



「実践的データ基盤への処方箋」
- データエンジニア大集合!
「実践的データ基盤への処方箋」 輪読会レポート 〜データ整備編〜 (第1回) - データエンジニア大集合!
「実践的データ基盤への処方箋」 輪読会レポート ~データ基盤システム編~ (今回) - データエンジニア大集合!
「実践的データ基盤への処方箋」 輪読会レポート 〜データ組織編〜 (第3回)
2022年1月から2月にかけて、
データ収集は試行錯誤の連続
第2回輪読会はna0氏が進行を務めました。最初の発表者は、

土川稔生(@tvtg_24 )
株式会社タイミーの1人目データエンジニアとしてBigQueryを中心としたデータ基盤の構築、
元々AIエンジニアとして働いている時にデータの上流から活用までを全て知りたいという思いからデータエンジニアに興味を持ち、
- 第2章 データ基盤システムのつくり方
- 2-1 一般的なデータ基盤の全体像と分散処理の必要性を理解する
- 2-2 データソースごとに収集方法が違うこと、
その難しさを理解する - 2-3 ファイルを収集する場合は最適なデータフォーマットを選択する
- 2-4 APIのデータ収集では有効期限や回数制限に気をつける
発表の冒頭では、
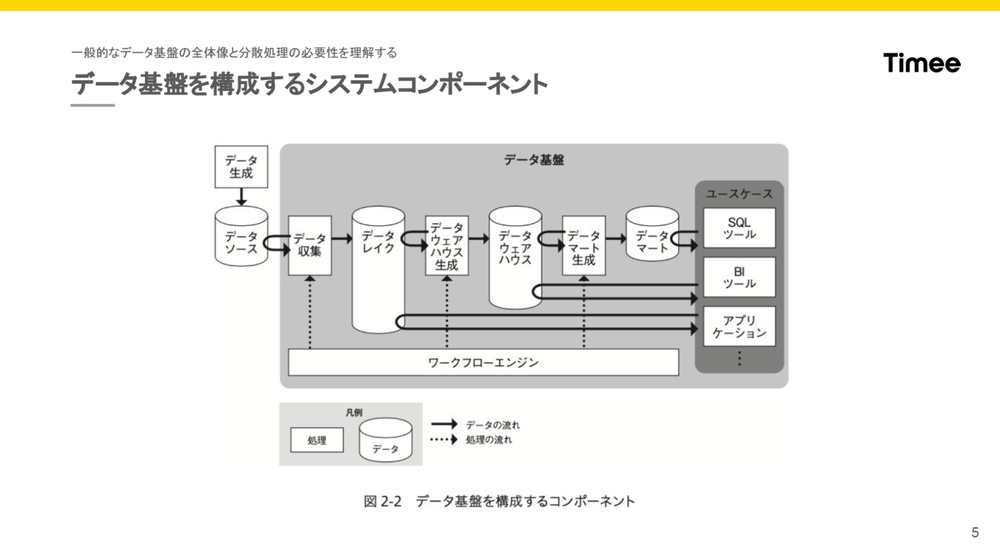
- 土川
- 「データレイクにはデータソースをそのまま加工せずに持っていき、
データマートはユースケースに基づいて1対1になるように作ることが紹介されています。データウェアハウスに格納されたデータは、 データ分析において最も利用されるデータなので、 適切なアクセスコントロールと使いやすいユーザーインターフェースが必要であると書かれています。」
本書では
- 土川
- 「データ収集がなぜ難しいかというと、
データソースの種類や、 格納されているのがストレージなのかデータベースなのかによって、 データ転送に使う技術やツールが異なるうえ、 データに個人情報が含まれるかを考慮する必要があります。アプリ側からデータベースを参照している場合は、 データ転送時にはデータベースに負荷をかけないようにする必要もあります。」

続いて、
- 土川
- 「先ほどの図ではデータソースをそのままデータレイクに収集して、
