー セマンティックレイヤーの意義を実例を使って理解しよう
- ヘッドレスBIの活用 データ提供をより確実に簡単に実現する
4.10 アクセス制御 アクセスレイヤーに対するアクセス制御
- ユーザーの認証と制御の歴史 大きなデータ(大量のファイル)を持つデータ分析基盤特有の悩み
- chmod/chown ジェネラルアクセスパーミッション
- IAM ロールベースパーミッション
- タグ(属性)による管理
4.11 コーディネーションサービス 分散システムを支える影の立役者
- コーディネーションサービスとは何か ノード間の同期を円滑にする要
- コーディネーションサービスの役割 システムの安定性を支えるしくみ
- アンサンブル構成 コーディネーションサービスも冗長化する
4.12 本章のまとめ
第5章 メタデータ管理 データを管理する「データ」の重要性
5.1 データより深いメタデータの世界 データは氷山の一角
- メタデータとは何者なのか データを表すデータ
- なぜメタデータを提供する必要があるのか データを見つけるためにデータを検索するのは非効率
- ❶疑問点の解消につながる 解答の糸口を持っている
- ❷データに対するドメイン知識のギャップを緩和できる 暗黙のルールは言語化しにくく,またできる人が限られている
- ❸データを利用するシステムや人の動きを統一する 指標を用いて統一感を出す
- ❹非同期にデータを利用する状況を作る 生産性向上に寄与
- ❺アクセス権限に縛られずデータを見つけるヒントになる データを見つけられないジレンマ
5.2 メタデータとデータ 3つのメタデータを整理/整備しよう
- データより深いメタデータ データ理解へのインターフェースとなる
- ビジネスメタデータ テーブルやデータベースの意味を表すメタデータ
- データプロファイリング データの形はどのような形か
- テクニカルメタデータ 技術的な内容を表すメタデータ
- テーブルの抽出条件 実はオリジナルデータと違うかもしれない
- リネージュとプロバナンス テーブルのデータはどこから取得しているか
- テーブルのフォーマットタイプ フォーマットの違いがもたらす課題に注目
- テーブルのロケーション テーブルが参照しているデータはどこにあるか
- ETLの完了時間 処理は終わっているか
- テーブルの生成予定時間 次はいつ実行されるか
- データの最終更新日時 データの鮮度を確認する
- オペレーショナルメタデータ データの5w1hを表すメタデータ
- テーブルステータス そのテーブルは使えるか,使えないか
- メタデータの更新日時 ドキュメントはいつ更新したか
- 1ファイルのデータのサイズ スモールファイルは常に気をつける
- 更新頻度 データ更新の誤解を防ぐ
- 誰がアクセスしているか オペレーショナルメタデータにおける5W1H
5.3 データプロファイリング データの状態を知る
- データプロファイリングの基礎 データの特性からデータそのものを推論
- データプロファイリング結果の表現方法 大別すると2パターン
- データプロファイリングをどのレベル(単位)で表現するか カラムレベルからデータベースレベルまで
- カーディナリティ どれくらい値はばらけている?
- セレクティビティ ユニークさを表現する。1なら,そのカラムはユニークである
- デンシティNull NullもしくはNullに匹敵するものの密度
- コンシステンシー 一貫性があるか?
- リファレンシャルインテグレティ(参照整合性) データにはお互いに結合(SQLなどでJOIN)できるのか
- コンプリートネス 値はNullではないか
- データ型 年齢は数字か
- レンジ 特定の範囲内か?
- フォーマット 郵便番号は7桁かなど
- フォーマットフリークエンシー(形式出現頻度) フォーマットのパターンはどれくらいある?
- その他の基本的なプロファイリング項目 年齢は数字か
- データリダンダンシー データが何ヵ所に存在しているか
- バリディティレベル 有効か否か
- フリークエンシーアクセス どれだけアクセスされているか?
