



「実践的データ基盤への処方箋」
- データエンジニア大集合!
「実践的データ基盤への処方箋」 輪読会レポート 〜データ整備編〜 (第1回) - データエンジニア大集合!
「実践的データ基盤への処方箋」 輪読会レポート ~データ基盤システム編~ (第2回) - データエンジニア大集合!
「実践的データ基盤への処方箋」 輪読会レポート 〜データ組織編〜 (今回)
2022年1月から2月にかけて、
データウェアハウス、ワークフローエンジンになぜそのツールを選ぶのか?
3回にわたって開催された輪読会の最終回です。1人目の発表者は某Web系会社に勤務する大澤氏です。現在はデータエンジニアとしてデータ基盤を構築していると話し、

大澤秀一(@ohsawa0515)
ウェブエンジニアとして携帯電話向けコンテンツサイトの開発・- 第2章 データ基盤システムのつくり方
- 2-13 データウェアハウスには抽出や集計に特化した分析用DBを採用する
- 2-14 分析用DBはクラウド上で使い勝手が良い製品を選ぶ
- 2-15 列指向圧縮を理解して分析用DBが苦手な処理をさせないように気をつける
- 2-16 処理の量や開発人数が増えてきたらワークフローエンジンの導入を検討する
- 2-17 ワークフローエンジンは
「専用」 か 「相乗り」 かをまず考える
まず、
- 大澤
- 「データ基盤のデータウェアハウスとしては、
分析用DBを採用をしてくださいと書かれています。オペレーショナルDBを採用してしまうと、 データ抽出や集計が遅くなって、 使いものにならないからコストが高くついてしまうことが挙げられています。オペレーショナルDBはデータ操作に特徴があります。例えば、 Webサイトのバックエンドに使用して、 ユーザが行ったデータの参照・ 更新・ 挿入・ 削除といった操作を行うことも得意です。また、 応答速度を重視しているので、 少量のデータを頻繁に操作することが求められていることが前提です。分析用DBは、 データの抽出や集計に強いという特徴があります。オペレーショナルDBのデータやCSVをバッチでロードしたのちに、 BIツールに抽出してレポート作成ジョブで全件集計するケースがあります。 - 分析用DBは応答速度よりもスループットを重視するところが特徴です。例としてはオペレーショナルDBにある売上テーブルを30分かけてロードして、
そのあと1時間かけて集計、 レポートを作るってところがユースケースとしてあります。データを列方向に格納することによって、 抽出や集計の計算に最適化をはかっています。」

分析用DBの提供形態についてふれ、
- 大澤
- 「データ基盤において、
分析用DBはもっとも重要なコンポーネントの一つです。処理性能やデータ基盤の利用者にとって使いやすいかという観点を考慮する必要があります。 - 分析用DBの選定の優先事項として、
初期コストの低さを優先すべきと書かれています。そこに関してはデータ基盤をいちから構築するにあたって、 どのぐらいシステム規模が必要になるかを推定することは不可能だと思います。」
次にクラウド上の分析DB製品の選び方について、
- 大澤
- 「どのクラウドの分析用DBを選ぶかの判断基準としては、
データソースがどのクラウドにあるかが考えられると書かれています。データソースと分析用DBと同じクラウドにあるメリットは2つあります。1つ目がネットワーク通信が同一クラウドで完結することで、 データ転送速度が速くなるのと、 データ転送料金がかからないという特徴があります。ただこれは同一リージョンの場合なので、 リージョンが異なると料金が発生します。2つ目がクラウドサービスが持つデータ転送や共有サービスの恩恵が受けられることです。クラウドによってはデータソースから分析用DBに簡単にデータ転送できるしくみが用意されてることが多いです。」

AWSでどの分析用DBを選択したらいいかについては、
- 大澤
- 「分析用DBはデータを列指向圧縮しているので、
データの一部だけを更新・ 削除するのは苦手です。例えば普通のオペレーショナルDBのように、 UPDATEを投げてしまうと、 パフォーマンスが落ちてしまいます。そういった場合は一度テーブルをDROPしてから再作成するのが正解です。 - なぜ苦手なのかというと、
列指向圧縮されたデータは列ごとに別々のファイルに格納されているため、 1つの行を更新するだけでも列の数だけファイルを更新する必要があるからと書かれています。」
分析用DBの特徴として、
- 大澤
- 「データ基盤におけるワークフローというのは、
まずデータ収集をして、 次にデータウェアハウスを生成して、 データマートを作成して、 そして最後にデータ活用に至るという一連の流れです。 - 主な機能としては起動時刻とか起動順序の制御です。例えば、
夜間バッチとして実行するときに、 1時に売上テーブルを収集して、 2時に商品の分類マスタテーブルを収集して、 それが両方終わった段階にデータマート層を作って、 最後BIツール取り込むというワークフローを、 ワークフローエンジンで定義することができます。」
ワークフローエンジンを使わない場合、