それをデータウェアハウスに加工して格納する処理が書かれていました。一部のツールではフェデレーションと呼ばれる機能を使って、 データソースに対して直接クエリを書きつつ、 それを格納しているデータウェアハウスでもクエリを書いて、 それらを結合して、 またそのデータウェアハウスに保存できます。これによってパイプラインを1つ省略できます。問題点として、 負荷をかけてはいけないデータソースに負荷がかかってしまう、 ユーザによってデータソースにかかる負荷が変わるので管理しにくいことなどが挙げられています」
これに続いて、
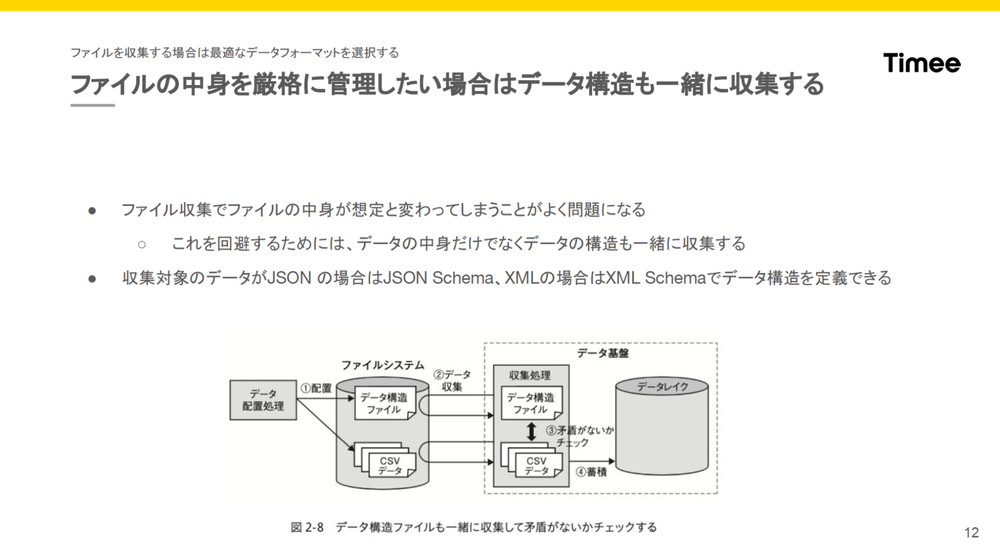
- 土川
- 「ファイルを収集するときに問題になるのは、
ファイルの中身が途中から変わってしまって、 データの途中で収集パイプラインが落ちてしまうことや、 データの利用者がデータの中身を把握できないことなどが挙げられています。これを回避するために、 データの構造ファイルを一緒に収集して管理する方法が書かれていました。」
ファイル収集での問題についてこのように説明し、
- 土川
- 「JSON SchemaやXML Schemaといったデータ構造を定義できます。”
この収集パイプラインではこのスキーマでデータを収集する” のように固定のスキーマを定義できます。 - 弊社ではBigQueryにデータを収集するのですが、
EmbulkによるBigQueryのインサートの方式に append directという設定があります。append directは、スキーマが追加されると同時にスキーマを自動追加してくれて、 既存のデータは nullで埋めてくれます。これによってスキーマの増減に対応して、自動で対応して収集しています。」
最後にAPIによるデータ収集について説明し、

- 土川
- 「APIの多くは実行回数制限があります。実行回数制限とは、
一定時間にAPIリクエストできる回数を制限するしくみで、 リクエストを制限することで、 API提供側のシステムにかかる負荷を抑える役割を持ちます。この制限がかかると、 データ収集が途中で止まるので、 事前にAPI実行回数を見積もって、 足りないようであればAPIの運用会社に相談することが必要です。弊社では、 HubSpotというCRMツールを使っていますが、 HubSpot APIは社内のいろいろなアプリから叩かれ、 データ分析用途でも叩いています。データ分析チームだけではなく、 全体から見てどのように負荷がかかっているかを考える必要があります。」
