


今回はVRAMの容量別でおすすめのローカルLLMのモデルを動作させる方法を紹介します。
ローカルLLM総集編
本連載では、幾度となくローカルLLMを紹介しています。
- 第849回 ローカルLLMの実行ツール
「Ollama」 のGUIフロントエンド、Alpacaを使用して生成AIを使用する [Radeon編] - 第860回 Ubuntu+Visual Studio Code+Ollamaでプログラムの相談をする
- 第866回 IPEX-LLMを使用してIntelの内蔵/外部GPUでOllamaを高速化する
- 第868回 UbuntuでAMD Radeon RX 9060 XTを使用する
- 第872回 百度
(Baidu) の新しいMoEモデルを、安価なGPUで動作させる - 第876回 夏休み特別企画 自作PCを組もう
[後編] ——組み立てたあとにローカルLLM 「gpt-oss-20b」 を動かす - 第877回 リアルタイム文字起こしをローカルマシンで実現できるWhisperLiveKitを使ってみよう
- 第880回 GPUに画像の文字を解析させる、あるいはPyTorch入門
- 第883回 Minisforum AI X1 PROでLLMを高速に動作させる
- 第891回 ミドルレンジのグラフィックボードで生成AI入門
- 第897回 GPUに画像の文字を解析させる、あるいはQwen3-VL入門
- 第902回 FirefoxのAIチャットボットをローカルLLMで使用する
- 第904回 ミドルレンジのグラフィックボードで生成AI入門
[Intel編]
昨年と今年の記事だけをピックアップしてもこれだけあります。第877回を除いて筆者が執筆しています。興味がOllamaからllama.
これは筆者がローカルLLMに対して強い興味を抱いているからですが、動かしていて面白いというのもあります。クラウドサービスはそもそもUbuntuかどうかは関係ないので本連載の対象外である、という点も大きいですが。
記事も多岐にわたるため、これまでに紹介したGPU、紹介しなかったGPUも含めて、GPUのメーカーとVRAMの容量別でおすすめのモデルの使い方をまとめます。いわば現時点の総集編です。
使用するPC
今回使用するPCの詳細は次のとおりです。
| メーカー | 型番 | 備考 | |
|---|---|---|---|
| CPU | AMD | Ryzen 7 5700X | |
| メモリー | Crucial | CT2K32G4DFD832A | 64GB |
| マザーボード | MSI | MPG B550I GAMING EDGE WIFI | |
| CPUファン | サイズ | SHURIKEN2 | |
| グラフィックボード | 本文参照 | 本文参照 | |
| SSD1 | MSI | SPATIUM S270 SATA 2. |
NVIDIA用 |
| SSD2 | KIOXIA | TC10480G02 | AMD用 |
| SSD3 | CFD | CSSD-S6L512MGAX | Intel用 |
| 電源ユニット | Silver Stone | SX700-PT | |
| 電源ユニットケーブル | Silver Stone | SST-PP05-E | |
| 電源ユニットマウンター | Silver Stone | SST-PP08B | |
| ケース | Silver Stone | SG13B |
Ubuntuのバージョンは24.
llama.cppの準備
LLMを動作させるのはllama.
NVIDIA CUDA
llama.
