2016年9月8日から10日まで、国立京都国際会館にて「RubyKaigi 2016」が開催されました。基調講演の模様をレポートします。
RubyKaigi 2016 最終日となる3日目の基調講演はRubyコミッタである、成瀬ゆいさんです。RubyKaigiに参加してCRubyに貢献してみたくなった人を念頭に、新機能・最適化・トラブルシュートを軸に発表しました。
重要なのは具体的なユースケース
新機能は大きく二つに分けることができると言います。一つは新しくメソッドやクラスを追加すること。もう一つはRubyを動かすことのできる環境を増やすことです。
前者の場合、現実的なユースケースをあげて、本当にほしい機能を明確にすることが重要だと、成瀬さんは言います。Rubyに取り込まれたケース と取り込まれなかったケース を取り上げて、説明をしていました。取り込まれたケースは、RubyのStringに不正なバイト列が含まれているときに、それを置き替えたいというものでした。最初は適切なユースケースが見当たらず、機能実装が見送られていました。例えばWebフォームから不正なバイト列が送られてくるというケースでは、それはユーザーにエラーを伝えることができることから、適切なユースケースではなかったと言います。Rubyで対応するべきユースケースとして、Webクローラーを例示しました。修正が可能なファイルの読み取りなどと異なり、Webクローラーの場合はクライアント側で不正なバイト列を処理する必要があります。このとき追加されたString#scrubを例に、CRubyのコードを解説しました。
Rubyの実行環境については、clangやVisual C++ 2015を例にあげました。clangは最適化がgccに比べて強くかかるときがあります。RubyのGCは、オブジェクトのポインタがメモリ上のどこにも存在しないと回収します。その結果gccでは問題が起こらなくても、clangでは問題が発生することがありました。もっとも厳しかった例としてContinuationの中でRubyのGCが壊れていたケースをあげ、説明していました。
様々な側面からRubyの速度を考える
次に最適化について話をしました。速度改善に注目し、Rubyで書かれたアプリケーション・HashやStringクラスなどC言語で書かれたクラス・RubyのVM(Virtual Machine)の3つに分けて説明しました。
まず速度改善の定石として、次のステップを紹介しました。
ベンチマークやプロファイルを取得する
ボトルネックを発見する
ボトルネックを解消する
New Relicを使ってRailsアプリケーション(bugs.ruby-lang.orgのRedmine)のプロファイルを取得してみたところ、IO待ち以外では目立ったボトルネックは見つからなかったと言います。
Ruby組み込みライブラリの速度改善の例として、Regexp#match?を取り上げました。このメソッドはRuby 2.4で追加されるメソッド(r55061 )で、正規表現にマッチするか否かをBooleanで返し、$&特殊変数を更新しないというメソッドです。MatchDataを作成しない分だけ高速になります。
