


目次
- はじめに
- 読んでいただく際の留意事項
- 謝辞
- 目次
第1章:PostgreSQLの概要
リレーショナルデータベースとは
- データベースとは
- データモデル
リレーショナルデータベースの役割
- トランザクション管理
- 原子性(Atomicity)
- 一貫性(Consistency)
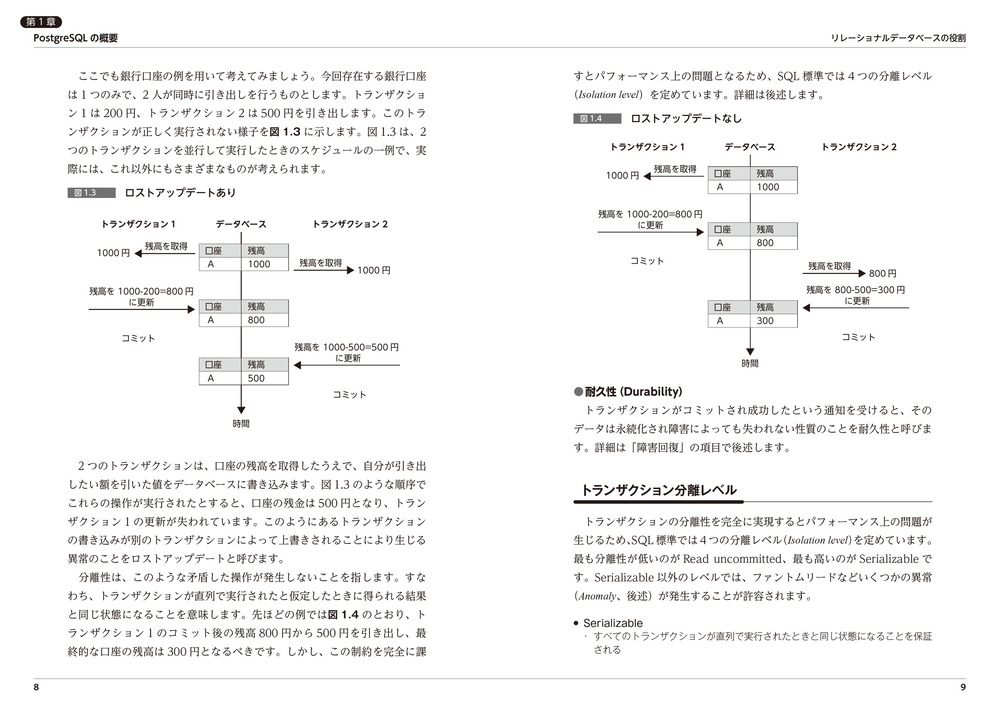
- 分離性(Isolation)
- 耐久性(Durability)
- トランザクション分離レベル
- トランザクション分離レベルにより発生する異常
- ダーティーリード
- ノンリピータブルリード
- ファントムリード
- まとめ
- 障害回復──チェックポイントとWAL
- SQLの解釈・実行
PostgreSQLとは
- PostgreSQLの歴史
- PostgreSQL開発コミュニティ
- リリーススケジュール
- 開発リポジトリ
- メジャーバージョンごとの新機能
PostgreSQLのアーキテクチャ概要
- プロセス構成
- ファイル,ディレクトリ構成
- ディレクトリ
- ファイル
- システムカタログ──PostgreSQLの管理情報
- トランザクション──データの一貫性を保つ
- レプリケーション──データベースを複製する
- データベースの可用性(耐障害性)を上げる
- 負荷分散で性能を上げる
- クエリ最適化
- 拡張機能
第2章:インストール
Rocky Linuxへのインストール
- OSのインストールと初期設定
- PostgreSQL開発コミュニティ提供のRPMリポジトリ
- RPMリポジトリの設定
- Rocky LinuxのAppStreamに含まれるPostgreSQLモジュールの無効化
- PostgreSQLのインストール
- データベースクラスタの作成
- 自動起動の設定
- [column]データベースクラスタのディレクトリを変更する
- PostgreSQLサーバの起動・停止
- アンインストール
- 【参考】Rocky Linuxのモジュールを用いたPostgreSQLのインストール
ソースコードからビルドしてインストール
- 必要なツールのインストール
- ソースコードの取得
- ビルドとインストール
- スーパーユーザーの作成
- PostgreSQLサーバの起動・停止
- 環境変数の設定
- アンインストール
Windowsへのインストール
- インストーラのダウンロード
- PostgreSQLのインストール
- Application Stack Builderによるアプリケーションのインストール
- 環境変数の設定
- アンインストール
第3章:PostgreSQLの起動・停止と設定パラメータ
initdb──データベースクラスタの初期化
- initdbコマンドの実行
- 自動設定の内容
PostgreSQLの起動・停止
- postgresコマンドの直接起動
- pg_ctlコマンドを用いた起動
- pg_ctlコマンドを用いた停止
- サービスとしての起動
サーバ設定
- postgresql.conf設定ファイル
設定パラメータ
- GUCコンテクスト
- 設定パラメータがどの状況で変更可能かを確認する方法
- 設定ソース
設定方法
- (a)サーバ起動時に読み込まれる設定
- 1. pg_ctl(postgres)コマンドラインオプション(ソース名:command line)