5.4 データカタログ 手元にないメタデータはカタログ化しよう
- データカタログとは カタログを見て注文する
- データカタログの必要性 データには3種類の認知が存在する
- データカタログはECサイト データを取り寄せる
5.5 データアーキテクチャ メタデータの総合力としてのリネージュとプロバナンス
- データアーキテクチャ データフローの設計書
- リネージュ テーブルの紐付きを表す
- ❶データ生成の方法が記載されているので,利用している技術スタックの見通しが良くなる 改善のヒントになる場合も
- ❷障害時のトラッキングが行いやすくなる もしもの事態に備えよう
- ❸オーナーの明確化が可能 いざという時の問い合わせ先
- ❹データの設計書を残せる データ分析基盤ユーザーのための設計書
- ❺プロバナンスやメタデータと統合する データのルーツをめぐる
- プロバナンス データのDNAを表す
- データモデル 表現の粒度
5.6 本章のまとめ
第6章 データマート&データウェアハウスとデータ整備 DIKWモデル,データ設計,スキーマ設計,最小限のルール
6.1 データを整備するためのモデル DIKWモデル
- DIKWモデル データの整備されていくステージを示す
- Data 断片的なデータ
- Information(情報) 分類されたデータ
- Knowledge(知識) データからパターンと関係を見つける
- Wisdom(知恵) ルールから新たなひらめきを産む
6.2 データマートの役割 「Data」を整備して知恵の創出をサポートする
- データマートとは何か 「Data」を「Information」にすること
- KnowledgeやWisdomのない世界 知識と知恵を生み出すための土台がない
- データマートとデータウェアハウスの違い データを掛け合わせて新価値を作る
- 中間テーブルとデータマートの違い 中間テーブルで十分な場合が多い
- データマートを生み出す苦しみ 使ってもらうのは大変です
6.3 スキーマ設計 データに関するルールを設計する
- スキーマ設計の考え方 スキーマ設計によりデータの利活用効率を上げよう
- スタースキーマ オーソドックスなスキーマ設計の一つ
- 非正規化 データ分析基盤特有のテーブル設計
- データ分析基盤でJOINはコストの高い操作
6.4 データマートの生成サポート コミュニケーションの省略&活用
- データ分析基盤ができるサポート データマートを代わりに作ることではない
- コミュニケーションの不要な中間テーブルの生成方法 粛々と中間テーブルを作成する
- アクセスログとExplainを使って機械的に生成する アクセスの分析結果を活用する
- アクセスログを利用した方法のさらなるメリット
- コミュニケーションの必要な中間テーブルの生成方法 ビジネスに直結したクエリーしやすいテーブルを作成する
- Viewによる中間テーブルの作成 手軽にクエリーしやすくする
- 履歴テーブルを作ろう 過去に遡る分析に備えよう
- オープンテーブルフォーマットを利用しない場合(データレイクそのままの場合)
- オープンテーブルフォーマットを用いた場合
6.5 データマートのプロパゲーション メタデータやルールの作成
- データマートを自由に作成してもらうために 作りっぱなしを防ぐ
- アクセス頻度を確認 要不要はアクセスログが知っている
- データマート生成停止の条件を定める 作った後もしっかりとメンテナンスをする
- アクセス数が減ってきたときの対応策 データマートは時間の経過とともに劣化する
- 環境整備におけるメタデータの役割 情報伝搬のツールとして使う
- オペレーショナルメタデータ 活用例❶
- ビジネスメタデータとしてデータマートのテーブル定義を管理 活用例❷
6.6 ストリーミングとデータマート 瞬時にKnowledge化する
- ストリーミング処理におけるデータマート作成 バッチとは処理単位が違うだけ
- ストリーミングにおけるデータマート作成の流れ Avroフォーマットの活用
- Avroフォーマットとデータマート作成
- 分散メッセージングシステムの連鎖 Aの出力はBへの入力
6.7 本章のまとめ
第7章 データ品質管理 質の高いデータを提供する
7.1 データ品質管理の基礎 データ蓄積から次の段階へ進む
- 本書で扱うデータ品質管理について
- データ品質管理の三原則 事前に防ぐ。見つける。修正する
- 三原則の適切な割合 どれかに偏り過ぎるのはNG
- データ品質について データの状態を継続的に可視化し改善を示唆する
- データ分析基盤におけるデータ品質担保の難しさ ステークホルダーがあちらこちらにも
- データ品質を測定する 6つの要素
- データ品質の指標とデータの見方
- データ品質 システム観点での重要性+コスト削減効果も
- 分析観点での「データ品質」の重要性 分析のための煩雑な作業を緩和する
- 不確実性観点での「データ品質」の重要性 揺らぎを排除できるか?
- 生産性観点での「データ品質」の重要性 「ちょっと違う」に要注意!