- 大澤
- 「代表的なワークフローエンジンは複数台のサーバで冗長構成できるので、
一台が止まってしまっても、 スケジューラ自体は止まることがないと説明されています。また、 一部の処理が異常終了した場合は途中からやり直すこともできます。処理の順序関係はグラフで見ることができるので、 全体の把握しやすさもメリットとして挙げられています。」
発表の最後はワークフローエンジン製品の選び方について説明しました。
- 大澤
- 「事業システムにワークフローエンジンが導入されてる場合があるので、
それに相乗りするかを第一に考える必要があると書かれていました。 - 相乗りのメリットとしては、
1つめがワークフローエンジンの実行環境を事業システムの人たちが運用管理していることです。2つめは事業システムの処理とデータ基盤の処理を1つのワークフローで制御できるので、 例えば前日の売上がしまったあとに、 そのまま同じワークフローの中で集計処理を実行できます。制御のしやすさや全体の把握しやすさがメリットとして挙げられています。 - デメリットの1つは、
事業システムに乗っかるので、 ワークフローを変えると事業システムに影響に及ぼすことがあり、 気軽に変更できない可能性があります。2つ目としては事業システムワークフローエンジン自体が頻繁にアップデートしないので、 レガシーすぎて使いにくい可能性もあります。」
このようにメリットとデメリットを説明し発表を終えました。
- 山田雄
- 「オペレーショナルDBと分析用DBで、
最近は機能が似通ってきていると思います。BigQueryも単発のクエリが速くなってきていますし、 オペレーショナルDBもデータ量を持てるようになってきてます。昔より使い分けは難しくなってきていますよね。」 - 大澤
- 「確かにそうですね。例えば、
本書に書いてありましたけど、 MySQLもPostgreSQLも使ったことはありませんが、 これらにも分析用のオプションがありますね。」
このあと、
- 山田雄
- 「ワークフローは常に話題になりますし、
どのツールが良いのでしょうか。やはりAirflowかDigdagが主流でしょうか。」 - 渡部
- 「AWSとGCPがマネージドサービスとして採用しているので、
選択肢は限られますよね。他にもいろいろありますが、 今回の書籍にはAirflowしか書けませんでした。」
"つまみ食い"でわかるデータ組織の成熟度
2人めの発表者は、

なかむらさとる
BigQueryと出会って腰を抜かしてしまい、- 第3章 データ基盤を支える組織
- 3-1 アセスメントによって組織の現状を客観的に把握する
- 3-2 組織の状況に合わせて組織構造を採用する
- 3-3 データ組織の成功に必要な要因を理解する
- 3-4 データ組織を構成する職種と採用戦略の基本を押さえる
まず、
- なかむら
- 「組織の課題やニーズに対して、
データで支援・ 解決できるかどうか。そもそもそれがないと進まないということが書かれていました。 - データが扱いやすいように整備されているかどうか、
データを活用するためにデータ基盤を開発しているか、 意思決定に活用できるようにダッシュボードやレポートを活用しているか。この三点を自分の会社に置き換えて考えてみると、 組織がどれだけデータ分析を重要視しているか、 見極めることができると書かれていました。」
データ活用の習熟度を測るアセスメントを紹介し、
- なかむら
- 「現状を客観的に評価して、
どのレベルにいるのか、 何が足りないのかを把握します。レベル1がデータ活用の初期段階で、 属人的にデータが活用されている。レベル2がデータ活用プロセスに最低限の統制がとられ、 再現可能である。3がデータ活用における基準も設け、 それが守られている。4がプロセスを数値化し、 モニタリング・ 管理できている。5がプロセス改善のゴールを数値化し、 それに向けた最適化に取り組んでいる。」