- 2. SQLコマンドALTER SYSTEM SET(ソース名:configuration file)
- 3. postgresql.conf(ソース名:configuration file)
- 4. 環境変数(ソース名:environment variable)
- (b)設定リロード時に読み込まれる設定
- (c)セッション開始時に行われる設定変更
- 1. 接続オプションによるセッション単位の設定変更
- 2. ALTER ROLE (IN DATABASE) SET,ALTER DATABASE SETによるセッション単位の設定変更
- (d)セッション内で行う設定変更
- SETコマンドによる変更
- 関数実行時の変更
設定の確認および変更
- 設定の確認方法
- SHOWコマンド── 現在の設定値を確認する
- pg_settingsビュー── 設定項目の現時点における詳細情報を表示する
- pg_file_settingsビュー── 設定ファイル内の情報を表示する
- pg_hba_file_rulesビュー──pg_hba.confファイル内の情報を表示する
- 起動時およびリロード時に読み込まれる設定の変更
- (a)設定ファイルを直接編集する方法
- (b)コマンドを使って設定ファイルを変更する方法
- 設定ファイルの再読み込み(サーバリロード)
第4章:SQL入門
PostgreSQLのデータベースクラスタ構造
SQL構文の記法
データベースの作成・変更・削除
- 構文
- データベースの作成
- データベースの変更
- データベースの削除
- パラメータ
- 使用例
スキーマの操作
- 構文
- スキーマの作成
- スキーマの変更
- スキーマの削除
- パラメータ
- 使用例
テーブルの操作
- 構文
- テーブルの作成
- テーブルの変更
- テーブルの削除
- パラメータ
- 使用例
インデックスの操作
- 構文
- インデックスの作成
- インデックスの変更
- インデックスの削除
- パラメータ
- 使用例
テーブルスペースの操作
- 構文
- テーブルスペースの作成
- テーブルスペースの変更
- テーブルスペースの削除
- パラメータ
- 使用例
シーケンスの操作
- 構文
- シーケンスの作成
- シーケンスの変更
- シーケンスの削除
- パラメータ
- シーケンス操作関数
- 使用例
データの挿入(INSERT)
- 構文
- パラメータ
- 使用例
データの変更(UPDATE)
- 構文
- パラメータ
- 使用例
データの削除(DELETE)
- 構文
- パラメータ
- 使用例
データの参照
- 構文
- パラメータ
- DISTINCT句
- SELECTリスト
- FROM句
- WHERE句
- GROUP BY句
- HAVING句
- ORDER BY句
- LIMIT句
- OFFSET句
- FOR UPDATE句
- 使用例
ビューの操作
- 構文
- ビューの作成
- ビューの変更
- ビューの削除
- パラメータ
- 使用例
トランザクション
- 構文
- トランザクションの開始(BEGIN)
- トランザクションの完了(COMMIT)
- トランザクションの中断(ROLLBACK)
- セーブポイント(SAVEPOINT)
- ロック(LOCK TABLE)
- パラメータ