発表を終えたあとの質疑では、

na0(@na0fu3y)
新卒でソフトウェアエンジニアリングを担当、
- na0
- 「Cloud SQLの環境に入らなくても、
BigQueryの方にIAMで権限を振り分けておけば、 権限を持つ人がよしなに本番環境を構築できるというデバッグ用途で使っていましたね。 - あとはトランザクショナルな要件があるときに、
各テーブル同士の時間断面ってぴったり揃わないことがあるんですよね。そのような時間断面を揃えたデータをどうしても取ってきたいときにフェデェレーテッドクエリを使ったりしていました。」
最後に土川氏から著者の渡部徹太郎氏に質問がありました。
- 土川
- 「定期更新をしていると、
データの構造の変化が課題になりますが、 わたしの認識では各社対応がバラバラだと思います。弊社では最初、 スキーマが変わってデータレイク側と違うことが分かったら、 その通知をSlackに飛ばしていました。対応としては、 EC2でスキーマ定義をインスタンスの中から変更するような工数がかかる方法でした。このあたり良い知見がないか気になっています。」
- 渡部
- 「Netflix社の事例でいうと、
データソース側がどれだけ分析側に協力的かによります。Netflixはデータソース側がすごく分析に協力的で、 社内にデータ構造を管理する巨大なシステムがあって、 そこにいったんリリースする前に入れるそうです。データ収集側はそれを取るタイミングで確認するそうです。 - データドリブンな会社では、
データを入れる側が教えてくれるんですよ。でも、 大体の企業はそうではなくて、 取りにいったときに失敗してますよね。ちょっと進んでる会社だと変更を教えてもらって、 失敗する前に対応します。」
- 土川
- 「なるほど、
それはいいですね。弊社ではデータ構造を管理する場所がありませんでした。Ruby on Railsを使っていて、 そのマイグレーションファイルに変更があったときにSlackで通知して、 どこが変わったかを早めに検知できるようにしていました。」
- 渡部
- 「前職だとテーブル構造が変わる場合に必ずチケットが登録されるんです。そのチケットを見る運用もあるし、
テーブル定義書のExcelをパースするとか。みんなあの手この手って感じですね。」

渡部徹太郎(@fetarodc)
