


本連載を執筆している伊藤
今回の主な目的は、
RedPen のコンポーネント
RedPenは次のコンポーネントで構成されています。
- RedPen:コンポーネント群を使って文書校正処理を実行します。
- DocumentParser:入力文書をDocumentモデルという文書を表すデータ構造に変換します。文書フォーマット毎に実装が存在します。
- Documentモデル:DocumentParserによって生成される文書を表現するデータ構造です。内部にParagraph
(パラグラフ) やSentence (文) など、 文書の部品を保持しています。 - Validator群:Documentモデル内の部分にたいして検査を行います。各Validatorは"文長検査"など、
ひとつの検査項目に対応します。 - そのほか
(Formatter、 :RedPenが校正処理を行うのに利用されるコンポーネント群です。Configuration、 Tokenizer)
RedPenを拡張する際に必要なコンポーネントはDocumentモデルとValidator群です。Documentモデルは文書を表すデータの構造です。Validator群は入力Documentの一部
以下、
Documentモデル
Documentモデルは文書フォーマットに依存しない抽象的な文書を表します。次の図はDocumentモデルを表します。次節で紹介する機能追加がフォーマットに非依存で記述できるのは、
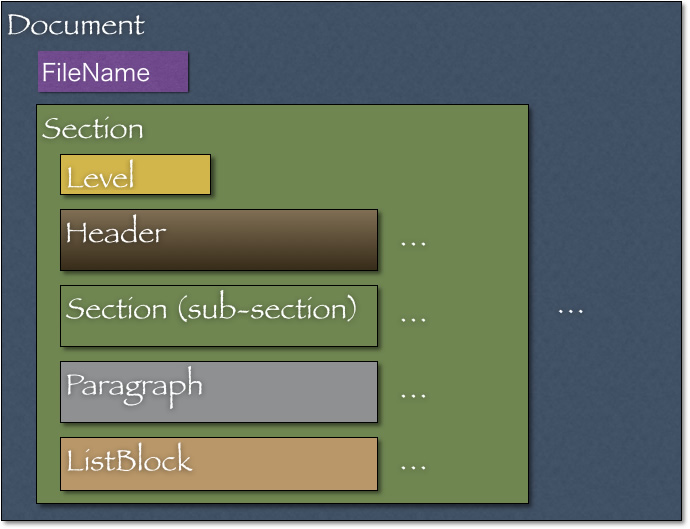
図中の四角形はDocumentモデル内のブロックを表します。各ブロックの解説は以下のとおりです。
- Document:文書を表します。ひとつのファイルに相当します。
- FileName:ファイル名を保持します。
- Header:節のヘッダを表します。文集合も保持します。
- Section:節に相当します。節は入れ子関係があります。たとえば節1は節1.
1を保持します。 - Paragraph:節内に存在するパラグラフをあらわします。図内には表示されていませんがParagraphは文
(Sentence) の集合を保持します。 - ListBlock:文内のリストを保持します。図内には表示されていませんがリスト要素は文
(Sentence) を保持します。
ブロックは入れ子構造になっています。たとえばDocumentはFileNameを持つことがわかります。ブロックを表す四角形の後ろに付いている"…"という記載は、
Sentence
先の図には登場しませんが、
- lineNum:行
- links:リンク集合
- isFirstSentence:パラグラフの開始文であればtrueそうでなければfalse
- tokens:文内の単語集合。単語はTokenizerによって分割されます。利用されるTokenizerは設定言語によって異なります。日本語
(ja) を指定した場合にはKuromojiが入力文を単語に分割します。
Sentenceは次節で述べるValidatorの入力として使用されます。
DocumentParserを追加する
DocumentParserは入力文書からDocumentを生成します。DocumentParser自体はインターフェースで、
現在までにPlainTextParser、
Validator
ValidatorはRedPenプロジェクトに存在する抽象クラスです。RedPenが提供する機能はValidatorを継承したクラスによって実装されています。たとえばSentenceLength機能はSentenceLengthValidatorというクラスで実装されています。
Validatorを継承するクラスを作るにはいくつか
validateメソッド
機能を追加するにはValidatorを継承するクラスを作り、
現状Validatorは二種類のvalidateメソッドを提供しています。ひとつは文
public void validate(List<ValidationError> errors, Sentence sentence)
public void validate(List<ValidationError> errorList, Document document)文内の情報だけで検査ができるものはSentenceを引数にとるもので十分です。しかし検査に節の情報が必要な場合にはSectionを引数にとるvalidateを実装します。Sectionを引数にとるValidatorの実装としては、
入力ブロックにエラーがみつかった場合には、
例:validateメソッド
SentenceLengthValidatorのvalidateメソッドです。パラメータは発見されたエラーを保持するerrorsと入力のSentenceです。文内に不正な表現が存在するとにerrorsにValidationErrorが追加されます。次の例でもcreateValidationErrorメソッドで生成されたエラーがerrorsに追加され、