おおむね第891回のとおりですが、NVIDIAドライバーのバージョンは現時点で最新バージョンの590としています
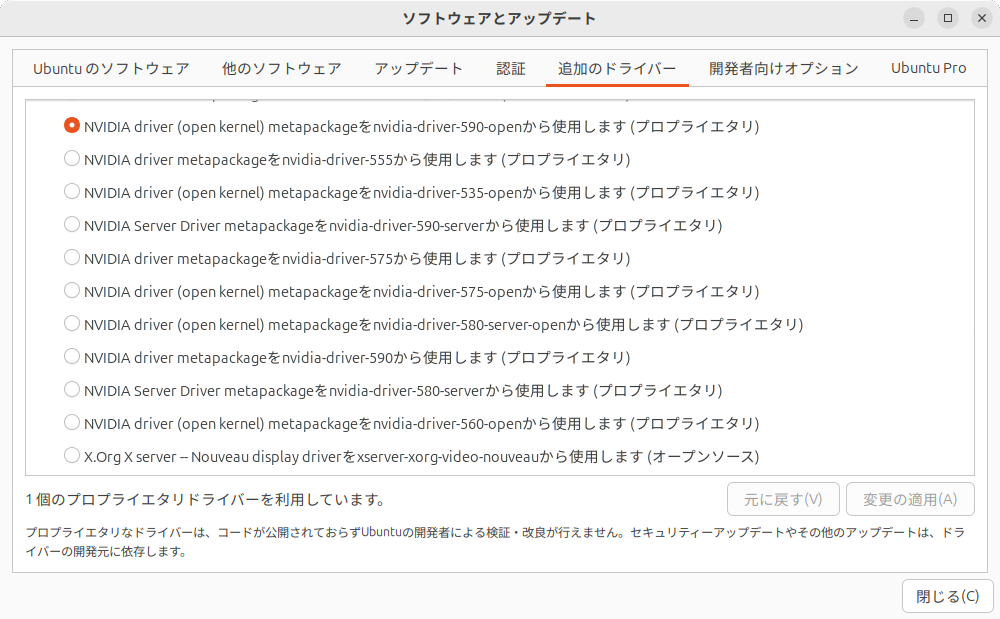
CUDAのバージョンも最新の13.
$ ~/Downloads/ $ wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb $ sudo apt install ./cuda-keyring_1.1-1_all.deb $ sudo apt update $ sudo apt install cuda-toolkit-13-2
nvidia-smiコマンドでは、なぜか13.
llama.
$ sudo apt install -y git git-lfs cmake g++ libcurlpp-dev $ mkdir ~/git $ cd ~/git $ git clone https://github.com/ggml-org/llama.cpp.git $ cd llama.cpp $ CUDACXX=/usr/local/cuda-13.2/bin/nvcc cmake -B build-cuda -DGGML_CUDA=ON $ cmake --build build-cuda --config Release -j 16
実際に実行するコマンドは今回の例だと~/git/以下にあります。
AMD ROCm
llama.
もちろんこれを使用してもいいのですが、llamacpp-rocmというAMDによる独自のllama.
複数のバイナリが用意されており、GPU毎に使用するものが異なるため、Supported Devicesを参考にダウンロードしてください。
ダウンロードしたバイナリをunzipコマンドで展開する場合、カレントフォルダーにファイルやフォルダーを展開してしまうので、事前にフォルダーを作成するなど気をつけてください。また実行ファイルに実行権限が付けられていないので、chmod +x llama-*を実行してください。
また重要な点として、実行前に次のコマンドで現在使用しているユーザーをrenderグループに所属させてください。
sudo usermod -a -G render $USER
実行後は再起動してください。
Intel oneAPI
第904回で紹介しているので、ここでは省略します。
Vulkan
速度はさておきllama.
VRAM6〜8GBのGPU
では具体的なVRAM容量別での使い方を紹介します。
使用するモデル
VRAMが6〜8GBのグラフィックボードで動作するおすすめのモデルは、Qwen3.
またQwen3.