東京工業大学大学院 情報理工学研究科にてデータ工学を研究。株式会社野村総合研究所にて大手証券会社向けのシステム基盤を担当し、
データベースからデータ収集をするときのコツ
2人目の発表者は、

小野広顕(@hihihiroro)
某Web会社でデータエンジニアとしてBigQueryを中心としたデータ基盤おじさん。
データ基盤にデータを入れるだけではなく、
- 第2章データ基盤システムのつくり方
- 2-5 SQLを利用したデータベース収集ではデータベースへの負荷を意識する
- 2-6 データベースの負荷を考慮したデータ収集では、
エクスポートやダンプファイル活用を視野に入れる - 2-7 更新ログ経由のデータベース収集はデータベースの負荷を最小限にしてリアルタイムに収集できる
- 2-8 各データベースの収集の特徴と置かれた状況を理解して使い分ける
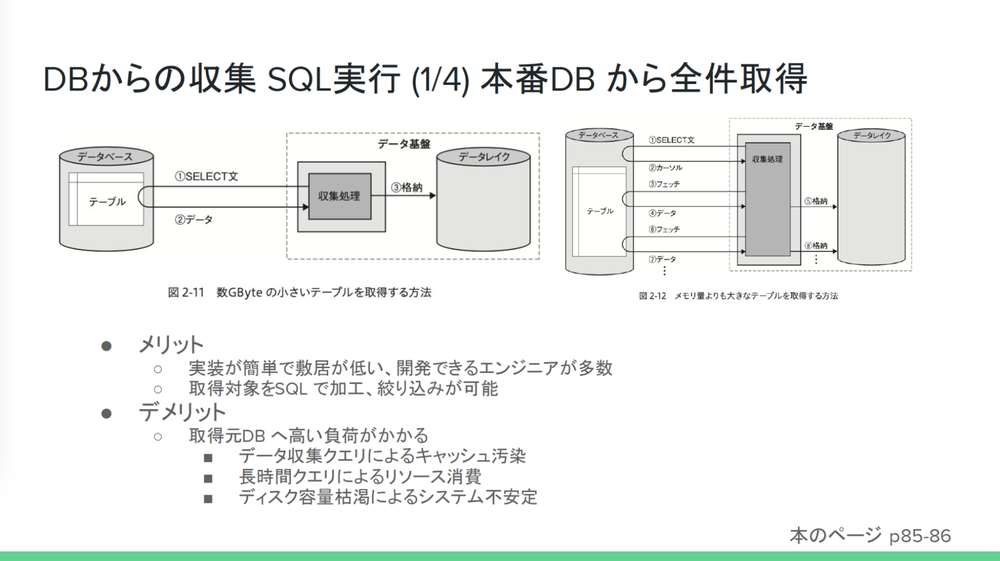
まずSQL実行には4つの方法があると話し、
- 小野
- 「取得対象に対してSQL を使用して取得するため、
マスク化やWHERE句での絞り込みなどができることもメリットとして紹介されていました。デメリットとしては、 SELECT文の書き方によっては高い負荷がかかることや、 データ収集クエリによるキャッシュ汚染、 SELECT文のクエリによる長時間クエリのリソース消費、 ディスク容量枯渇によるシステムの不安定化などが紹介されています。」
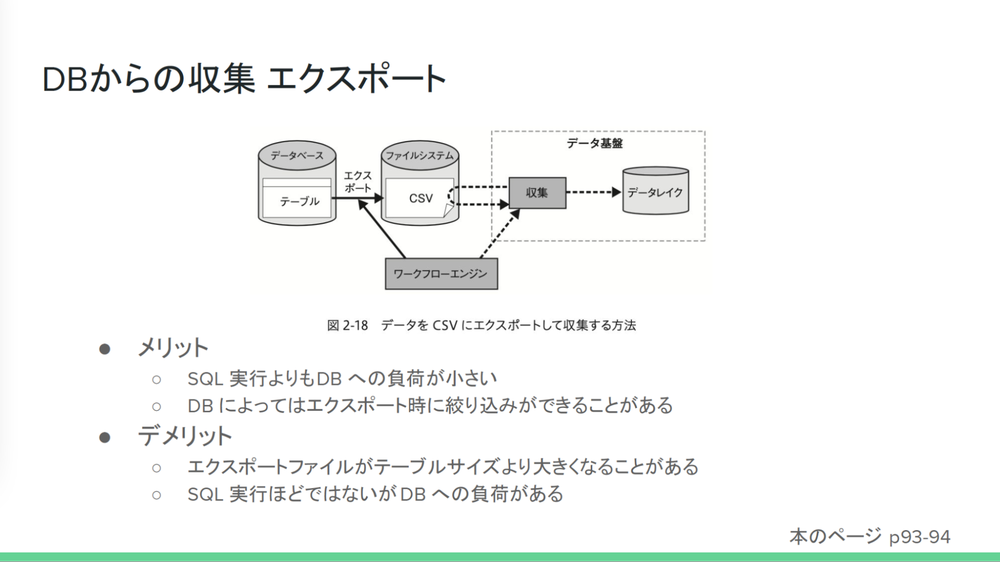
全件取得する方法以外にも、
- 小野
- 「ここでは2つの方法が紹介されています。1つ目がエクスポートファイルを取り込む方法です。SQL実行よりも負荷が小さいこと、
DBによってはエクスポート時に絞り込みができることがある。また、 データを小さくして、 出力時間を短くできると書かれていました。デメリットとして、 ファイルサイズがテーブルサイズより大きくなってしまう、 時間がかかることもありえることと、 SELECT文を投げるほどではないが、 DBには結局負荷がかかってしまうことが紹介されていました。」
ファイル出力によるデータ収集方法として、
- 小野
- 「まず更新ログを収集するというのは、