- ISOLATION LEVEL
- transaction_mode
- SAVEPOINT
- TABLE LOCK
- 使用例
データコピー(COPY)
- 構文
- パラメータ
- 使用例
テーブルデータを全削除(TRUNCATE)
- 構文
- パラメータ
- 使用例
第5章:テーブル設計
データ型
- 数値データ型(int型,real型,numeric型,serial型など)
- 整数
- 浮動小数
- 任意精度型
- シーケンスと連番型
- 文字型(char型,varchar型,text型など)
- 日付/時刻データ型(timestamp型,date型,interval型など)
- 列挙型(enum型)
- バイナリ列データ型(bytea型)
- JSON型(json型,jsonb型)
- 配列型
- 範囲型
制約──格納するデータを限定する
- 主キー制約──主キーであることを指定する
- CHECK制約──特定の条件を満たすデータのみであることを指定する
- 一意性制約──データが一意であることを指定する
- 非NULL制約──列がNULLにならないことを指定する
- 外部キー制約──ほかのテーブルに存在する行の値に限定する
- 排他制約──データの重なりがないことを指定する
インデックス──クエリ処理の高速化
- B-treeインデックス
- B-treeインデックスの構造
- B-treeインデックスの作成と高速化の確認
- 重複排除
- Hashインデックス
- Hashインデックスの構造
- Hashインデックスの作成と高速化の確認
- GiSTインデックス
- GiSTインデックスを用いたR-treeの構造
- GiSTインデックスの作成と高速化の確認
- SP-GiSTインデックス
- SP-GiSTインデックスを用いたQuad-treeの構造
- GINインデックス
- GINインデックスを用いた全文検索
- BRINインデックス
- BRINインデックスの作成と高速化の確認
- その他の高度なインデックス
- 複数列インデックス
- 一意インデックス
- 式に対するインデックス
- 部分インデックス
- インデックス設計の注意点
テーブルパーティショニング
- テーブルパーティショニングとは
- テーブルパーティショニングの特徴
- パーティションプルーニング──子テーブルのスキャン省略
- レンジパーティショニング──連続する値でパーティションを分割
- リストパーティショニング──値を複数指定してパーティションを分割
- ハッシュパーティショニング──列のハッシュ値をもとにパーティションを分割
第6章:高度なSQL機能
関数・プロシージャ・演算子
- PostgreSQLにおける関数・プロシージャ・演算子の管理の概要
- 関数とプロシージャの定義・変更・削除
- 演算子の定義・変更・削除
- インデックスアクセスの際の演算子に関する処理の流れ
- 演算子を普通に使う場合とインデックスアクセスで使う場合の違い
- 演算子クラスを指定したインデックス作成
- インデックス検索の事前処理の例
- PL/pgSQL
- PL/Perl
- インストール
- 関数の定義・変更・削除
- trusted / untrusted
- C言語による関数の定義
- 必要な環境
- 定義の手順
- 関数の属性
- IMMUTABLE/STABLE/VOLATILE属性
- LEAKPROOF属性
トリガ