コマンドの実行例は次のとおりです。まずはInstructから。
$ ./build-cuda/bin/llama-server --model ~/Downloads/Qwen3.5-9B-Q4_K_M.gguf --ctx-size 16384 --temp 0.6 --top-p 0.95 --top-k 20 --min-p 0.00 --port 8080
Thinkingにするには、このコマンドを実行します。
$ ./build-cuda/bin/llama-server --model ~/Downloads/Qwen3.5-9B-Q4_K_M.gguf --ctx-size 16384 --temp 0.6 --top-p 0.95 --top-k 20 --min-p 0.00 --port 8080 --reasoning on
使用するGPU
ここで使用するGPUは次のとおりです。
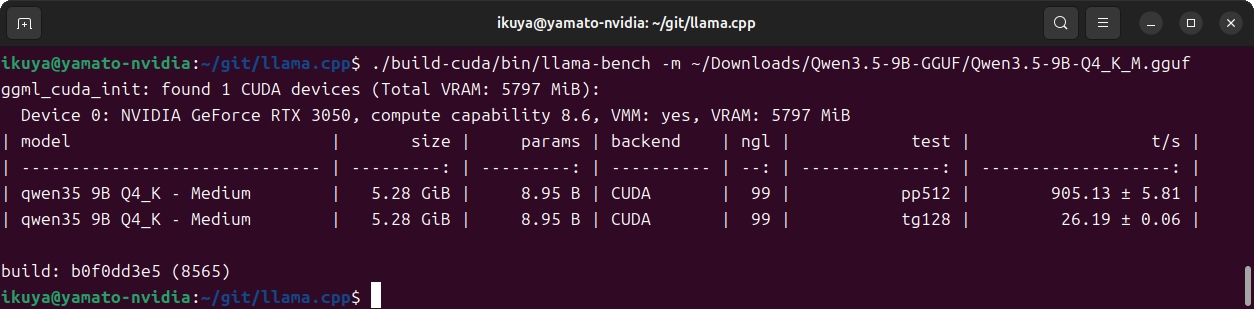
NVIDIA GeForce RTX 3050
第876回で使用したGeForce RTX 3050 LP 6Gです。この頃は25000円程度で購入できたのですが、今は1万円くらい上がっているようで、正直今から買うならもう少し出してGeForce RTX 5050のほうがいいような気はします。
ベンチマークの結果は図3とおりです。
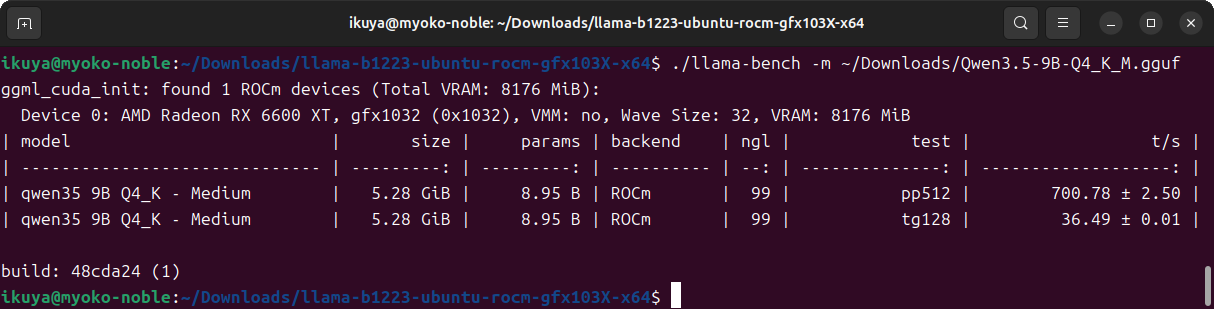
AMD Radeon 6600 XT
AMD Radeon 6600 XTは廃番になって久しいですが、7600や9060のVRAM 8GBモデルと見立ててください。
llamacpp-rocmのSupported Devicesによると、Radeon 6000シリーズはgfx103Xということなので、
