10月16日、株式会社ブレインパッドのセミナールームにて、「データサイエンティスト協会 木曜勉強会 #2」が開催されました。
今回は、データの取得や加工、クレンジング、分析、ビジュルゼーションまでの一貫したデータ分析方法と、データ全体を俯瞰的にとらえる分析技術についての、2つのセッションがありました。本稿では、このイベントの模様をレポートします。
『クレンジングからビジュアライズまで実践!データ解析超入門!』
株式会社電通の近藤康一朗氏が、データの収集、クレンジング/加工、分析、ビジュルゼーションまでを実例を通して発表しました。「データ分析の流れ、データ分析をどう考えるかをテーマ」とした内容でした。
写真1 近藤康一朗氏

データ分析は統計手法などを用いた分析について注目されますが、実際のデータ分析では「分析するまでのデータ加工、クレンジング」と「分析結果に分かりやすく表現」することが重要です。
データ分析は限らた資源・時間で、手法・手順を問わず、いかにアウトプットを出し、依頼主の要求に対応することが大事です。データサイエンティストは、データアウトプットのちからをつけるべきと述べました。
要件定義に時間をかけるべきで、依頼主の要求、何がほしいのかを検証を行わないとアウトプットと要求が合わないことになると述べました。
データ分析を行う上で、データサイエンティストは、コンサルタントやプログラマー、セールス、統計分析者の役割を担うジェネラリストであるべきだと言います。各分野の専門家には劣るかもしれないが、総合力が必要であると述べていました。
実際のデータ分析作業の流れを、オープンデータを使用して説明しました。データ分析は、大きく「収集」「加工、クレンジング」「分析」「集計」「ビジュアライズ」の手順に分かれます。各手順についての手法、気をつける点について述べました。
使用したオープンデータは、国立情報研究所が公開している「ニコニコ動画コメント等データ」でした。
データの取得
データの取得には、wgetを使用しました。wgetは単純なダウンロードツールと思われていますが、クローリングも可能でクローラーして使用ができます。
ダウンロードしたデータは、動画のメタファイルで、動画情報とタグ情報がJSON形式で入っています。このメタデータを分析しやすいように加工を行います。
データのクレンジング・加工
データの加工にはPythonを使用します。PythonのDictionaryとJSON形式が似ており加工が行い易いです。
SQLの集約関数を使用することで、データの傾向がつかめ、異常値が分かりやすくなると述べていました。発表ではSQLliteにデータを投入し、データ構造を確認しながらクレンジングを行う方法でした。SQLでコメント率、マイリスト率の平均値を集計しデータの傾向、異常値を見ていました。
時系列よるデータ分析を行いたい場合があります。その様な場合は、Pentahoでデータを時系列のデータへ加工できます。
データによっては、区切り文字がデータに含まれている場合があります。そのようなときなUNIXコマンドを使って加工します。UNIXコマンドには、テキスト加工に向いているコマンドが多数あります。
データの分析
近藤氏は、データ分析を行う前に「どんなデータ分析を行ったら面白いか」を考えるべきと述べていました。また、分析の切り口はアイディアが必要であり、次の3パターンにだいたい当てはまると述べていました。
- まとめる。分ける
- 新指標を作る
- 比較する
分析の切り口のアイディアを出すには、コンサルタントの分析フレームが参考になります。
実際の分析作業では、分析にぴったり合うデータはなかなかなく、目的に近づくようにデータ加工を行って使います。
データのビジュアライズ
分析結果をビジュアライズする際にどのような表現方法をとるべきかは、何が分かってほしいのかを考える必要があり、分かってほしいのもが決まれば、伝え方が決まると述べていました。
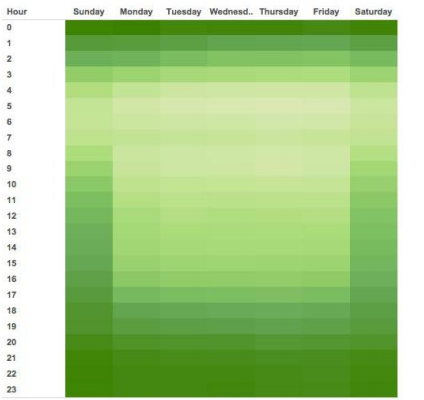
発表では、時間と曜日での傾向を分かってほしいために、多いところを濃く、少ないところを薄くし、色の濃淡で表現しました。さらに、数字(要素)を抜くことで、時間と曜日によって多い少ないの傾向を直感的に掴めるようにしました。
図1 色の濃淡を変える
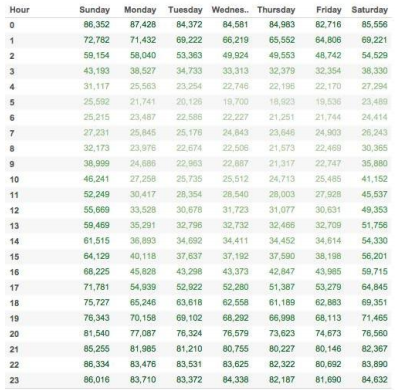 図2 要素を抜く
図2 要素を抜く