データ自体を取ってくるのではなく、 データに対して操作をしたログを取ってくる方法となります。メリットとしてはDBに対する負荷が小さいことと、 ログだけなのでデータ収集速度が速くなること、 小さいファイルなので必要帯域が少なく済むことが紹介されていました。デメリットとしては、 更新ログをそのまま読めることが少ないことが挙げられています。OracleのREDOログやSQLのバイナリログなどが紹介されてましたが、 専用の製品を使って復元する必要があり、 復元用DBの用意が必要になることがデメリットとして紹介されていました。」
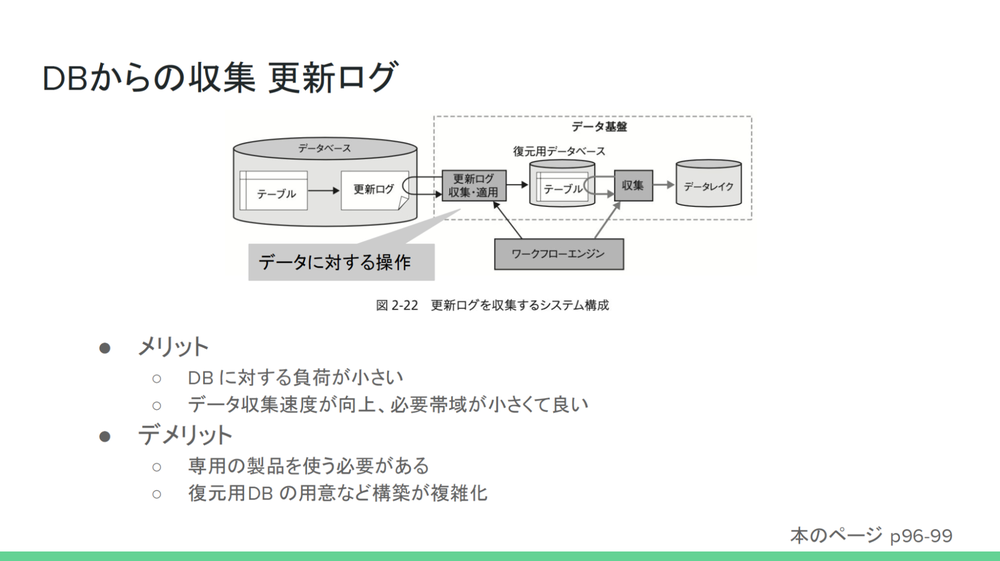
更新ログ収集のデメリットを改善するためにCDC
- 小野
- 「データベースからの収集方法として紹介されていたのは、
SQLを利用した収集、 ファイル出力の収集、 更新ログを利用した収集、 の大きく3つです。それぞれのメリット、 デメリットが記述されていて、 使い分けのコツとしては、 まず、 その取得元のDBの重要度、 サービスが実際に使われているかを考えます。サービスは朝しか使われていないから、 昼とか夜はSQL を自由に投げて取得できるということも考えられます。CDCツールとレプリカDBを立てるといった予算が潤沢にあるか。あとはリアルタイムでどうしてもデータが収集できないと分析ができないユースケースといった、 取得元DB の重要度、 予算、 ユースケースなどを組み合わせて考えることによって、 どの方法を選ぶか使い分けるのが良いと紹介されています。本書では、 レプリカDBを立ててSQL実行がお手軽でおすすめと紹介されていました。」

以上で発表は終わり、
- na0
- 「このデータ収集の方法の中で利用している例があれば、
ご紹介いただけますか?」 - 小野
- 「基本的にすべてSQLを使って収集しています。収集の際には、
時間帯を気にする、 WHERE句を付けて取得するデータの量を減らすといった方法はよく使います。それ以外では、ファイルで置いてもらう方法も多いです。エクスポートしてもらったファイルをS3に置いてもらいます。」
CDCツールを本番運用されている方がいないか参加者に聞いたところ
「DBの負荷が高く、
データ収集におけるクラウドサービスの活用
3人めの発表者は、

小池智哉(@k01ke_ya )
株式会社PLAIDでデータ分析・
- 第2章データ基盤システムのつくり方
- 2-9 ログ収集はエージェントのキャパシティに注意
