


今回は百度
安価なGPUとLLM
ローカルでLLMを使用する場合、どうしてもGPUの性能に引っ張られてしまいます。高価なGPUを使用すればするほど大きなモデルを動かすことができますが、可処分所得には制限があります。また高価なGPUを使用するとPCもそれなりのものが必要になり、出費が青天井になってしまいます。もちろん筆者の嘆きではなく、一般論です。
そんな中MoEに対応したモデルであれば、安価なGPUであっても動作します。これを使わない手はないわけですが、現状あまり多くのモデルがリリースされていません。著名なものはQwen3で、企業ユースも無料になったLM Studioや、第841回と第849回で紹介したAlpacaはすでに対応しています。
Qwen3は中国のEコマース大手であるAlibabaがリリースしていますが、中国の検索エンジン大手Baiduも6月30日にERNIE 4.
現在こちらはLM StudioでもAlpacaでも対応しておらず、
なおMoE
使用するPCのスペック
今回使用するPCのスペックは次のとおりです。
| メーカー | 型番 | 備考 | |
|---|---|---|---|
| CPU | AMD | Ryzen 7 5700X | |
| マザーボード | ASRock | B550M Steel Legend | |
| メモリー | Crucial | CT2K16G4DFRA32A | |
| SSD | MSI | S78-440P130-P83 | 960GB |
| ケース | InWin | IW-BL057B/ |
使用するグラフィックボードはMSI GeForce RTX™ 3050 LP 6Gと玄人志向 RD-RX6400-E4GB/
グラフィックボードは高価なものでなくてもいいのですが、CPUに関してはそれなりのものでないと待ち時間が長くなります。今回使用したRyzen 7 5700Xは価格と性能のバランスが取れているように感じました。
SSDは検証機の都合でSATA接続のものにしましたが、大きなモデルはファイルサイズも大きいので、可能な限り高速のSSDにすると読み込み時間が大幅に短縮されるのでおすすめです。
ランタイムの準備
llama.
NVIDIAの場合
NVIDIAのGPUを使用している場合は、プロプライエタリなドライバーのインストールは必須です。インストールされているか確認しましょう
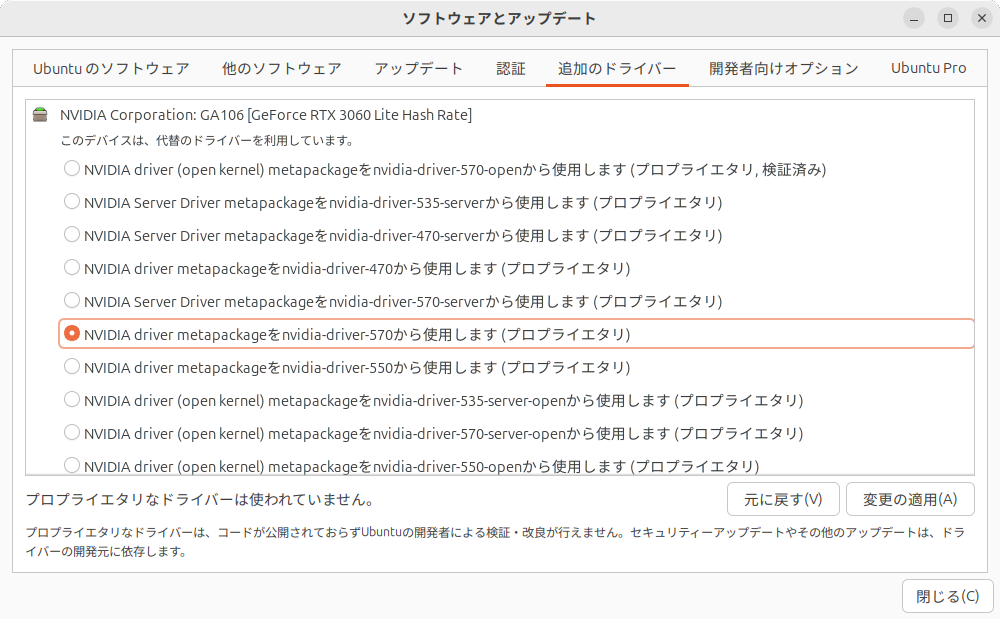
CUDAの実行環境もインストールします。次のコマンドを実行してください。
$ sudo apt install nvidia-cuda-toolkit
AMDの場合
AMD Radeonの場合、少々複雑です。
使用するROCmはカーネルモジュールを使用するのですが、Ubuntuの最新バージョンに必ずしも追随してるわけではありません。
どうしてもタイムラグが発生してトラブルになるので、最初からカーネル6.