- トリガの概要
- トリガの使用の流れ
- トリガ関数の作成
- トリガの作成
- トリガ関数およびトリガの変更
- トリガ関数およびトリガの削除
グルーピングセットウィンドウ関数──データの集計を効率的に行う
- グルーピングセット(GROUPING SETS,ROLLUP,CUBE)
- ウィンドウ関数
ウィンドウ関数の詳細
- ウィンドウが持つ要素
- フレーム定義
- フレームモードの種類
- ウィンドウ関数の利用例
- 階層別集計
- 移動平均
- 汎用ウィンドウ関数
- ユーザー定義集約関数をウィンドウ関数として利用する
全文検索
- tsvector
- tsquery
- tsvector,tsqueryを使った自然言語演算
- 全文検索インデックス
- その他全文検索の補助機能
- pg_trgmとの違い
- pg_bigmのインストール
- pg_bigmによるバイグラム(2つの文字の組)への変換
- 全文検索インデックスの作成
- pg_bigmで使用する関数や演算子
第7章:クエリ処理
クエリ処理の基礎
- どのようにクエリを処理するか
- クエリ処理の流れ
- パーサ──SQLからパースツリーを作る
- アナライザ──パースツリーからクエリツリーを作る
- リライタ──クエリツリーを書き換える
- プランナ/オプティマイザ──クエリツリーからプランツリーを作る
- エクゼキュータ──クエリを実行する
- 本章内の実行例で使用するテーブルやデータ
- テーブル作成
- データ投入
テーブル統計情報──実行計画を作るための情報
- テーブル統計情報の参照──pg_statsビュー
- テーブル統計情報の更新に関する留意点
実行計画
- 実行計画の取得
- 実行計画の読み方
- 複雑な実行計画
- スキャン方法の種類と特徴
- シーケンシャルスキャン
- インデックススキャン
- ビットマップスキャン
- インデックスオンリースキャン
- Tidスキャン
- 結合方法の種類と特徴
- ネステッドループ結合
- マージ結合
- ハッシュ結合
- その他のプランノード
- [column]プランニングを強制的に変更する
クエリ処理の高速化
- パラレルクエリ──複数CPUを使ってクエリを並列に実行する
- JITコンパイル──クエリ実行時にコンパイルを行う
- [column]パラレルクエリに関係するパラメータ
- [column]JITコンパイルに関係するパラメータ
第8章:レプリケーション
レプリケーション──データベースの多重化
- レプリケーションの概要
- データの信頼性制御と処理性能
- 非同期レプリケーションと同期レプリケーション
- トランザクション単位での信頼性制御
転送データ形式の違いによるレプリケーションの種類と特徴
- ストリーミングレプリケーションの概要と特徴
- ストリーミングレプリケーションのしくみ
- ストリーミングレプリケーションの基本的な処理の流れ
- PostgreSQLにおける同期レプリケーションの動作の詳細
- 同期レプリケーションにおけるスタンバイのステータス確認方法の詳細
- 複数台のスタンバイの同期レプリケーション設定(synchronous_standby_names)
- ホットスタンバイ構成におけるスタンバイ上での処理の衝突
- ロジカルレプリケーションの概要と特徴
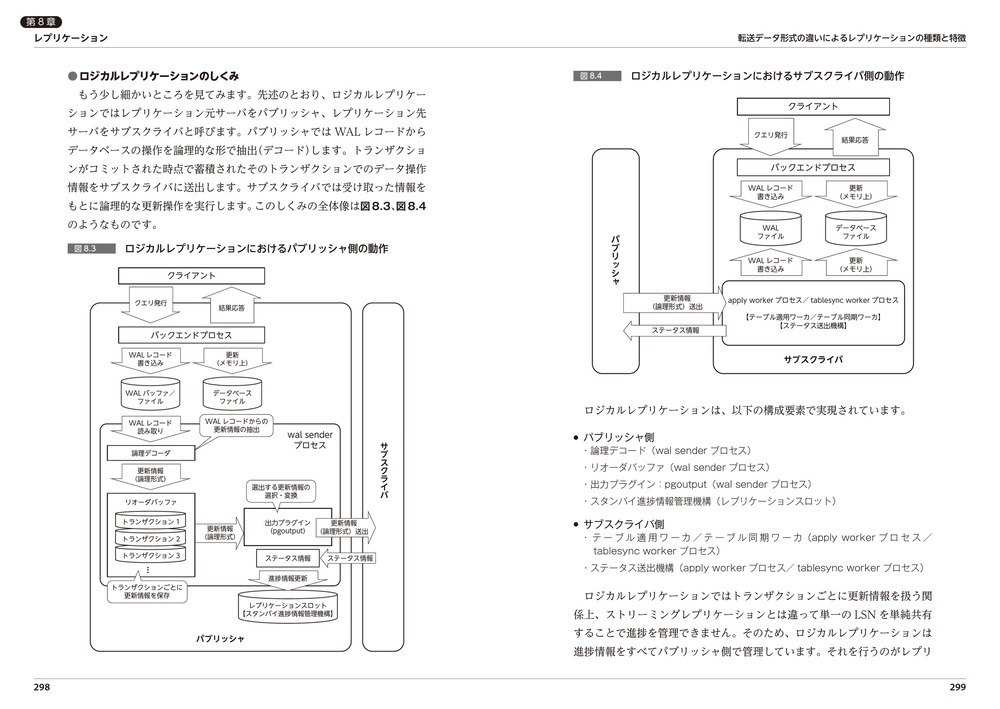
