


今回はInference Snapsで簡単にQwen 3.
Inference Snapsとは
Inference Snapsは、Ubuntu Weekly Topics 2026年5月1日号で紹介されている
Inference Snapsは総称で、実際にはLLMのモデルごとにsnapパッケージが1つずつ用意されています。そしてそのsnapパッケージにはllama.
5月1日号で紹介されたことからも推測できるように、まだまだ開発中の技術ではあります。しかし現在でもそれなりに動作するため、今回紹介することとしました。
使用するハードウェア
今回使用するハードウェアは、第883回で紹介したMinisforum AI X1 PROです。ただしメモリーは64GBで、SSDも別物です。
使用するOSはUbuntu 26.
使用するモデル
Inference Snapsとして用意されているモデルはドキュメントで確認できます。
今回使用するのはQwen 3.
インストール
インストールは通常のsnapパッケージと同じ方法です。
$ sudo snap install qwen3-6
snapサーバーの転送速度は必ずしも速いとはいえず、20GB超のパッケージをダウンロードするため、かなり時間がかかります。
Inference Snapsを操作する
状態確認
Inference Snapsはそれぞれパッケージ名と同じコマンドが用意されています。すなわち今回だとqwen3-6です。まずは状態を確認してみましょう。次のコマンドを実行してください。
$ qwen3-6 status
engine: cpu
services:
server: active
server-webui: active
endpoints:
openai: http://127.0.0.1:8342/v1
webui: http://127.0.0.1:8343/
model:
name: qwen3-6-35b-a3b-ud-q4-k-m
内部で動作しているllama.
モデルはunslothが用意しているQwen3.
エンジンの変更
Qwen 3.
ということで次のコマンドを実行してください。
$ qwen3-6 list-engines ENGINE VENDOR SUMMARY COMPAT cpu* Canonical Ltd CPU-optimized for workstations yes nvidia-gpu Canonical Ltd CUDA optimized for workstation GPUs no amd-gpu Canonical Ltd ROCm-optimized for workstation GPUs no