次のコマンドを実行してカーネル6.
$ sudo apt install linux-image-generic linux-headers-generic
続けて第743回を参考に、メニューを表示し、選択肢たバージョンをデフォルトにするよう/etc/
$ diff -u /etc/default/grub.old /etc/default/grub
--- /etc/default/grub.old 2025-07-21 23:30:36.644119891 +0900
+++ /etc/default/grub 2025-07-21 23:31:08.080059463 +0900
@@ -3,9 +3,10 @@
# For full documentation of the options in this file, see:
# info -f grub -n 'Simple configuration'
-GRUB_DEFAULT=0
-GRUB_TIMEOUT_STYLE=hidden
-GRUB_TIMEOUT=0
+GRUB_DEFAULT="saved"
+GRUB_SAVEDEFAULT="true"
+GRUB_TIMEOUT_STYLE=menu
+GRUB_TIMEOUT=5
GRUB_DISTRIBUTOR=`( . /etc/os-release; echo ${NAME:-Ubuntu} ) 2>/dev/null || echo Ubuntu`
GRUB_CMDLINE_LINUX_DEFAULT="quiet splash"
GRUB_CMDLINE_LINUX=""
再起動してカーネル6.
$ sudo apt purge $ sudo apt purge linux-image-generic-hwe-24.04 linux-headers-6.14.0-24-generic linux-image-6.14.0-24-genericlinux-headers-generic-hwe-24.04 $ sudo apt autoremove --purge
続けてROCmをインストールします。ROCmはバージョンによってインストール方法が異なるので、詳細はドキュメントを参考にしてほしいのですが、6.
$ wget https://repo.radeon.com/amdgpu-install/6.4.1/ubuntu/noble/amdgpu-install_6.4.60402-1_all.deb $ sudo apt install -y ./amdgpu-install_6.4.60402-1_all.deb $ sudo apt update $ sudo apt install python3-setuptools python3-wheel $ sudo usermod -a -G render,video $LOGNAME $ sudo apt install -y rocm amdgpu-dkms
インストール後、再起動します。
llama.cppのビルド
準備
いよいよllama.
$ sudo apt install -y git git-lfs cmake g++ libcurlpp-dev $ mkdir ~/git $ cd ~/git $ git clone https://github.com/ggml-org/llama.cpp.git $ cd llama.cpp $ mkdir build
NVIDIAの場合
NVIDIAのGPUを使用している場合は、次のコマンドを実行してビルドしてください。
$ cmake -B build -DGGML_CUDA=ON $ cmake --build build --config Release -j 16
AMDの場合
AMD Radeonの場合は少々厄介で、User Guide for AMDGPU Backendを参考に、自分が使用しているRadeonのgfx某のIDを理解しないといけません。今回使用するRadeon RX 6400はgfx1034ですが、ROCmが対応していないのでgfx1032とします。
IDがわかったら、次のコマンドを実行します。
$ HIPCXX="$(hipconfig -l)/clang" HIP_PATH="$(hipconfig -R)" cmake -S . -B build -DGGML_HIP=ON -DGPU_TARGETS=gfx1032 -DCMAKE_BUILD_TYPE=Release $ cmake --build build --config Release -j 16
モデルの変換
ERNIE 4.
ERNIE-4.
GGUFへの変換にはPythonスクリプトを使用します。同時にvenvも使用します。venvに関しては第850回をご覧ください。
次のコマンドを実行してスクリプトを動かす環境を準備します。
$ sudo apt install python3-pip python3-venv $ python3 -m venv ~/git/.gguf $ source ~/git/.gguf/bin/activate $ pip3 install -r llama.cpp/requirements.txt
続けてGGUFへの変換と量子化をいっぺんにやってしまいます。
$ cd ~/git $ git clone https://huggingface.co/baidu/ERNIE-4.5-21B-A3B-PT $ llama.cpp/convert_hf_to_gguf.py ERNIE-4.5-21B-A3B-PT $ llama.cpp/build-cpu/bin/llama-quantize ERNIE-4.5-21B-A3B-PT/ERNIE-4.5-21B-A3B-PT-F16.gguf ERNIE-4.5-21B-A3B-PT/ERNIE-4.5-21B-A3B-PT-F16-q4_k_m.gguf q4_K_M
これで~/git/
llama.cppで動作させる
NVIDIAの場合
llama.