@Override
public void validate(List<ValidationError> errors, Sentence sentence) {
if (sentence.getContent().length() > maxLength) {
errors.add(createValidationError(sentence, sentence.getContent().length(), maxLength));
}
}ここでcreateValidationErrorはValidatorクラスが提供するメソッドで、
initメソッド
RedPenではvalidatorブロックのpropertyに名前と値のペアを渡すことで、
たとえばSentenceLengthValidatorでは文の最大文長をpropertyを利用してデフォルトの設定を変更できます。次のコードはSentenceLengthValidatorで文長を150に設定した例です。
<validator name="SentenceLength">
<property max_len="150" >
</validator>以下のSentenceLengthValidatorのinitメソッドで、
@Override
protected void init() throws RedPenException {
this.maxLength = getConfigAttributeAsInt("max_len", DEFAULT_MAX_LENGTH);
}preValidateメソッド
一度文書内の情報を抽出したのちvalidateで検査を実行したい場合には、
たとえばpreValidateメソッドはDuplicateSection機能を実現するために利用されています。DuplicateSectionは文書内に存在する類似する節ペアを抽出します。
DuplicateSectionではpreValidateメソッドをはじめに文書中すべてのSectionにたいして呼び出し、
追加されたValidatorの利用
Validatorを拡張して作成したクラスが提供する機能を呼び出すには以下の二つのステップが必要です。ひとつは設定ファイルへの追加で、
設定の追加
RedPenでは"cc.
作成した機能を設定に追加する際には語尾のValidatorを抜かした名前を指定します。すると指定したValidatorが生成され、
<validators>
<validator name="ChineseSuffix" />
</validators>エラー文テンプレートの追加
エラー文は継承したValidator毎に存在します。以下はSentenceLengthValidatorのエラー文テンプレートです。
SentenceLengthValidator=文長("{0}")が最大値 "{1}" を超えています。SentenceLengthValidatorでは"{0}"に入力文の長さ、
- redpen/
redpen-core/ src/ main/ resources/ cc/ redpen/ validator/ - redpen/
redpen-core/ src/ main/ resources/ cc/ redpen/ validator/ sentence/
両ディレクトリの中に各入力言語用のエラー文テンプレートファイル
その他のコンポーネント
上記のDocumentモデルとValidatorを理解していれば機能を実装するのに十分です。以下に紹介するのは、
RedPen
RedPenはDocumentParserや設定ファイルに登録されたValidator群を利用して文書の検査を行います。登録されたValidator群を文書内のブロックに適応し、
Formatter
FormatterはRedPenオブジェクトによって返されたエラー集合を出力するためのフォーマッティングを行います。出力フォーマットはテキスト、
Configuration
Configurationは設定ファイルを読み込むためのクラスです。設定ファイルに追加された機能や、
Tokenizer
Tokenizerは入力文書を単語に分割します。デフォルトではWhiteSpaceTokenizerというスペースで単語を分割するだけなのですが、
Tokenizerによって分割された単語は検査で利用できます。具体的にはValidator.
まとめ
今回はRedPenの内部について解説しました。具体的にはRedPenに機能を追加するのによく利用するクラスDocumentParserとValidatorsを解説しました。次回は今回の知識を基に簡単な機能を追加してみます。