7.2 データの劣化 データは放置するだけで劣化する
- データの劣化の原因 データの移動時と時間の経過に注意
- データの往来 データ分析基盤に到着する前にも劣化する
- データの変換 システムの守備範囲,データマートの作成
- 時間の経過 10年前のデータは正しいデータか
- 人的要因 人にはミスがある
- さまざまな劣化に早く気づき修正する
7.3 データ品質テスト 劣化に気づくための品質チェック
- データ品質テスト実施の流れ
- レベル 品質テストを行う粒度の設定
- カラムレベルで行うことができるテスト データの単体テスト
- 正確性のテスト 基本的なデータ品質の項目
- ユニーク性と有効性のテスト 社内の常識の範囲
- 一貫性のテスト 一貫性は取れているか
- 適時性のテスト 必要なときに正しいデータが存在しているか
- 完全性のテスト データはしっかりと情報を持っているか
- テーブル間で行うことができる一貫性のテスト データを整えるために必要なテスト
- ナチュラルキーの特定を行う トランザクションIDなど
- エクスターナルコンシステンシー 外部と一貫性をテストする
- テーブル単位で行うことができるテスト シンプルなテストでも効果絶大
- その他のテスト データの基本的な特徴を表す
- 単体テストとデータ品質のテストは違う(?!) 2つのテストで相乗効果を狙おう
7.4 メタデータ品質 生産性を向上させるために
- メタデータの名寄せ テーブルの名称やカラムは統一されているか
- 言語の認識合わせ あなたの第一クォーターは,あの人の第一クォーターか
7.5 データ品質を向上させる 品質テストの結果を活かす
- データのリペア データ不備を修正する/未然に防ぐ
- データ品質管理におけるプリベンションにつなげる リペア方法❶
- すでにストレージレイヤーに存在するデータの不備を見つけて修正する リペア方法❷
- ユーザーからのデータ修正依頼 リペア方法❸
- インサイドアウトとアウトサイドイン 内から,外からデータを修正する
- チェックし過ぎに注意 80%を善しとする
- メタデータと連携したデータ品質の表現方法
- データの品質を事実で表現する
- データの品質を数値で表現する
7.6 本章のまとめ
第8章 データ分析基盤から始まるデータドリブン データ分析基盤の可視化&測定
8.1 データ分析基盤とデータドリブン エンジニアもデータドリブンに行こう
- データドリブンと狭義のデータドリブン データのみを元に行動を起こす
- 広義のデータドリブン メタデータとデータ,両方用いて行動する
8.2 データドリブンを実現するための準備 データ分析基盤のPDCAと数値
- データドリブンのためのPDCA
- KGI/(CSF)/KPIを定義して課題設定する まずは目標設定から
- データ分析基盤におけるKGI/(CSF)/KPIの設定
- 測定用のツールで改善前後の数値を測定 事前の数値取得は忘れずに
- BIツールでの可視化 ベーシックな可視化手法
- 監視ツールでの可視化 便利なツールはいっぱいあります
- 他ツールでの可視化 見やすくすることを意識しよう
- アクションを決める 簡単にできて効果の高いものを選ぶ
- アクションの実施 複数チームや組織における実行
- SLO システムが交わすユーザーに対して守るべきKPI
- コレクティングレイヤーにおけるSLO
- プロセシングレイヤーにおけるSLO
- ストレージレイヤーにおけるSLO
- アクセスレイヤーにおけるSLO
8.3 KPIをどのように開発に活かすのか データ分析基盤の「コスト削減KGI」の例
- PDCAを高速に回す Planに時間をかけ過ぎない
- コスト削減KGI 間接部門のわかりやすい成果指標
- データ分析基盤のためのPDCAの例
- コスト削減KGIの設定 コストは安いほうが良い
- コスト削減CSFの設定 どのような課題があるか
- コスト削減KPIの設定 重要な指標を選択する
- KPI改善のためのアクション設定 意外とある簡単でも効果の高いもの
- アクションから得る学び 成功や失敗を次に活かそう
8.4 データ分析基盤観点のKGI/(CSF)/KPI 改善の着眼点
- クエリーのしやすさKGI SQLの実行しやすさ
- JOINの数 一体いくつのテーブルが結合されているのか
- クエリーの実行時間 クエリーが遅過ぎる
- データスキャン量 どれくらいのデータがスキャンされているか
- フリクションKGI データを利用するまでにかかる時間
- データパイプラインの処理時間 データを早く届ける
- 調整コスト より合理的に無駄を省く
- データマネジメントKGI データをしっかりと守っています
- データリダンダンシー データの冗長性はどれくらいある?