- ロジカルレプリケーションのしくみ
- ロジカルレプリケーションの基本的な処理の流れ
- ロジカルレプリケーションにおける同期レプリケーション
ストリーミングレプリケーションの構成・運用例
- プライマリの構築・設定
- pg_hba.conf
- postgresql.conf
- スタンバイの構築・設定
- postgresql.conf
- ストリーミングレプリケーション構成の管理・メンテナンス
- 監視
- 遅延の測定
- 競合の監視と解消
- 障害発生時のプライマリ・スタンバイ切り替え
- スタンバイのプライマリへの昇格
- 旧プライマリの再組込み
- よくある問題と対策
- プライマリサーバで不要領域が回収されない
- レプリケーションに必要なWALファイルが削除された
- プライマリ切り替え後,スタンバイのWALファイルが削除されない
ロジカルレプリケーションの構成・運用例
- ロジカルレプリケーションを使ったテーブル単位レプリケーション
- データを送信するサーバ(パブリッシャ)の構築・設定
- データを受信するサーバ(サブスクライバ)の構築・設定
- PUBLICATION,SUBSCRIPTIONの作成
- テーブルデータの初期同期
- ロジカルレプリケーションの開始・停止
- ロジカルレプリケーションの運用・監視
- PUBLICATIONの情報
- レプリケーションスロットの情報
- SUBSCRIPTIONの情報
- レプリケーションの監視
- ロジカルレプリケーションの性能に関するチューニング
- レプリケーション対象テーブルの追加
- テーブルの再同期
- サブスクライバでの競合の解消
- よくある問題と対策
- 同時実行したCREATE SUBSCRIPTIONが完了しない
- テーブルの同期処理でエラーが発生する
- レプリケーションの同期遅延が大きい
第9章:外部データラッパを使ってデータベースどうしをつなげる
外部データラッパの概要
- 外部データラッパとは
- 外部データラッパのしくみ
- 外部データラッパの使い方
例1:リモートのPostgreSQLとの連携
- ⓿準備
- リモートホスト(PGFDW-REMOTE)側の準備
- ローカルホスト(PGFDW-LOCAL)側の準備
- ❶PostgreSQL用の外部データラッパであるpostgres_fdwをインストールする
- ❷外部サーバを作成する
- ❸ユーザーマッピングを作成する
- ❹外部テーブルを作成する
- CREATE FOREIGN TABLEによる外部テーブルの作成
- IMPORT FOREIGN SCHEMAによる外部テーブルの作成
例2:CSVファイルとの連携
- ⓿準備
- ❶ファイル用の外部データラッパであるfile_fdwをインストールする
- ❷外部サーバを作成する
- ❸ユーザーマッピングを作成する
- ❹外部テーブルを作成する
例3:Oracleとの連携
- ⓿準備
- リモートホスト(ORACLE-REMOTE)側の準備
- ローカルホスト(ORAFDW-LOCAL)側の準備
- ❶Oracle Database用の外部データラッパであるoracle_fdwをインストールする
- ❷外部サーバを作成する
- ❸ユーザーマッピングを作成する
- ❹外部テーブルを作成する
- 外部テーブルを更新する際の注意事項
- oracle_fdwの便利な機能
- 困ったときには?