- 2-10 端末データの収集は難易度が高いためできるだけ製品を利用し無理なら自作する
- 2-11 ETL製品を選ぶポイントは利用するコネクタの機能性とデバッグのしやすさ
- 2-12 データレイクでは収集したデータをなくさないようにする
ログにはWebサーバのアクセスログとアプリケーションのログがあると説明し、
- 小池
- 「図の左側にアプリケーションと書かれています。ログファイルの最終行にログを追記すると、
ログファイルを監視しているログ収集エージェントがプロセスとして常駐していて、 追記されたことがわかったらバッファに溜め込んでいきます。ここでは一定時間や一定量といった設定によって、 データ基盤に送付します。最終的にはバッファから送られたデータをデータレイクに溜めることになります。このようにバッファ機構を持つことで、 ログ収集マネージャやデータ基盤の負荷を一定にできるというメリットがあります。注意点としては、 収集したログをなくしたり、 バッファがあふれてロストしたりしないように、 サイズの設計は運用しながら変えていく必要があると書かれています。」
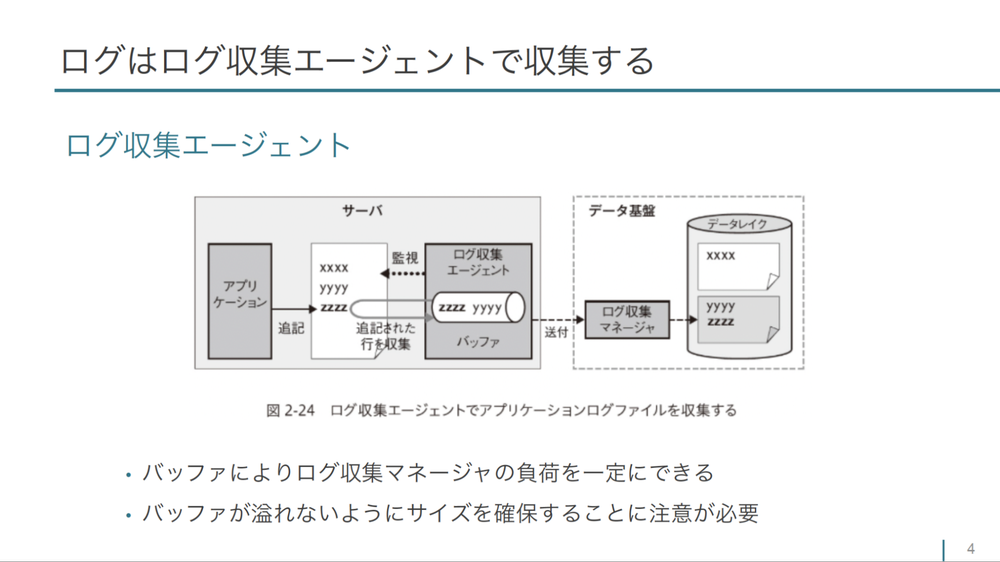
このあとログ収集を行うツールを紹介し、
- 小池
- 「代表的な端末データとして、
ブラウザイベントやスマホアプリのイベント、 IoTデバイスのデータなどがあると書かれています。ブラウザイベントとは、 画面のスクロールのようなユーザの行動データです。スマホアプリイベントも同様にユーザのクリックや、 スクロールといったデータですね。IoTのデバイスデータだと車載センサー、 生活環境センサ、 ウェアラブルデバイスのデータも含まれると思います。 - ブラウザイベントの活用例として、
「このボタン、 全然押されてないからなくそう」 といった、 ユーザの行動データを集めて、 それを分析してアプリケーションの改善につなげようとする取り組みが多くの会社で始まっています。また、 ブラウザイベントを分析するツールも紹介されています。」
ブラウザイベントやスマホアプリイベントを収集する具体的なツールを紹介したあと、
続いて、
- 小池
- 「ETL製品は、
インプットとなるデータソースと格納先の差分に対応するコネクタを提供しています。このコネクタの機能を重視して、 ETL製品を選ぶとということが書かれてまいます。」