- なかむら
- 「わたしの解釈では、
データを使いたい人が勝手にどこかから取ってきて、 好き勝手に加工しているのがレベル1です。レベル2は、 IT部門がその都度頑張ってデータを出していて、 みんなが使うダッシュボードはあります。レベル3はデータを利用する部門でデータを好きに使っていい基盤ができあがっています。レベル4がデータの成り立ちも利用も監視できる状況で、 レベル5ではレベル4の状況を分析して課題を見つけて改善するサイクルができています。」
続いて、
- なかむら
- 「初期フェーズは集権型組織を採用します。いろいろなところからの依頼を一手に引き受ける組織を作ります。社内受託のような組織になりがちなので、
プロジェクトとして部門横断で人を集めると、 会社全体の動きがわかることが書かれています。実際には初期フェーズにいる会社が多いんじゃないかなと思いました。 - 中期フェーズは分権型組織です。各事業部にデータ活用組織のメンバーを配置します。各事業部でサイロ化してしまう可能性があるので、
社内勉強会を積極的に行って知見を共有すると書かれています。 - 成熟期はハイブリッド型組織です。データ基盤を作る部門が各事業部に人材を派遣することととらえました。」
このようにフェーズごとの組織体制を紹介したあと、
続いて、

- なかむら
- 「成功までのロードマップで進捗を評価するという箇所です。導入してユーザがハッピーになった、
で終わっているケースは自分自身を含めてよくあると思います。なんとなく便利になっているよねという、 なんとなくで終わってしまう。 - データ分析ツールの導入状況、
定期的な進捗評価、 データ活用が貢献しているものは何か、 業務プロセスのボトルネックや改善ポイント、 分析の品質、 データの品質。これらを確認すると、 成果が確かに見えてくると思います。例えば、 Google データポータルにGoogle Analyticsのタグを埋め込んで、 使っているかどうかをチェックできます。」
続いて、

- なかむら
- 「例えば、
採用戦略では、 ロードマップを書いて、 マイルストーンを決めて、 役割と必要な人数を検討しながら診断すると書かれています。 - あとは採用活動はリードタイムが長い可能性があると書かれています。確かにその通りで、
3ヶ月は当たり前で、 半年もありえるので、 リードタイムを加味してマイルストーンを決めることになるとと思います。」
発表を終えてなかむら氏は次のように語ります。
- なかむら
- 「本書で書いていることをすべて完了しないとデータ組織ができないかというと、
そうではなく、 組織の規模や状況にあわせて、 できる部分からつまみ食いすればいいと思います。 - 全体のロードマップがあって、
体系立てて進めることも近道なのかもしれませんが、 部分部分で現状に置き換えてみて、 今はできていないけど、 こういう道筋がありそうという読み方ができそうです。仮に会社にCDOがいないからって、 なんとかしてくださいって言ってもどうしようもないじゃないですか。」
なかむら氏はさらに感想を続けます。
- なかむら
- 「こう思い至ったのも、
最初に第3章を読んだときは 「どうしろっていうの......」 って感じだったんですけど、 2回、 3回、 4回と読んでいくと、 理解できたというか、 腹落ちして、 自分が今何をすればいいのかなとか、 どこから試せばいいのかな、 という感じで読めました。」 - 伊藤
- 「書籍のタイトルが処方箋なので、
もっと実践例を書きたかったんですが、 私の経験に閉じてしまうので、 教科書的に書くことを意識しました。ですので、 読者には教科書的な記述との差分を意識して欲しいと思います。本書をアセスメント的に使ってもらいたいという意味で、 最初にアセスメントを紹介しています。」 - なかむら
- 「おっしゃる通りですね。例えば新卒のエンジニアが読んで
「うちの会社、 何にもできてない」 のようにとらえるかもしれませんが、 逆にポジティブにとらえて、 「うちの会社何もできてないんだったら、 今からいろいろやってみよう」 のようにとらえてくれるといいと思います。データ基盤だけではなく、 仕事をするうえで何を用意したらいいのかと読めるところが多かったんで、 良い振り返りになりました。」 - 山田雄
- 「確かに、
アセスメントを使って、 自分の位置がどこなのか知るのは大事だと思いますし、 アセスメントをはじめているところも増えてきていると思います。」 - 伊藤
- 「本書の中でCTO協会が作成したDX Criteriaを紹介しています。これが取り組みやすいと思うので、
試してみてください。」 - なかむら
- 「フェーズの話も興味深かったです。自分の組織がどのフェーズか意識したことなかったんですが、
読んでみると、 確かに3つぐらいのフェーズをたどってきたのが思い出されました。」 - 伊藤
- 「データ人材は限られています。初期フェーズで集権型にするというのは、
限られた人材しかいないので、 一番価値を出せそうな体制ではじめる。そこから次のフェーズでは、 分権型を採用して、 専門的なメンバーを分散的に配置して組織全体でスケールしていきます。さらにその2つを組み合わせてハイブリッド型にしていくというストーリーですね。」
組織の作成には、
データセキュリティ推進のキーワード"Aim High,Shoot Low."
3人目の発表者は日本アイ・