- データ品質 データの「良さ」を定量的に表現する
- データエンゲージメントKGI データ利用はどれくらい広がっている?
- 配置率 センサーやJavaScriptファイルなど
- 参画人数 メタデータのエンゲージメントはどのくらいか
- SQLの発行数 全体で発行されているSQLの数
- 発行ジョブ数 データ分析基盤の成長指標
- 参画人数 アクセスログを使う
- さまざまな数値がKPIになり得る 数値管理との違い
8.5 本章のまとめ
第9章 [事例で考える]データ分析基盤のアーキテクチャ設計 豊富な知識と柔軟な思考で最適解を目指そう
9.1 テーマとゴールを考えてみよう 基本的な要件で思考の順番を掴もう
- テーマとゴール 基本的な要件でアーキテクチャのイメージを掴もう
- 技術的な前提条件の整理 基本的な要件でアーキテクチャのイメージを掴もう
9.2 データ分析基盤の骨格を考えよう まずは大きなデータの流れについて考慮しよう
- データのアウトプットを起点に考えよう 目的のないデータ分析基盤の構築はやめよう
- インプットとアウトプットを見比べて全体のロジックをつなげる データソースとインプットは整合性が取れているだろうか
- アウトプットとインプットデータの整合性確認
- どのようなBIツールを利用するか
- 為替の考慮
- どのようにデータを収集するか 技術的に達成可能か
- データ取得および処理は時間内に終わるか
- APIトークンはどのように扱うか
- スケジューラーやワークフローの有無
- どのようなストレージが最適か,どのように保存するか
- データの保存先をどこにするか
- メタデータストア
- データのゾーン管理
- ゴールドゾーンへ作成するテーブルのパーティションはどうするか
- 保存フォーマットをどうする?
- データ処理をどのように行うか 目的に向けてどのようなデータ変換を実施するか
- メタデータ テーブルの定義はどのようにするか
- [補足]設定のポイント整理&リファレンス
- データパイプラインはどのようになったか
9.3 データ分析基盤構築における不確実性に備えよう ソフトスキルも大事にしよう
- パズル台紙にはめられない場合はどうする? ソフトスキルやソフトウェアエンジニアリングが必要な場面も
- 制約もアーキテクチャの考慮に入れよう 一つ違うだけで大局が変わることもある
9.4 データ分析基盤に必要な機能を揃えよう 非機能についても目を向けよう
- データ品質実行アプリを付け足す データを常に監視しよう
- アーキテクチャにメタデータの管理の考慮を入れてみよう データを多くの人に知ってもらおう
9.5 本章のまとめ
Appendix [ビッグデータでも役立つ]RDB基礎講座
A.1 データベースとは何か? 検索,更新,制約機能を持った入れ物
- データベースの機能と形態
- Excelデータベースの限界 データベースの基本機能を満たせるか
- RDBの誕生 データベースと言えばコレ
A.2 RDBの基本 データベースの基本を振り返る
- RDB 現実世界を表す表形式のデータ集合体
- テーブル テーブルを定義するのは3つの要素
- 行(レコード) 横方向のデータ塊
- 列(カラム) 縦方向のデータの塊
- スキーマ 行と列に制約を課す
- 型情報 データの特性を決める
- 主キーと外部キー RDBにおける大事な制約
- SQL データを操作する最も汎用的な技術
- SELECT(検索) 目的のデータを見つける
- INSERT/UPDATE/DELETE(登録,更新,削除) 対象のデータを更新する
- CREATE TABLE テーブルを作成する
- CREATE View 別名を付ける
- トランザクション 同時実行性を解決する
- インデックス 検索性能を向上させる
- 代表的なRDB 概念理解が大事
- クエリーエンジン SQLを動かすソフトウェアやミドルウェア
A.3 RDBにおけるアーキテクチャ RDBの設計
- アーキテクチャとは何か 構成を考える
- データアーキテクトとデータアーキテクチャ データの保持方法と表現方法
- 正規化と正規型 データの保存方法の整理
- 非正規型 横方向にカラムが増えていく
- 第1正規化 横方向のカラム整理
- 第2正規化 主キー属性における従属関係の分離
- 第3正規化 非キー属性における従属関係の分離
- 正規化のメリットとデメリット 手順に囚われすぎないようにしよう
- ER図 データやテーブルの表現方法