- その他の注意事項
例4:MySQLとの連携
- ⓿準備
- リモートホスト(MYSQL-REMOTE)側の準備
- ローカルホスト(MYSQLFDW-LOCAL)側の準備
- ❶MySQL用の外部データラッパであるmysql_fdwをインストールする
- ❷外部サーバを作成する
- ❸ユーザーマッピングを作成する
- ❹外部テーブルを作成する
- 外部テーブルを更新する際の注意事項
外部サーバでの効率的なクエリ実行
- postgres_fdwのプッシュダウン
- oracle_fdwのプッシュダウン
- mysql_fdwのプッシュダウン
- プッシュダウンの実行例
- WHERE句のプッシュダウン
- ORDER BYによるソート処理のプッシュダウン
- ソート処理に伴うLIMITのプッシュダウン
- 集約関数のプッシュダウン
- SELECT時の結合処理のプッシュダウン
- UPDATE,DELETE時の結合処理のプッシュダウン
外部データラッパの活用例
- 複数データベースにまたがる検索
- テーブルパーティショニングを併用したデータベースシャーディング機能の利用
- シャーディング構成の構築
- 更新処理の負荷分散
- 外部テーブルの参照処理の並列実行
- パーティションワイズ結合
- [column]今後のシャーディング開発動向
第10章:PostgreSQLにおけるユーザーと権限の管理
ロール
- ロールの作成・削除・オプション変更
- ロール属性の確認
- ロール間のメンバーシップの設定と確認
- 事前定義(Predefined)ロール
- ❶ pg_read_all_data
- ❷ pg_write_all_data
- ❸ pg_read_all_settings
- ❹ pg_read_all_stats
- ❺ pg_stat_scan_tables
- ❻ pg_monitor
- ❼ pg_database_owner
- ❽ pg_signal_backend
- ❾ pg_read_server_files
- ❿pg_write_server_files
- ⓫pg_execute_server_program
- ⓬pg_checkpoint
- ⓭pg_maintain
- ⓮pg_use_reserved_connections
- ⓯pg_create_subscription
権限
- ACLの格納先
- ACLの書式フォーマット
- データベースオブジェクト別の権限管理
- カラムの権限に関する注意点
- ビューの権限に関する注意点
- 関数の権限に対する注意点
行レベルセキュリティ
- 行レベルセキュリティ機能の概要
- パラメータrow_securityの設定
- 行レベルセキュリティの有効化
- ポリシー定義
- 行レベルセキュリティの設定例
- 作成したポリシーの確認
- より高度な行レベルセキュリティのポリシーを設定する方法
- 行レベルセキュリティの注意点
- LEAKPROOF演算子
- 行レベルセキュリティが適用されたテーブルにアクセスするビュー
第11章:ログイン認証と通信およびデータの暗号化
サーバ接続およびログイン認証の流れ
通信暗号化をしない場合のサーバ接続およびログイン認証の詳細
- スタートアップメッセージの送信
- PostgreSQLサーバへの接続認証方式の設定
- 接続タイプ
- 接続先データベース
- 接続ユーザー
- 接続元アドレス
- 認証方式,認証オプション
- pg_hab.confの例
- 各認証方式の解説
- Trust認証
- パスワード認証
- GSSAPI認証
- SSPI認証
- Ident認証
- Peer認証
- LDAP認証
- RADIUS認証
- 証明書認証
- PAM認証
- BSD認証
- ユーザー名マッピング──認証の際の識別名の対応規則定義
通信暗号化をする場合のサーバ接続およびログイン認証の詳細
- 暗号化リクエストのパラメータ
- sslmode
- gssencmode
- 接続タイプ
SSLの使用
- SSLによる通信の暗号化
- 基本的な設定(通信暗号化のみを使用)
- クライアント認証
- JDBCドライバの場合
- サーバ認証
- CRL──証明書失効リストの運用
データ暗号化
- ❶OSレベルでの暗号化
- ❷PostgreSQLでの透過的暗号化
- ❸カラム単位での透過的暗号化
- ❹サーバサイドでの暗号化およびアプリケーションによる暗号化
- pgcrypto
- pgp_sym_encrypt(),pgp_sym_decrypt()
- pgp_pub_encrypt(),pgp_pub_decrypt()
- 使用上の注意点
監査
- 基本機能を利用した監査
- pgAuditを利用した監査
第12章:バックアップ・リストア
バックアップの分類
- 論理バックアップ,物理バックアップ
- 論理バックアップの利点
- 論理バックアップの欠点