$ llama.cpp/build/bin/llama-bench -m ERNIE-4.5-21B-A3B-PT/ERNIE-4.5-21B-A3B-PT-F16-q4_k_m.gguf -ngl 10
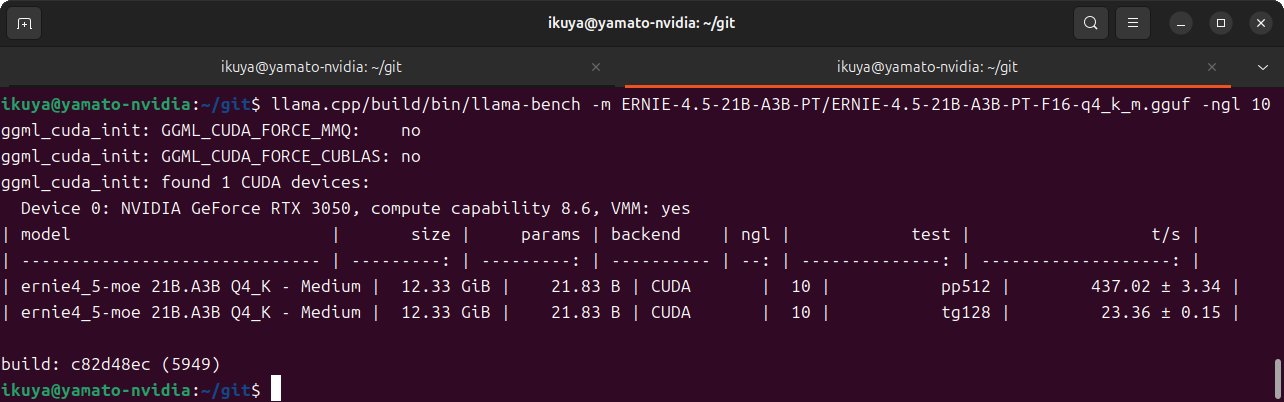
最後の
実際の問い合わせは次のようなコマンドを実行します
$ llama.cpp/build/bin/llama-cli -m ERNIE-4.5-21B-A3B-PT/ERNIE-4.5-21B-A3B-PT-F16-q4_k_m.gguf -p "偏りのないコインを表が出るまで投げ続け、表が出たときに、賞金をもらえるゲームがあるとする。もらえる賞金は、1回目に表が出たら1円、1回目は裏が出て2回目に表が出たら倍の2円、2回目まで裏が出ていて3回目に初めて表が出たらそのまた倍の4円、3回目まで裏が出ていて4回目に初めて表が出たらそのまた倍の8円、というふうに倍々で増える賞金がもらえるというゲームである。ここで、このゲームには参加費(=賭け金)が必要であるとしたら、参加費の金額が何円までなら払っても損ではないと言えるだろうか。" -no-cnv -ngl 10
「-no-cnv」
ほかにもllama.
AMDの場合
ROCmが対応しているグラフィックボードの場合はNVIDIAと同様でいいのですが、ROCmに非対応の場合、厳密にはRadeon RX 6400の場合は次のコマンドを実行します[1]。
$ HSA_OVERRIDE_GFX_VERSION="1032" llama.cpp/build/bin/llama-bench -m ERNIE-4.5-21B-A3B-PT/ERNIE-4.5-21B-A3B-PT-F16-q4_k_m.gguf -ngl 6 $ HSA_OVERRIDE_GFX_VERSION="1032" llama.cpp/build/bin/llama-cli -m ERNIE-4.5-21B-A3B-PT/ERNIE-4.5-21B-A3B-PT-F16-q4_k_m.gguf -p "偏りのないコインを表が出るまで投げ続け、表が出たときに、賞金をもらえるゲームがあるとする。もらえる賞金は、1回目に表が出たら1円、1回目は裏が出て2回目に表が出たら倍の2円、2回目まで裏が出ていて3回目に初めて表が出たらそのまた倍の4円、3回目まで裏が出ていて4回目に初めて表が出たらそのまた倍の8円、というふうに倍々で増える賞金がもらえるというゲームである。ここで、このゲームには参加費(=賭け金)が必要であるとしたら、参加費の金額が何円までなら払っても損ではないと言えるだろうか。" -no-cnv -ngl 6
GeForce RTX 3050と比較してVRAMが少ないからか、GPUに依存する処理を少なくする必要がありました。
まとめ
ローカルLLMのいいところはこのいろいろ試すが簡単にできることです。ただしストレージに空き容量がある限りではありますが。