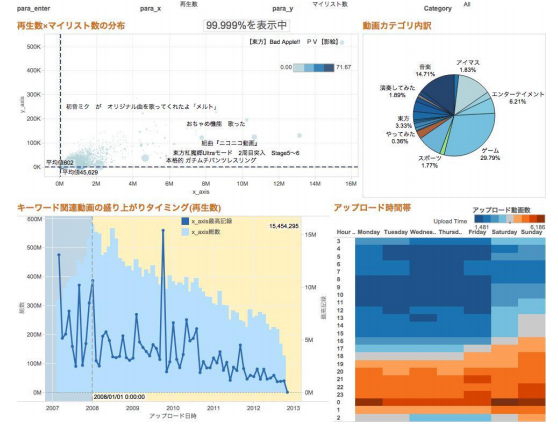
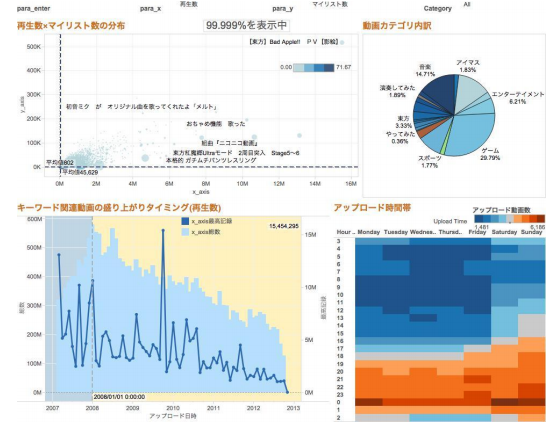
ダッシュボードのデザインとして、BIツールの「Tableau(タブロー)」を紹介しました。Tableauは、ガートナー、Forresterなどの調査機関からNo.1の評価を受けているBIツールで、あらゆるデータを高速かつ任意に加工し、ダッシュボード化することができるツールです。
図3 Tableauによるダッシュボード例
まとめ
データ収集からデータビジュアライゼーションまでのデータ分析の工程を実例を通しの発表内容でデータ分析初心者にも、非常に分かりやすい内容でした。最近ではデータ分析の書籍が多く出版されていますが、近藤氏が「専門書を読むより、オープンデータを使って、データ分析を一巡させることが大切」と述べていたように、オープンデータを使って自分なりのデータ解析手法を見つけていかがでしょうか。
クレンジングからビジュアライズまで実践!データ解析超入門!
『ビッグデータの0次分析手法と適用例のご紹介 ~俯瞰から始まる企業内ビッグデータの活用~』
サイバネットシステム株式会社の矢野弘海氏が、toorPIAを用いてのデータ可視化による全体分析について発表しました。
写真2 矢野弘海氏

toorPIAによる0次分析
現在は情報過多であり、情報が埋もれてしまうことがあります。これは情報検索での課題と捉えています。例えば、検索サイトでは実際にほしいデータが後ろのページにあることがあります。
矢野氏は、0次分析としてデータ全体を俯瞰的に視覚化し、全体の傾向を掴むことが良いと述べました。天気図が良い例で、単純な気象情報は数字の羅列で分かりづらいですが、天気図で可視化することで天気情報を把握することが容易になります。
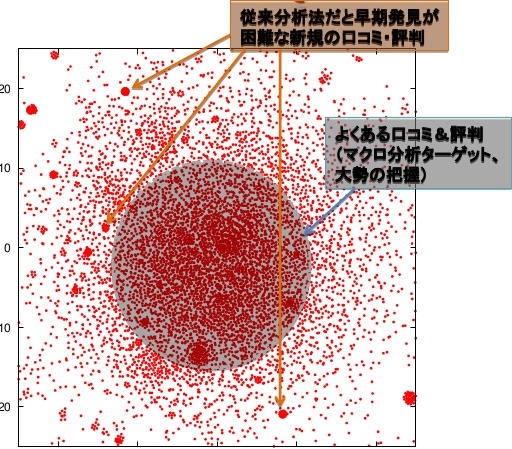
発表で紹介した「toorPIA」は、データ正規化や、データ軸を決めることはデータ取り込むだけでデータを俯瞰的にMap化(視覚化)できます。Map化したデータは距離により類似性を表すため、類似性が高いデータがまとまりになります。このまとまりを詳細に分析していくことでデータの傾向を掴めます。
図4 Map化されたデータ
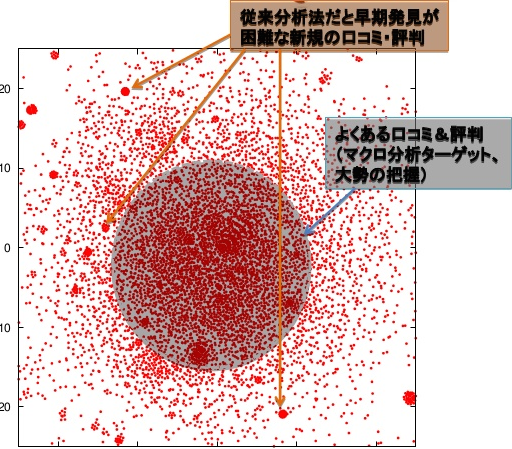
toorPIAを用いた事例として、Twitterのツイートと、センサーデータのMap化の例を紹介されました。Twitterの例では、よくある口コミ、ワードは大きなまとまりとしてMap化されます。外れた所でのまとまりを分析することで、新しい話題のワードを把握することができます。
センサーデータの例では、正常時のデータをMap化しておきます。リアルタイムでセンターデータをMap化し、正常時のまとまりから外れたまとまりを発見することで、異常を早期に発見することができます。
まとめ
データ分析を行う前にデータを俯瞰的に見たほうが好ましいと良く言われています。散布図などで見ることが一般的かと思いますが、とりあえずデータを投入するだけで類似したデータのまとまりをMap化しデータ全体の傾向が掴み易い点が良いです。
ビッグデータの0次分析手法と適用例のご紹介 ~俯瞰から始まる企業内ビッグデータの活用~