VMを早くするアイディアとして、JITやレジスタマシンについて考察しました。Railsアプリケーションのプロファイルでみたように、今あるアプリケーションでは目立ったボトルネックがなく、JITの効果があまりないそうです。今までにベンチマークしてこなかったタイプのアプリケーションでJITの効くものが公開されると、CRubyにJITが入るかもしれないと述べました。また、レジスタマシンについては#12589 というチケットがあるので、興味のある方は手伝ってくださいと呼びかけました。
procfsやcore fileを活用する
最後のテーマとしてデバッグやプロファイリング、SEGVしたときの調査方法といったトラブルシューティングについて説明しました。
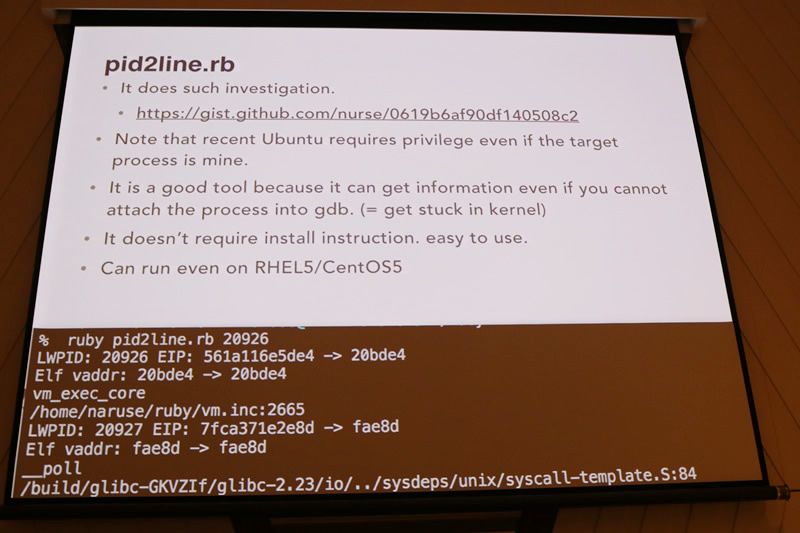
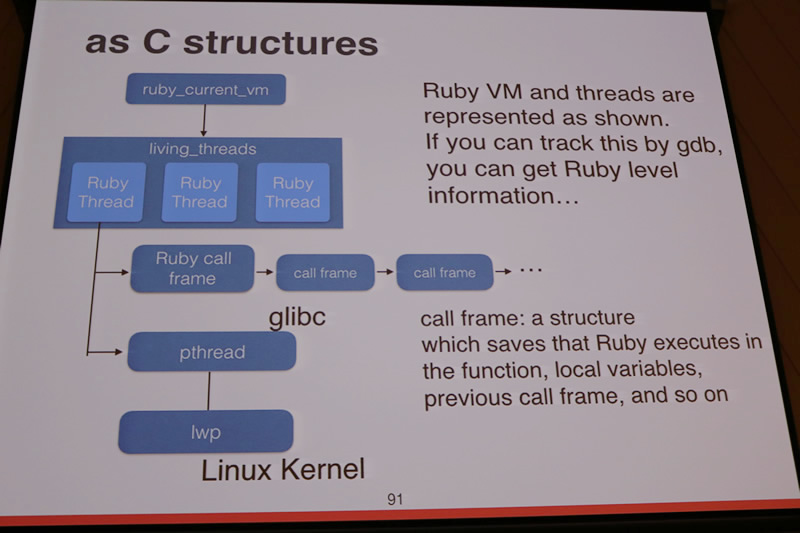
正規表現のマッチングでバックトラックの回数が爆発したときや、カーネル内部で無限ループに陥っているときなどはRubyのレベルでは何もできなくなってしまいます。gdbのアタッチすらできないときでも、( Linuxの)procfsを利用することでプロセスの状態を理解できると言います。具体的には/proc/<pid>/statと/proc/<pid>/mapsから、どのライブラリで固まっているかを判定し、ライブラリのsymbol tableと突き合わせることで具体的な関数を割り出します。この作業はアドレスの計算を伴う煩雑なものなので、成瀬さんはpid2line というツールを作ったと話しました。
SEGVしたときの調査では、backtraceとcore fileの情報をベースに調査を進めるそうです。backtraceにはRubyレベルのbacktraceと、C言語レベルのbacktraceが表示されますが、多くの場合でC言語レベルのbacktraceが重要だと言います。また、bugs.ruby-lang.org に報告するときは、必ず全行分の情報を送ってほしいと言及していました。
core fileはクラッシュした時点のメモリの内容をダンプしたもので、gdbに読ませることでデバッグに役立てることができます。core fileの内容からRubyの状態を把握するためのツールとして、Ruby本体に添付されている.gdbinit を利用します。C言語で書かれたRubyの関数をgdbのスクリプトで再実装する必要があり、またRuby本体の開発に合わせてそのスクリプトも書き直していかないといけないため、管理が大変だと語っていました。
まとめ
最後に本日の発表を以下のようにまとめました。
現実に即したユースケースをきちんと考える
現実のアプリケーションのボトルネックが何かをきちんと調べる
質疑応答では、「 Rubyのなかには、みんなの関心が薄いところもある。そういう部分に興味あがって、手を挙げていけば貢献できる部分はある」と答え、締めくくりました。
VIDEO
https://speakerdeck.com/naruse/dive-into-cruby