あとは前述のとおりに展開し、実行できる状態にしてください。
ベンチマークの結果は図4のとおりです。
VRAM12GBのGPU
使用するモデル
VRAMが12GBのグラフィックボードで動作するおすすめのモデルは、第902回で紹介したgpt-oss-20bです。またその派生版であるGPT-OSS Swallow 20bでもいいでしょう。
ダウンロード元や起動時のオプションは第902回をご覧ください。とはいえVRAMが16GB前提のオプションで、12GBではコンテキストサイズを減らす必要がありました。
$ ./llama-server -m ~/Downloads/gpt-oss-20b-mxfp4.gguf --threads -1 --ctx-size 8192 --jinja -ngl 99 --flash-attn on --port 8080 --temp 1.0 --top-p 1.0 --top-k 0.0 --no-mmap --fit on --no-warmup
使用するGPU
NVIDIA GeForce RTX 3060
第817回で使用したGeForce RTX 3060 AERO ITX 12G OCはVRAMが12GBあるので、2世代前のモデルであってもまだまだ活用できる機会があります。
ベンチマークの結果は図5のとおりです。
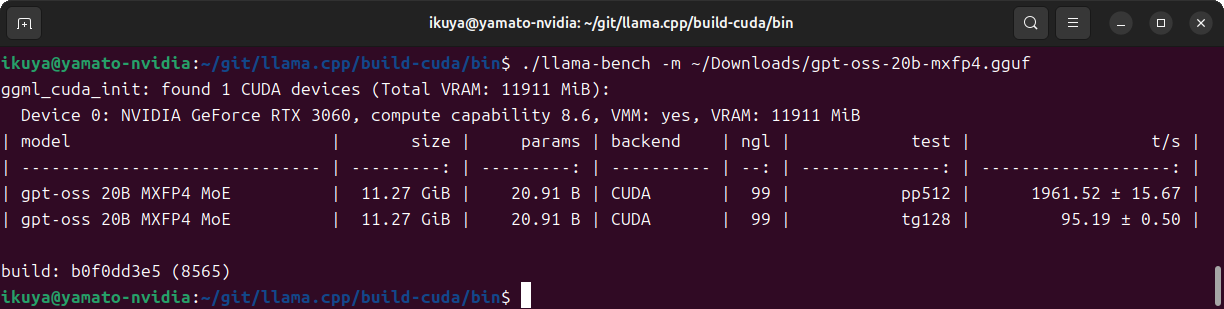
Intel Arc B860
第904回で紹介したばかりなので、詳細は省略します。
参考のため、Vulkanでのベンチマーク結果を図6に掲載します。
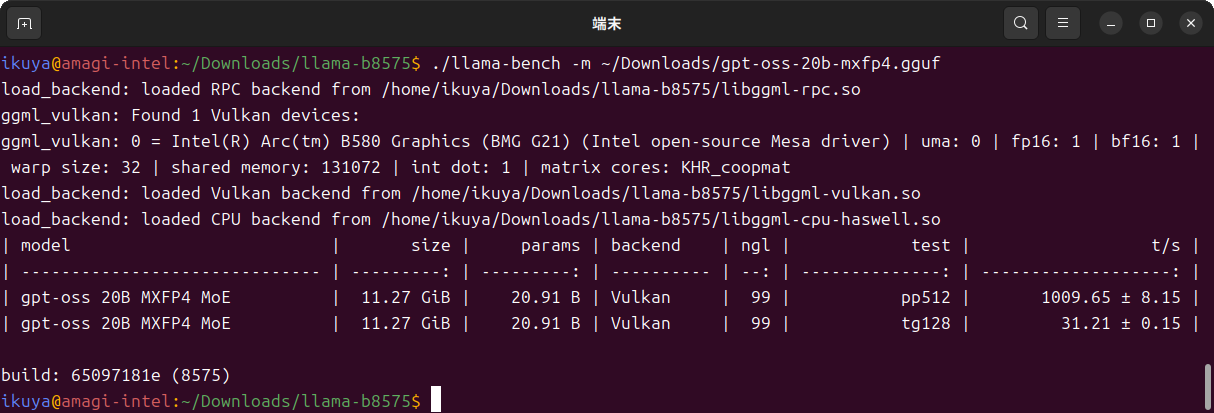
VRAM16GBのGPU
使用するモデル
Qwen 3.