このようにcpuとnvidia-gpuとamd-gpuが現段階では用意されています。Vulkanも欲しいところではありますが、それはさておきamd-gpuに切り替えます。次のコマンドを実行してください。
$ sudo qwen3-6 use-engine amd-gpu Need to install the following components: - llamacpp-rocm (1.1GiB) Do you want to continue? [Y/n] Installed llamacpp-rocm Engine changed to "amd-gpu". Restart qwen3-6 to apply the changes? [Y/n]
もう一度状態を確認してみましょう。
$ qwen3-6 status
engine: amd-gpu
services:
server: active
server-webui: active
endpoints:
openai: http://127.0.0.1:8342/v1
webui: http://127.0.0.1:8343/
model:
name: qwen3-6-35b-a3b-ud-q4-k-m
無事にamd-gpuに変更できました。
設定項目の確認
次のコマンドを実行すると、設定項目を確認できます。
$ qwen3-6 get http.host: 127.0.0.1 http.port: 8342 sleep-idle-seconds: 600 verbose: false webui.http.host: 127.0.0.1 webui.http.port: 8343
このキーはそのままその値の変更にも使えます。例えばWebUIのポートを8080にしたい場合は、次のコマンドを実行します。
$ sudo qwen3-6 set webui.http.port=8080 Restart qwen3-6 to apply the changes? [Y/n] y
変更できたか確認してみましょう。
$ qwen3-6 status
engine: amd-gpu
services:
server: active
server-webui: active
endpoints:
openai: http://127.0.0.1:8342/v1