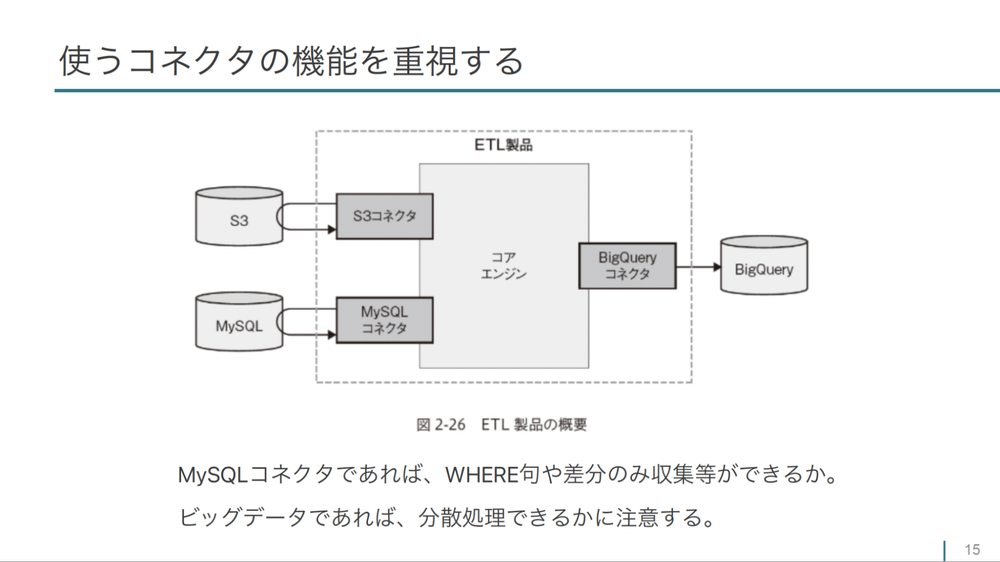
ETL製品の選定のポイントとして、
- 小池
- 「ETL商品を選ぶうえで、
もう1つ重要視する点として、 ソースコードのレベルでデバッグしやすいものを利用しましょうと書かれています。ETL製品を扱っていると、 文字コードや改行コード、 nullを期待してスキーマを作ったのに空文字列が入るなどのバグが起きます。あまり起きないバグだった場合、検索しても解決策が見つからないことがあります。そうなったときに、 ソースコードを見に行って、 何が起きているのかを調査できることが大事です。ETL製品とサポートに調査をしてもらえる場合は、 自分たちが作った基盤に実際に入ってもらえるなり、 データの加工をしておくなりするとデバッグが進みやすいと書かれています。 - 実際に同じようなことがありました。あるユーザから問い合わせがあり調査したところ、
ファイル名に記号やスペースなどの想定していない文字列が入っていました。他には某クラウドにデータをエクスポートすることがあったんですが、 クラウド側で提供しているSDKがシステム側での不具合で不定期に応答を返さないことがあって、 サポートに問い合わせても真相はわからないという例もありました。」
最後に、
- 小池
- 「データレイクには収集したデータを加工せずに格納しましょう。ファイルの形式や、
テーブルの構造をそのまま保存しましょう、 とこの本では一貫して書かれています。なぜかというと、 加工の途中で失敗してそのプロセスが落ちてしまいデータがなくなることを防ぐためです。 - 機密情報や個人情報はそのまま格納できないので、
匿名化を行う。また、 データレイクの要件として、 冗長化できて、 かつ容量が拡張しやすい製品を選ぶ、 と書かれています。最初から、 これぐらいまで容量が増えそうだから予約しておくというのは難しいので、 簡単に増やせるように工夫しておきましょうということですね。 - 具体例として、
ファイルはオブジェクトストレージに置くことがこの図で説明されています。ファイルシステムではデータをファイルという単位で階層化して扱いますが、 オブジェクトストレージはデータをオブジェクトという単位で扱います。」
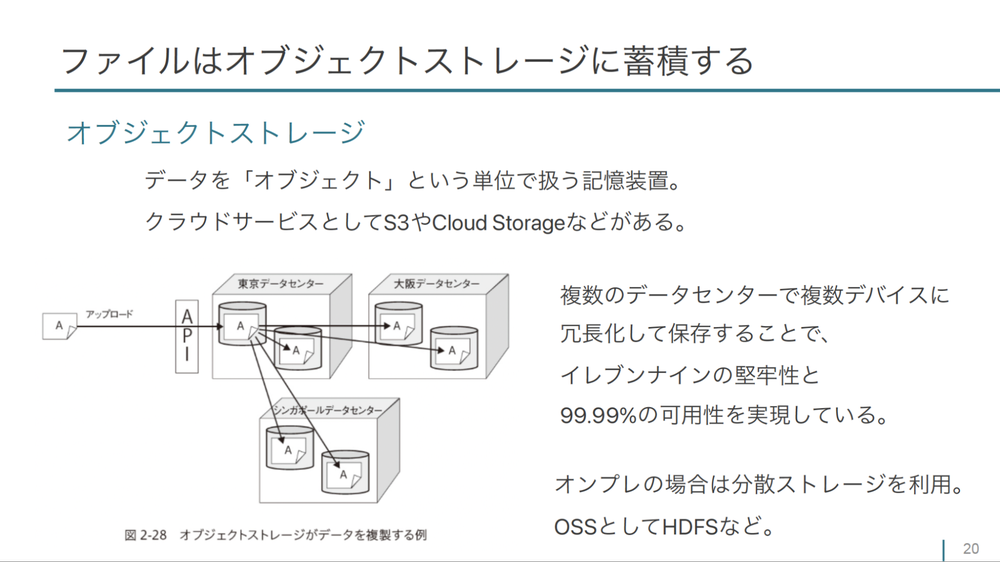