また27Bは比較的重いモデルで、VRAMが16GBのミドルローのグラフィックボードには若干荷が重いです。筆者のメインPCではRadeon RX 7800 XTを使用しており、このクラスだと快適に動作しています。速度よりも精度を重視してモデルを選択しているということをご承知おきください。
実行例は次のとおりです。
$ ./llama-server -m ~/Downloads/Qwen3.5-27B-Q3_K_M.gguf --threads -1 --ctx-size 16768 --port 8080 --temp 0.7 --top-p 0.8 --top-k 20 --min-p 0.00 --presence_penalty 1.0 --no-warmup --no-mmap --fit on
使用するGPU
NVIDIA GeForce RTX 5060 Ti
第891回で紹介した、GeForce RTX 5060 Ti 16G VENTUS 2X OC PLUSを使用します。
ベンチマークの結果は図7のとおりです。
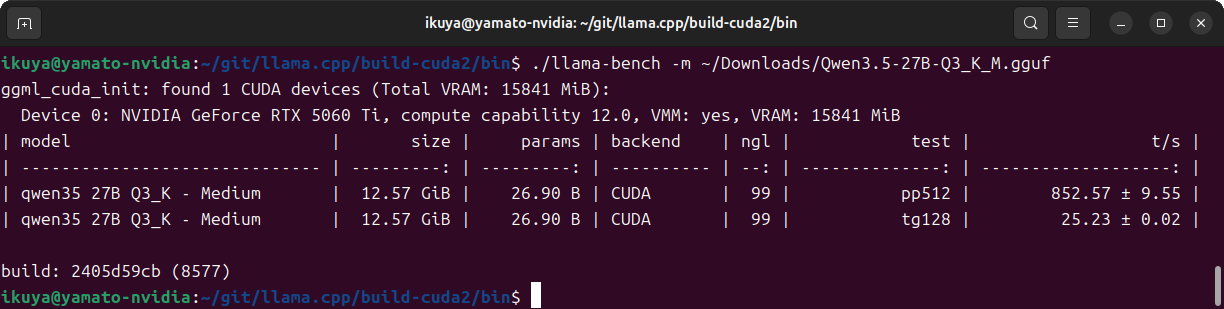
AMD Radeon RX 9060 XT
第868回と第891回で紹介したRD-RX9060XT-E16GB/
llamacpp-rocmのSupported Devicesによると、Radeon 6000シリーズはgfx120Xということなので、
あとは前述のとおりに展開し、実行できる状態にしてください。
ベンチマークの結果は図8のとおりです。
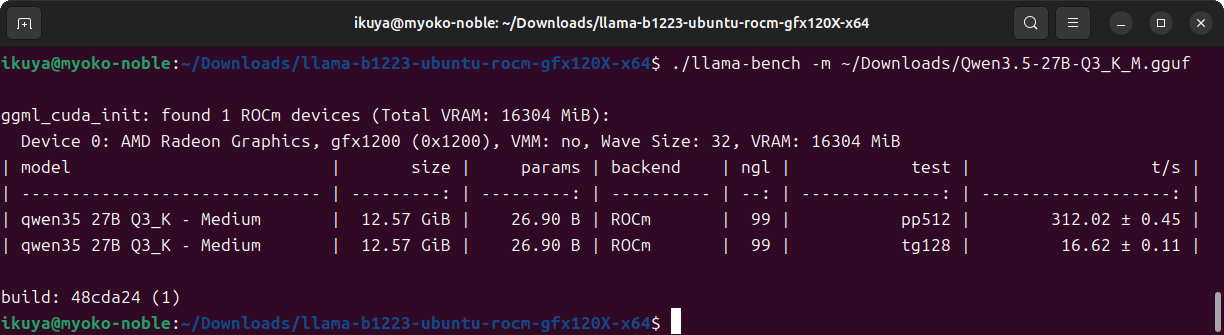
llama-serverの接続先
今回の例では、llama-serverはポート8080で接続できるようにしています。もし変更したい場合は、
また接続元もlocalhostに限定しています。どこからでも接続できるようにしたい場合は、