webui: http://127.0.0.1:8080/
model:
name: qwen3-6-35b-a3b-ud-q4-k-m
変更できました。
Inference Snapsの無効化
Inference Snapsが不要になれば削除すればいいのですが、一時的に無効化したい場合は次のコマンドを実行します。
$ sudo snap stop --disable qwen3-6
再度有効化する場合は次のコマンドを実行します。
$ sudo snap start --enable qwen3-6
WebUIにアクセスする
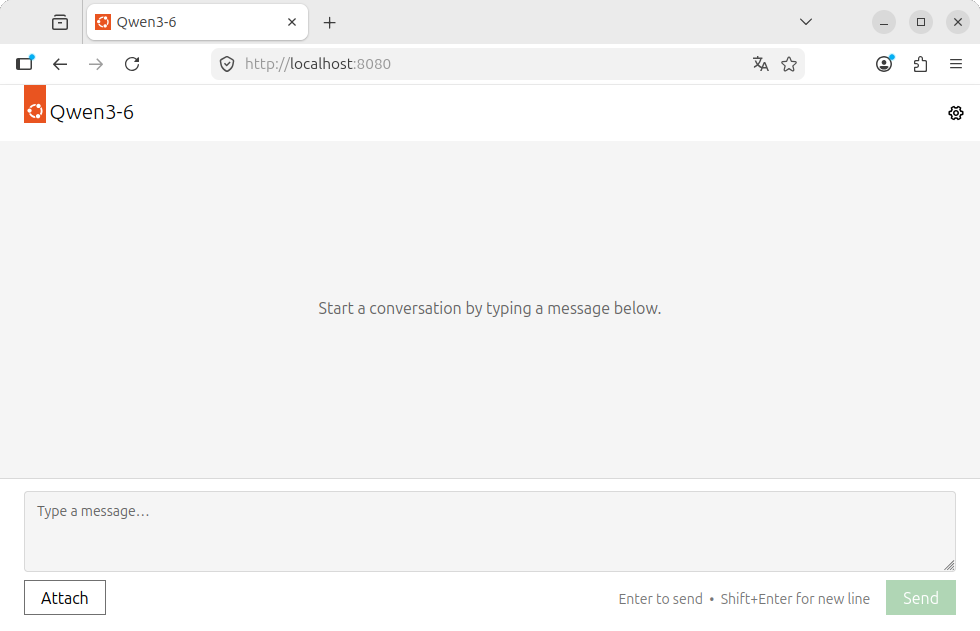
Inference Snapsを使用するためにWebUIにアクセスする場合は、webui:の値をURLとして入力するだけです。図1がWebUIにアクセスしたところです。
llama.
サンクトペテルブルクのパラドックスも難なく回答しています
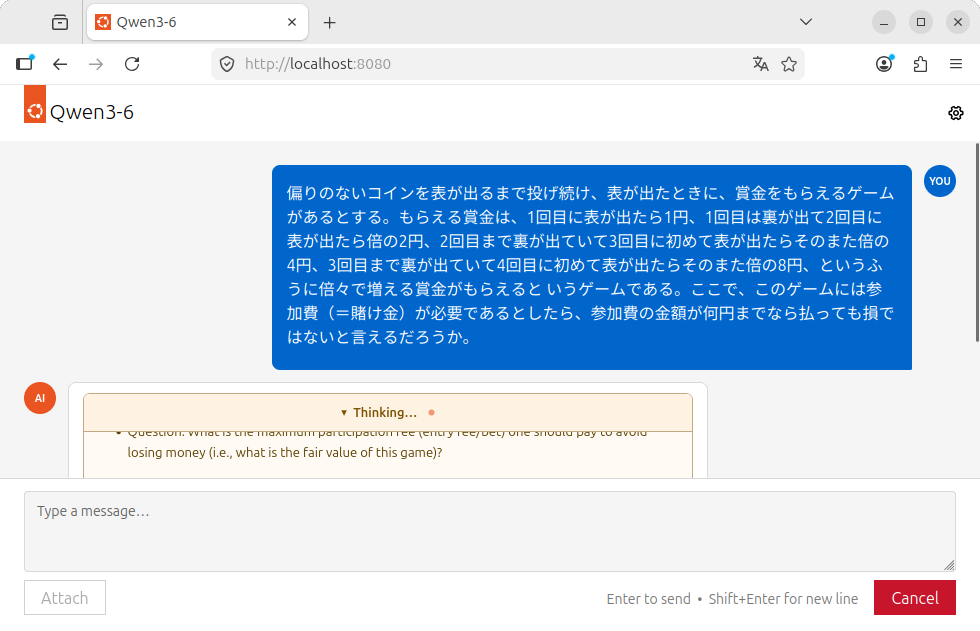
独自のWebUIを採用しているからか、第902回で紹介したFirefoxのローカルエージェントとしてはうまく動作しませんでした。具体的には
Open WebUIを使用する
Inference SnapsビルトインのWebUIではなく、Open WebUIも使用できます。使用するのはsnapパッケージ版です。
まず、先の例のようにWebUIのポートを8080にした場合は、デフォルトに戻してください。Open WebUIがポート8080を使用するためです。
$ sudo qwen3-6 set webui.http.port=8343
ポート8080が未使用であることを確認して、次のコマンドを実行します。
$ sudo snap install open-webui $ sudo snap connect open-webui:config qwen3-6:open-webui $ sudo snap restart open-webui
たったこれだけでOpen WebUIが使えてしまうのは、なかなかすごいのではないでしょうか
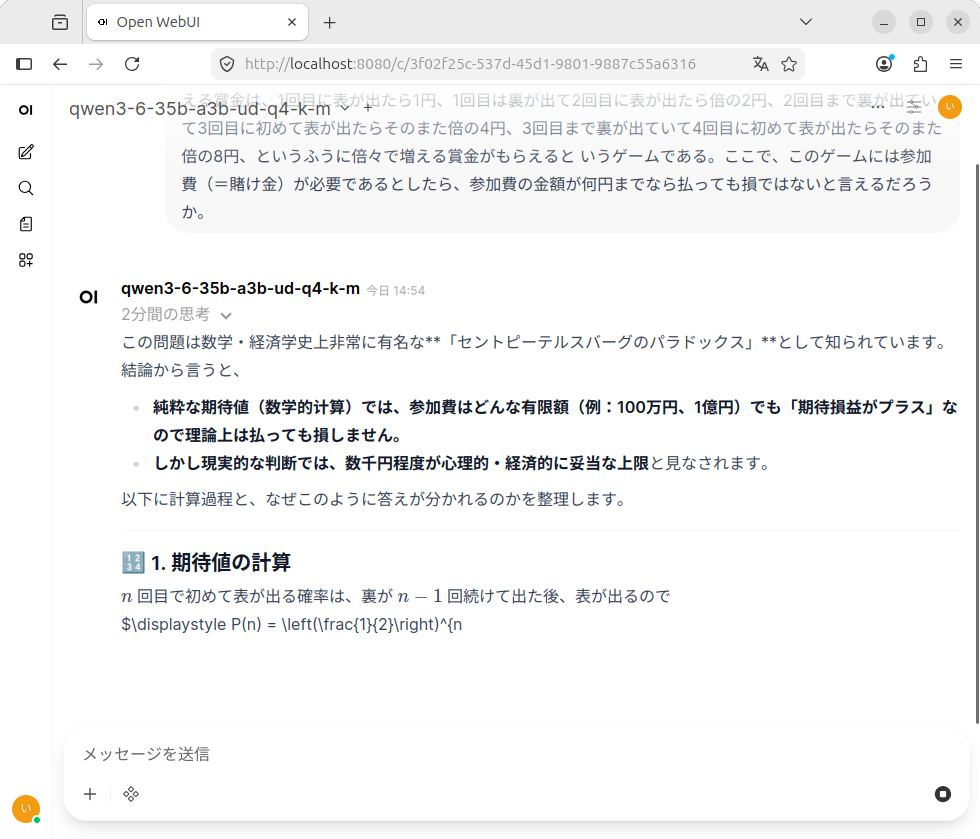
まとめ
このようにInference Snapsは、世に出てまださほどの時間が経っていないものの、既存のモデルや実行エンジン
Vulkan対応やNPU対応など、まだまだやることが多そうであり、先が楽しみです。