久保俊平(@_bou_3 )
発言内容は完全に個人としてのものです。銀行系SIer、
- 第3章 データ基盤を支える組織
- 3-5 データ活用とセキュリティはトレードオフの関係にあることを理解する
- 3-6 組織の利益となるデータのセキュリティポリシーとそのセキュリティ基準を決める
- 3-7 適切な権限設定とリスク管理方法を定める
- 3-8 データ利用や権限管理などの運用ルールをドキュメント化する
- 3-9 担当、
見直しサイクル、 判断基準を決めてデータやツールの棚卸を定期的に行う - 3-10 不正アクセスに備えてデータ保護や匿名加工技術を適用する
- 3-11 監査では評価方法を理解して客観性を担保する
発表の最初に、
- 久保
- 「背景としてGDPRやCCPAとかCCPA、
カルフォルニア州の個人情報保護の条例といった個人情報保護に関する規制が施行されてきています。一方で、 個人情報の取り扱いの不備の事案もよくニュースになります。本書で語られているのが、 データ活用を重視しすぎるとセキュリティがおろそかになりがちだし、 逆にセキュリティを重視しすぎるとデータ活用が進みづらくなります。そのバランスを見極めて、 会社組織ごとにポリシー、 またはそれに基づくルールやツールを策定することが大事だと書かれています。」
そのうえでセキュリティには求められる要求が多いことについても説明しました。
- 久保
- 「注釈のリンクから情報セキュリティ管理基準というページ
[1] を見ると、 ここにマネジメント基準や管理策基準といったものがたくさん書かれていて、 非常にやることが多いとわかります。データ活用のニーズは、 具体的な要件がわかりやすいと思うんですが、 そればかりを見ているとセキュリティの見落としが発生しがちです。ですので、 セキュリティ側で意識すべきこととして、 セキュリティの施策を法規制やポリシーと照らし合わせて、 何か起きたらすぐに対応できる体制を作っておくことが大事です。活用の価値は見えやすいが、 セキュリティは見えにくい。」
久保氏はセキュリティとデータ利活用についてはさらに注意すべき点があると述べました。
- 久保
- 「セキュリティの努力とは、
保険のような感じだと思っていて、 なかなか役に立つ場面が見えにくいです。データ活用する部署とセキュリティの部署はだいたい異なるので、 利害の対立はありそうだなと思います。またデータ活用に柔軟な対応をしていく中で、 いろんなセキュリティに対する例外パターンが生まれてしまうと、 管理が煩雑になって運用的なセキュリティホールになって、 基準が守れなくなることがあると言われています。」
続いてセキュリティのポリシーと基準について説明しました。
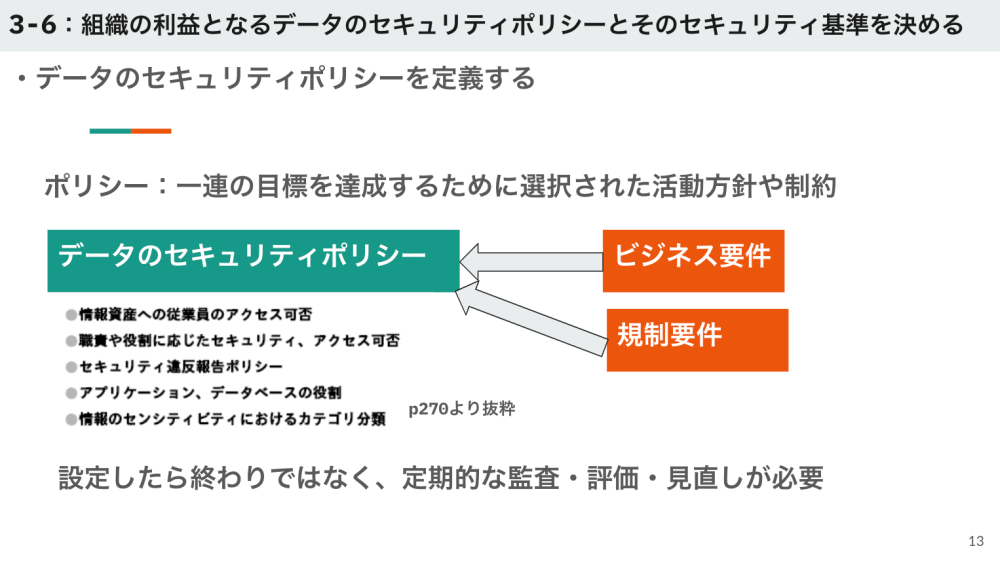
- 久保
- 「データのセキュリティポリシーは、
ビジネスの要件や規制要件からおのずと決まっていき、 その項目としては情報資産への従業員のアクセスの可否、 セキュリティ違反報告ポリシー、 アプリケーションの役割などと書かれています。」
続いて、