- 物理バックアップの利点
- 物理バックアップの欠点
- オンラインバックアップ,オフラインバックアップ
- フルバックアップ,差分バックアップ,増分バックアップ
PostgreSQLにおける論理バックアップ・リストア
- SQLのCOPYコマンドでのバックアップ・リストア
- pg_dumpでのバックアップ・リストア
- SQLスクリプトファイル形式での実行例
- アーカイブファイル形式での実行例
PostgreSQLにおける物理バックアップ・リストア
- pg_basebackupを使った物理バックアップ・リストア
- pg_basebackupでのフルバックアップ・リストア
- pg_basebackupでの増分バックアップ・リストア
- バックアップの完全性の確認(バックアップマニフェスト)
- バックアップ中のWAL取得の必要性
- レプリケーション構成時のスタンバイサーバからのバックアップ
- pg_backup_startとpg_backup_stopによる物理オンラインバックアップ・リストア
- pg_backup_startとpg_backup_stopによるバックアップ手順
- オフラインバックアップでの物理バックアップの手順
- OSの機能を使った物理バックアップ手順
- 物理バックアップのポイントインタイムリカバリ(PITR)によるリストア──データベースを任意の時点まで復元する
- ポイントインタイムリカバリ(PITR)とは
- PITRを利用したリストア手順
- タイムライン
- PITRのリカバリターゲット
- リカバリターゲットに関する他のパラメータ
- [column]WALファイル名の命名規則
- [column]archive_commandにおける留意事項
pg_rmanによる増分バックアップの取得
- pg_rmanのインストール
- pg_rmanによるバックアップ取得手順
- フルバックアップ
- 増分バックアップ
- pg_rmanによるリストア・リカバリ手順
- スタンバイからのバックアップ
- [column]スタンバイのバックアップに関しての注意点
バックアップのよくある問題と対策
- pg_backup_stopが完了しない
- バックアップ中にWALがないというエラーで停止する
第13章:テーブル,インデックスのメンテナンス
Vacuum──ガベージコレクション(不要領域回収)機能
- Vacuumとは
- ゴミタプルの回収
- 可視性マップ
- 空き領域マップ(Free Space Map)
- トランザクションIDの周回防止
- [column]トランザクションID(XID)のメンテナンス
- Vacuumの処理概要
- VACUUMコマンド
- パラレルVacuum
- Failsafeモード
Analyze──テーブルの統計情報を取得する
- Analyzeとは
- ANALYZEコマンド
- Analyzeの処理概要
自動Vacuumおよび自動Analyze
- 自動Vacuumおよび自動Analyzeの起動契機
- 自動Vacuumおよび自動Analyzeの停止
- コストに基づくVacuum遅延
- Vacuum処理の監視──pg_stat_progress_vacuumビュー
- Analyzeの監視──pg_stat_progress_analyzeビュー
よくある問題と対策
- 不要領域が回収されない
- Vacuumが長時間化している
テーブル,インデックスの再構築
- VACUUM FULL,CLUSTER,REINDEX
- pg_repackを利用した「止めない」メンテナンス
第14章:モニタリング
モニタリングとは
モニタリングは必須?
モニタリングに必要な情報
- モニタリングに必要な情報の取得元
- 情報の保存期間
- お勧めの情報取得方法
モニタリングに必要な情報の取得元の詳細
- OSの情報
- OSとPostgreSQLの状況把握のために取得する項目と取得元
- 取得間隔の設定
- どのように情報を確認すべきか
- PostgreSQLのサーバログ
- サーバログのパラメータ
- 取得間隔の設定
- どのように情報を確認すべきか
- PostgreSQLの稼働統計情報
- PostgreSQL内部の状況
- 取得間隔の設定
- どのように情報を確認すべきか
稼働統計情報
- 稼働統計情報とは
- 稼働統計情報のビューに関する注意事項
- 所持する権限によって表示される情報量が異なる
- PostgreSQLのバージョンによって異なる場合がある
取得できる稼働統計情報と活用例
- ロングトランザクションの検知と解消
- ロングトランザクションの検知と解消の例
- ❶ターミナル1でロングトランザクションを発生させる
- ❷ターミナル2でロングトランザクションを検知する
- ❸ロングトランザクションの解消方法
- ロック取得状況の確認とロック待ちの解消状況の確認(pg_locksの活用例)