データクラウドサービスとして冗長化や堅牢性が求められるという説明をしたあと、
- 小池
- 「3つの理由があると書かれています。1つめは、
従量課金で利用できるので見積もりが甘くても大丈夫な点。2つめは耐久性が高くて冗長化もできている点。3つめは、 サーバー構成の冗長化が気にしなくて済むので運用の人件費が安くなるという点です。ただし、 オンプレミスからデータレイクにアップロードし続けるのは通信を用意するのに、 一定の費用がかかることが懸念として挙がっていました。」

以上で発表は終わりました。進行のna0氏がデータ収集やデータ転送に使用するツールについて参加者の利用状況を聞いたあと、
- na0
- 「ベンダーロックインが嫌で、
リアルタイムログキーを自作して運用がたいへんになったという経験があると山田雄さんのコメントにありました。」
- 山田雄
- 「Apache Kafkaで収集して、
Apache Sparkで集計して出力するシステムを作ったんですけど、 何か問題があったときにこれらをメンテナンスできるエンジニアがいないといけないという状態になりました。GCPのPub/ SubとDataflowに移行したら楽になりましたね。」
- 小池
- 「まさにGCPのマネージドが嬉しいという経験ですね。」
- 山田雄
- 「インフラ費用も高くなるんですよね。人件費も高いし、
インフラ費も高いみたいなこともあったりして。Sparkを使うと、 Apache Hadoopを立てる必要が出て、 それが高かったんです。そのときは、 EC2上にHadoopを立てました。」
- 渡部
- 「5年以上前、
Hadoopが流行ってた頃に 「今後はストリーム処理だ!」 って言って、 Spark StreamingとかApache Flinkが流行った時期があったんですよね。Hadoop自体も今あまり聞かないですし、 一時期のブームだったと思います。クラウドを利用していれば、 クラウドのマネージドサービスを使うと思いますね。」
最後に執筆者の渡部徹太郎氏から、
- 渡部
- 「書籍をご購入いただき、
また読んでいただいて本当にありがとうございます。みなさん読み込んでいることが感じられて嬉しい限りです。あと、 実は山田雄さんにはレビューにもご協力いただいて、 スペシャルサンクスにも書いてあります。本当にありがとうございました。この場を借りてあらためて感謝申し上げます。」