- 久保
- 「前職のときに、
ある先輩にドキュメントに仕事をさせろと言われて、 本書のこの記述はそれに通じるものがあると思いました。社内でデータを活用したいメンバーがどんな情報を必要とするのか。情報の場所、 種類、 アクセス権限、 承認フローやプロセス、 問い合わせ先などです。」
久保氏はデータの利用者が必要とする情報のドキュメントがあれば、

- 久保
- 「いま流行っているのでそれに関連して
「平家物語」 と書いたのは、 (発表当時、 アニメ版 「平家物語」 が放映中だった) 棚卸をしていくと、 かつては使われていたダッシュボードがだんだん使われていなくなるのがわかるという説明があり、 そこから発想しました。 - とはいえ、
滅びたダッシュボードも必要になることがあり、 復元の依頼もあるので、 アーカイブフォルダを準備すると書かれてます。」
おごれるデータソースも久しからず ただ春の夜のごとし
猛きダッシュボードもつひには滅びぬ ひとへに風の前の塵に同じ
と詠み、
- 久保
- 「データ保護に関しては個人情報保護法なども改定され続けており、
罰則もあるので、 データの暗号化などで漏洩時のリスクを最小化しましょう。そのためには匿名加工技術を使いましょうという解説があります。」
最後に、
- 久保
- 「目指すべき理想は高く、
やるべきことも多いんですが、 やり始めるにあたってはスモールスタートでやるしかないよね、 という感想を持ちました。私の前の前の会社の方が、 「Aim High,Shoot Low.」 という言葉をよく使われていました。目標は高く、 実行は手堅く、 という意味だそうです」 - 山田雄
- 「セキュリティとデータ活用がトレードオフということに関して、
最近はトレードオフではなく、 うまいこと両方できないか考えています。現在もいろいろなデータが見れるのですが、 使っていいのかわからないデータを関係部署に確認しながら使うということがあり、 これを 「あなたが使っていいデータしか見れないようになっています」 というセキュリティにできたら、 データ活用と両立できるのではと思います。」 - 久保
- 「使っていけないデータはルールから洗い出せると思うんですけど、
使いたいデータや活用できるデータが何なのかを判断するには、 膝詰めでの突き合わせが必要だと思います。」 - 伊藤
- 「アクセシビリティのグループ管理については、
ベストプラクティスとして紹介されている方法は採用しやすいんですが、 かゆいところに手が届かないことも多いですよね。例えば最近はBigQueryがカラム単位で制御できますよね。オーガナイゼーションやフォルダごとのアクセスなど、 いろいろな権限を誰に付与しようかなど。がんばればできるんですけど、 細かくするほどコストが発生します。本書では運用負荷をどう考えるのかまでは踏み込んで記述していません。」
権限の話題から、
- 伊藤
- 「自分の書いた文章がどう解釈されたのかよく伝わりました。わたし自身もすごく勉強になりました。ありがとうございました。」
datatech-jp、
輪読会を通して、
いまデータ基盤の構築に関わっている方にとって、