- pg_locksビュー
- ロック競合とは
- ロック取得状況の確認とロック待ちの解消の例
- ❶ターミナル1で実行するロックを取得し保持するクエリ
- ❷ターミナル2で実行するロック待ちを発生させるクエリ
- ❸ターミナル3で実行するロック取得状況を確認するクエリ
- ❹ターミナル3で実行するクエリ(ロック待ちを解消)
pg_statsinfoを用いたモニタリング
- pg_statsinfoとは
- 取得する情報の一覧,スナップショット
- 出力可能なレポートの一覧
- pg_statsinfoのインストールと使用方法
- インストール方法
- postgresql.confへの追記内容(必要最低限の設定)
- テキスト形式のレポート生成方法
- 基本的な使用方法
第15章:パフォーマンスチューニング
パフォーマンスチューニングの流れ
ボトルネックを見つける
インデックスを活用する
- インデックスを作ることのメリット・デメリット
- インデックス活用によるチューニング例
- itemsテーブルに対するシーケンシャルスキャンの改善
- ordersテーブルに対するシーケンシャルスキャンの改善
- customersテーブルのcustomer_idによるソート処理の改善
- インデックスによるチューニングの結果
設定パラメータを最適化する
- shared_buffers(共有バッファ)を調整する
- work_mem(作業用メモリ)を調整する
テーブルパーティショニングを使ってクエリを高速化する
- パーティションプルーニングを使う
- パーティションワイズ結合を使う
- パーティションワイズアグリゲーションを使う
拡張統計情報を活用してプランナの見積り誤差を正す
- プランナの見積り誤差の例
- 拡張統計情報
ヒント句を使って実行計画を操作する
- pg_hint_planのインストール
- ヒント句の記述方法
- ヒント句を使ったチューニング例
- Appendix A:各パラメータの設定値の考え方
接続と認証に関する設定
- 基本設定
- 接続維持・通信障害検出
- クライアントタイムアウト
- ロギング
- SSL 関係
- その他
検索処理に関するリソース使用(ディスク,メモリ,CPU)
- 共有メモリの設定
- ローカルメモリの設定
- ファイルに関する設定
- バックグラウンドワーカの設定
- クエリ処理の際のI/O使用量の設定
- テーブルデータのライトバックの設定
- データ圧縮
WAL──トランザクションログ
- WALの基本的な設定
- WAL出力効率に関する設定
- チェックポイントに関する設定
- リカバリに関する設定
- 特殊な設定
WALアーカイブ
- 基本的な設定
- アーカイブライブラリ
レプリケーション
- WALの基本的な設定
- スタイバイ遅れの際の接続維持に関する設定(WALの保存)
- 接続タイムアウト
- ステータス更新
- 衝突解決
- ロギング
- 論理レプリケーション
サーバログ出力
- ログ出力先の設定
- ログ出力ファイルの設定
- syslog出力の設定
- ログ行のフォーマット
- 事象ごとのログ出力設定
- ログ出力の間引き設定
- 実行統計情報
- コアダンプ
Vacuum,自動Vacuum
- 基本的な設定
- 実行間隔の調整
- トランザクションID(XID)周回処理の調整
- 使用メモリ量の調整
- 共有バッファ使用量の調整
- I/O使用量の調整
- 並行してVacuumするテーブル数
- 単一のテーブル内の並列処理
- ページのプリフェッチの調整
稼働統計情報,Analyze処理
- 実行間隔の調整
- 稼働統計情報ビューの一貫性の調整
SQL実行計画
- プラン利用の可否変更
- 並列実行の調整
- Prepared文の実行計画
- JITコンパイルの設定
- データ統計の粒度調整
- パーティションワイズ結合・集約
- 結合探索の抑制
- インデックススキャンの優先度
- ハッシュ結合の優先度
- 検索応答の速さの優先度
- 制約による除外の設定
- 再帰問い合わせの結果サイズ想定
- 基本コスト値
- 遺伝的計画
設定項目のバージョン間の差分
- 16 → 17
- 15 → 16
- 14 → 15
- 13 → 14
- 12 → 13
- 11 → 12
- 10 → 11
- 9.6 → 10
- Appendix B:PostgreSQL 18の新機能と設定項目の差分
PostgreSQL 18の新機能
- 非同期I/O
- メジャーバージョンアップ時の統計情報の引き継ぎ
- 複数列B-treeインデックスにおけるスキップスキャンの追加
- UUIDv7対応
- 仮想生成列
- OAuth 2.0認可/認証
- RETURNING句での変更前の値(OLD)と変更後の値(NEW)の指定
- 時間制約
設定項目のバージョン間の差分(17→18)
- 索引
- 著者紹介